2v2ゲームのためのデータ駆動型Eloレーティングシステムの作成方法
2v2ゲームのEloレーティングシステムの作成方法
数学をテーブルに置く:アルゴリズムからフーズボール狂乱まで、究極のオフィスチャンピオンを求めて。
こんにちは、ようこそ!
私の名前はLazareで、私はビジネスデータ分析の学士号を取得しました。この記事は、学士論文のために行った研究に基づいています。
フレンドリーマッチから激しい競争まで、フーズボールは法人文化でそのニッチを見つけ、チームがつながり、競い合うユニークな方法を提供しています。
この記事では、フーズボールや他の2対2のゲームに適用できる2対2のEloベースのスコアリングシステムの数学について探求します。また、データ処理をサポートするアーキテクチャを検討し、Pythonを使用してリアルタイムのランキングとデータ分析を提供するWebアプリケーションの作成を紹介します。
- 医療における臨床家と言語モデルのギャップを埋めるために:電子医療記録の指示に従うための臨床家によって作成されたデータセット、MedAlignに会いましょう
- 施設分散問題:混合整数計画モデル
- 「ワードエンベディング:より良い回答のためにチャットボットに文脈を与える」
Eloランキング
Eloレーティングシステムは、ゼロサムゲームにおけるプレイヤーの相対的なスキルレベルを決定するための方法です。最初はチェスのために開発されましたが、現在は野球、バスケットボール、様々なボードゲーム、eスポーツなど、さまざまなスポーツでの評価システムとして使用されています。
このシステムの有名な例の1つは、チェスで、Eloレーティングシステムが世界中のプレイヤーをランク付けするために使用されています。”チェスのモーツァルト”としても知られるマグヌス・カールセンは、2023年時点で2,853のレーティングを持ち、ゲームの非凡なスキルを示しています。
Eloレーティングの式は2つの部分から構成されています。まず、与えられたプレイヤーグループに対する予想される結果を計算し、次に試合結果と予想される結果に基づいてレーティング調整を決定します。
予想される結果の計算
以下のチェスの例を考えてみましょう。プレイヤーAとプレイヤーBのレーティングがそれぞれR𝖠とR𝖡である場合、プレイヤーAがプレイヤーBに対して期待されるスコアの式は次のようになります:
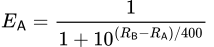
Eloアルゴリズムは、プレイヤーのレーティングによって勝率がどのように影響を受けるかを調整する変数を使用します。この例では、一般的なチェスを含むほとんどのスポーツで使用される400に設定されています。
では、より現実的な例を見てみましょう。プレイヤーAのレーティングが1,500であり、プレイヤーBのレーティングが1,200の場合です。
上記の式を使用して、プレイヤーAがプレイヤーBに対して期待されるスコアを計算できます:
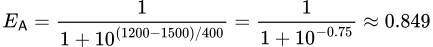
この計算により、プレイヤーAがプレイヤーBに対して84.9%の勝率を持つことがわかります。
プレイヤーBがプレイヤーAに対して勝つ確率を推定するためには、同じ式を使用しますが、レーティングの順序を逆にします:
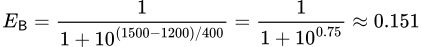
プレイヤーAが勝つ確率とプレイヤーBが勝つ確率の合計は1(0.849 + 0.151 = 1)になります。このシナリオでは、プレイヤーAは84.9%の勝率で勝ち、プレイヤーBはわずか15.1%の勝率となります。
レーティングの計算
勝者と敗者のレーティングの差が、各ゲーム後の獲得または失ったポイントの合計を決定します。
- レーティングの高いプレイヤーが勝つ場合、彼らは勝利に対して少ないポイントを受け取り、敗北した相手はわずかなポイントを失います。
- 一方、下位のランクのプレイヤーが勝つ場合、この達成ははるかに重要視されるため、報酬が大きくなり、上位ランクの相手はそれに応じてペナルティを受けます。
Player AがPlayer Bと対戦した場合、新しいPlayer Aのレーティングを計算するための式は次のとおりです:
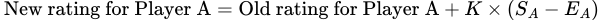
この式では、(S𝖠 – E𝖠)はPlayer Aの実際のスコアと予想スコアの差を表します。追加の変数Kは、1試合後にプレーヤーのレーティングがどれくらい変化できるかをおおよそ決定します。チェスでは、この変数は32に設定されます。
Player Aが勝利した場合、この場合の実際のスコアは1で、予想スコアである0.849よりも大きくなり、正の分散が生まれます。
これは、Player Aが最初に予想よりも良いパフォーマンスをしたことを示しています。その結果、Eloレーティングシステムは両プレーヤーのレーティングを再校正します:
- Player Aのレーティングは勝利により増加します
- Player Bのレーティングは敗北により減少します
再び、同じ方程式でPlayer AとPlayer Bの新しいレーティングを計算することができます:
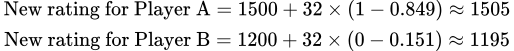
要約すると、Eloレーティングシステムは、プレーヤーのスキルを動的かつ公平に評価および比較するための堅牢で効率的な方法を提供します。このシステムは、2人の対戦相手のスキルの違いを考慮し、各試合後にプレーヤーのレーティングを継続的に更新します。
このアプローチはリスクを取ることを奨励します。高いレーティングのプレーヤーに勝利すると、プレーヤーのレーティングがより大幅に増加します。以下の表に示されているように:
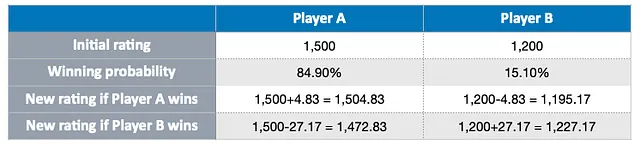
他方、高いレーティングのプレーヤーが勝率に反して低いレーティングのプレーヤーに敗北すると、そのレーティングは大幅に影響を受けます。より多くのポイントを失い、相手はより多くのポイントを獲得します。
要約すると、プレーヤーが試合に勝利した場合、勝率が低いほど獲得できるポイントが高くなります。
現在の状態では、チェス向けに設計されたこのレーティング式はフースボールに完全に適応されていません。
実際には、フースボールにはチェスよりも多くの変数があります。例えば:
- 2人のチームで行われる4人のプレーヤーゲームです
- 各チームメンバーは、チームメイトに良い影響または悪い影響を与えることができます
- チェスのような2進結果とは異なり、フースボールの勝利または敗北の幅はチームの得点によって大幅に異なる場合があります
レーティングアルゴリズムの探求
ここでは、4人のプレーヤーが2つのチームに分かれて行われるフースボールゲームの独特な要件にEloレーティングシステムを適応させることに焦点を当てています。
勝率
新しいプレーヤーレーティングを計算するためには、4人のプレーヤーが2つのチームに参加するゲームの結果を予測するための洗練された式を確立する必要があります。
これを示すために、仮想的な4人のフースボールゲームシナリオを考えてみましょう:Player 1、Player 2、Player 3、Player 4は、それぞれスキルレベルを表す異なるレーティングを持っています。

改訂されたEloレーティングシステムでは、Team 1とTeam 2の予想スコアを計算するために、ゲームに参加する各プレーヤーの予想レーティングを決定する必要があります。
Player 1の予想レーティング(E𝖯𝟣)は、Eloレーティングの式を使用して、各対戦相手のレーティングの合計を平均化することで計算することができます:
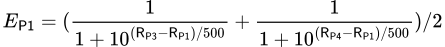
広範なテストの後、将来のスコアの公式において、チェスで使用される伝統的な値である400ではなく、評価差を分割するために使用される変数を500に設定することが適切であると判断されました。この増加した値は、プレーヤーのレーティングが予想されるスコアに与える影響を小さくします。
この調整の主な理由は、チェスとは異なり、フースボールにはわずかな要素の運があることです。値を500にすることで、試合の結果をより正確に予測し、信頼性のあるレーティングシステムを開発することができます。
プレーヤー1の予想スコア(E𝖯𝟤)を計算するために、プレーヤー1と同じ方法をプレーヤー2に対しても使用できます。プレーヤー3とプレーヤー4に対する予想スコアを計算するには、プレーヤー1と同じ方法を使用することができます。
チームの予想スコア(E𝖳𝟣)は、E𝖯𝟣とE𝖯𝟤の平均を取ることで計算することができます:

各プレーヤーの予想スコアが計算されたら、それらを使用して試合の結果を計算することができます。予想スコアが最も高いチームが勝つ可能性が高いです。各チームメンバーの予想スコアの平均を取ることにより、チーム内のスキルの差の問題を解決することができます!
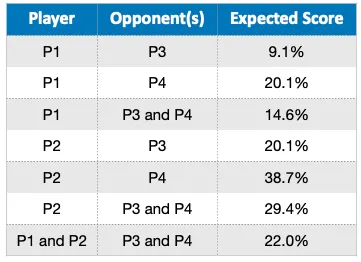
以下の表は、プレーヤー1と2がプレーヤー3と4に対して予想されるスコアを示しています。
- P1のP3とP4に対する予想スコアは0.091と0.201であり、勝つ可能性は14.6%です
- P2のP3とP4に対する予想スコアは0.201と0.387であり、合計の勝率は29.4%です
- P1の場合、P2のような強いプレーヤーとパートナーになることで、勝利の全体的な可能性が向上することが示されています(22%)
P1とP2のチームが勝った場合、P1は個別の予想スコアが示唆するよりも少ないポイントを獲得します。なぜなら、上位ランクのP2も勝利に貢献し、全体的な勝利確率を下げるからです。
一方、下位ランクのチームメートを持つP2はより多くのポイントを獲得します。勝利の場合、P2はリスクを取ったことに対して報酬を受け取りますが、P1はP2が勝利により重要な貢献をしたと想定されるため、ポイントが少なくなります。逆もまた同様です。
レーティングパラメータ
4人のプレーヤーの試合の予想結果が決まったので、この情報を試合とプレーヤーのレーティングに影響を与える複数の変数を考慮した新しい公式に組み込むことができます。
先に述べたように、K値はレーティングシステムのニーズにより良く合わせるために変更することができます。この新しい公式は、各プレーヤーのプレーしたゲームの数を考慮して、それぞれのゲームがレーティングに与える影響をバランスさせることができます。
たとえば、2014年のワールドカップ準決勝では、ドイツがブラジルに7-1で勝利しました。これはワールドカップの歴史でも最も衝撃的で屈辱的な結果の1つであり、ブラジルはホスト国であり、1975年以来、ホームでの競技試合で一度も負けたことがありませんでした。
この試合にレーティングシステムを適用すると、ドイツが大量のポイントを獲得し、ブラジルが大量のポイントを失い、パフォーマンスとスキルの差を反映します。
K値この場合、プレーヤー1のK値をK𝟣とし、1試合後のプレーヤーのレーティングの変化を決定します。この改訂されたK値は、各プレーヤーのプレーしたゲームの数を考慮して、各ゲームがレーティングに与える効果をバランスさせることができます。数多くのテストを行った結果、各プレーヤーのK値を計算するための公式が開発されました。
プレーヤー1の場合、以下のように表されます:
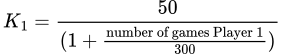
このK値の式は、新しいプレーヤーに対してはより大きな影響を与える一方、経験豊富なプレーヤーには安定性とレーティングの変動の少なさを提供するように設計されています。具体的には、300ゲームをプレイした後、プレーヤーのレーティングは彼らのスキルレベルをより代表するものになります。
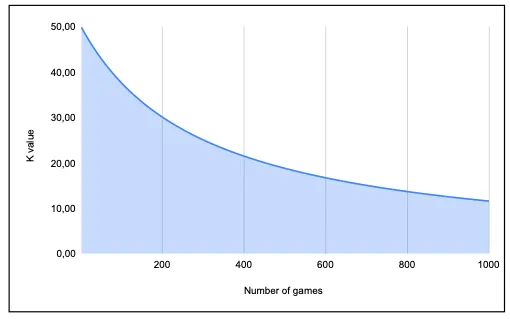
図IVは、プレイしたゲームの数がK値に与える影響を示しています。このグラフは、50から始まり、プレイしたゲームの数が増えるにつれてK値が減少し、300ゲーム後に半分の値である25になることを示しています。これにより、経験が増すにつれて各ゲームがプレーヤーのレーティングに与える影響が減少します。
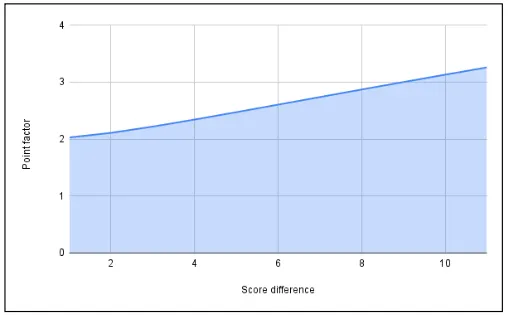
ポイントファクター各チームの得点を考慮するために、「ポイントファクター」と呼ばれる新しい変数が方程式に導入されました。このファクターは、各プレーヤーのKパラメーターを乗算し、2つのチーム間の得点の絶対値に基づいています。試合の影響は、チームが大差で勝利した場合、つまり圧倒的な勝利の場合には大きくなる必要があります。
ポイントファクターを計算するためには、次の式が使用されました:
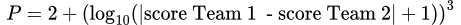
この式は、2つのチームの得点の絶対差を取り、1を加え、その結果の底10の対数を計算します。この値を3乗し、結果に2を加えることで、ポイントファクターの最終値を得ることができます。
最終レーティングの計算
必要な変数を調整した後、各プレーヤーの新しい順位を計算するために改良された式が開発されました。
各プレーヤーのレーティングは、以前のレーティング、対戦相手のレーティング、チームメイトの影響、プレイの履歴、および試合のスコアを考慮に入れています。この式により、各プレーヤーは真のパフォーマンスに基づいて報酬を受け取り、各試合の公平性も考慮されます。
前の例に基づいて、プレーヤーAの順位の新しい式は次の通りです:
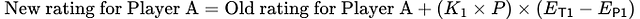
この改良された式は、実際のパフォーマンスに基づいてプレーヤーに報酬を与え、リスクを取ることを奨励し、新人と経験豊富なプレーヤーのためによりバランスの取れたレーティングシステムを提供します。
これでEloアルゴリズムができたので、次はデータベースモデリングに移ります。
データベースの設計とモデリング
提案されたデータベースモデルは、リレーショナルなアプローチを採用し、主キー(PK)と外部キー(FK)を使用してデータを相互に接続されたテーブルに組織化します。この構造化された組織は、データの管理と分析を容易にし、データベース管理システムとしてPostgreSQLを適切な選択肢とします。PKとFKは、データの一貫性を維持し、データベース内の冗長性を最小限に抑えるのに役立ちます。
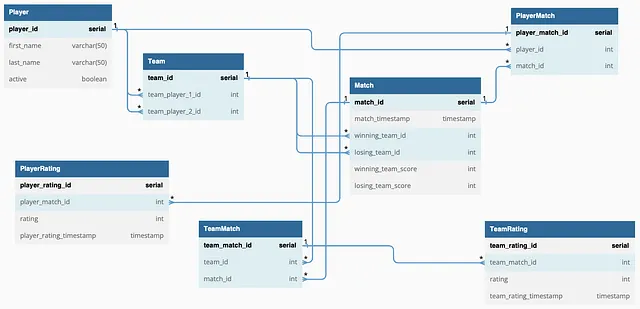
このデータベースモデルでは、テーブル間には1対多の関係と多対多の関係の2種類の関係が存在します。
「Player」テーブルと「Match」テーブルの関係は多対多であり、1人のプレーヤーが多数の試合に参加することができ、1つの試合に複数のプレーヤーが関与することができます。この関係を橋渡しする「PlayerMatch」というジャンクションテーブルがあり、2つの外部キー「player_id」(参加プレーヤーを参照)と「match_id」(対応する試合を参照)が含まれています。
以下のコードで示されるように、この構造はプレーヤーと試合の正確な関連付けを保証します:
CREATE TABLE PlayerMatch (player_match_id serial PRIMARY KEY,player_id INT NOT NULL REFERENCES Player(player_id),match_id INT NOT NULL REFERENCES Match(match_id));同様のロジックは「TeamMatch」テーブルにも適用され、これは「Match」テーブルと「Team」テーブルの間の連結役割を果たし、複数のチームが1試合に参加し、1試合に複数のチームが関与することを可能にします。
「PlayerRating」および「TeamRating」のために別々のテーブルが設計され、時間経過にわたる順位分析を効率化しています。これらのテーブルはそれぞれ「player_match_id」および「team_match_id」を介して「PlayerMatch」および「TeamMatch」テーブルに接続されます。
データの整合性
PKとFKの使用に加えて、このデータベースモデルではデータの整合性のために適切なデータ型とCHECK制約も使用しています:
- 「winning_team_score」および「losing_team_score」カラムは「Match」テーブルで整数型であり、数値以外の値を防止します。
- CHECK制約により、「winning_team_score」は11であることが強制されます。
- CHECK制約により、「losing_team_score」は0から10の範囲内であることが強制され、ゲームのルールに従います。
以下のコードチャンクに示されるように、各主キーに対してシーケンスの使用がデータベース作成に実装されており、データ入力を容易にするための自動化が行われています。この自動化により、後でPythonループを使用してデータ入力プロセスを簡略化することができます。
CREATE SEQUENCE player_id_seq START 1;CREATE SEQUENCE team_id_seq START 1;CREATE SEQUENCE match_id_seq START 1;CREATE SEQUENCE player_match_id_seq START 1;CREATE SEQUENCE player_rating_id_seq START 1;CREATE SEQUENCE team_match_id_seq START 1;CREATE SEQUENCE team_rating_id_seq START 1;データ処理
主な課題は、データベースに挿入された最初のデータからIDを取得し、そのIDを使用して残りのデータを管理するための外部キーとして利用できるような処理順序を見つけることでした。
これらの特定のIDは、必要な関係性を作成するための橋渡しとして機能します。つまり、最初のステップは、生データから特定のデータ(ID)を識別して保存し、その後、これらのIDを使用して残りのデータをリンクして処理することです。
データは段階的に処理され、複雑になっていくPythonループが使用されました。新しいエントリは、テーブルのシーケンスから生成された一意の主キーが割り当てられました。
- 最初のステップは個々のプレーヤーを処理し、それらのIDを取得することでした。
- 次に、プレーヤーIDを使用してチームを処理しました。試合ごとのユニークなプレーヤーペアごとに、「Team」テーブルにエントリが作成されました(プレーヤーのFK)。
- これに続いて、勝利チームと敗北チームのIDを使用して試合を処理しました。試合の処理後、「PlayerMatch」テーブルと「TeamMatch」テーブルは、対応する試合、プレーヤー、およびチームのIDを取得して対応しました。
- 必要なデータがすべて処理されたら、「PlayerMatch」および「TeamMatch」のIDと「match」のタイムスタンプは、「PlayerRating」および「TeamRating」テーブルに使用され、順位の変遷を追跡します。
Webアプリケーション開発
Webアプリケーションの目的は、ユーザーがゲームの結果を入力し、データを検証し、データベースと直接やり取りできるようにすることです。これにより、データが常に最新でリアルタイムに提供されるため、ユーザーは常にランキングを参照したり、メトリクスを可視化したりすることができます。
さらに、Webアプリをモバイルフレンドリーにすることも目指しました。なぜなら、誰がラップトップを持ち歩いてフーズボールをするために移動したいと思うでしょうか?それは非常に実用的でも楽しいわけではありません。
テクノロジースタック
バックエンドPythonでウェブアプリケーションを構築するための2つの人気のあるウェブフレームワークであるDjangoとFlaskを比較した後、初心者にも使いやすいアプローチを持つFlaskが選ばれました。Flaskウェブフレームワークは、ユーザーのリクエストを処理し、データを処理し、PostgreSQLデータベースとやり取りするために使用されます。
フロントエンドフロントエンドは、静的なHTMLとCSSファイルで構成されており、ウェブアプリケーションの構造とスタイルを定義しています。JavaScriptはフォームの検証およびユーザーの操作を処理するために使用されます。これにより、ユーザーが送信するデータがバックエンドに送信される前に一貫性があり正確であることが保証されます。
データの可視化データの可視化において最も大きな課題は、最新のデータを持つことです。この制限を克服するために、データ可視化レイヤーではPythonのライブラリであるPlotlyを使用して、時間の経過に伴うプレーヤーの評価を視覚化するインタラクティブなチャートやグラフを生成します。このコンポーネントはバックエンドからデータを受け取り、処理してユーザーに使いやすい形式で表示します。
データベースPostgreSQLは、ローカル開発環境およびAWS上の本番環境の両方で使用されました(Herokuを介して)。Herokuによって自動的なデータベースのバックアップが容易に行われるため、データは保護され、必要な場合に簡単に復元することができます。
UI/UXリサーチ
UI/UXデザインには、Spotifyや新しいBing検索エンジンのモダンなウェブデザインからインスピレーションを得ています。目標は、馴染みのある直感的なユーザーエクスペリエンスを作成することです。
アプリケーションの特徴
具体的なシナリオでアプリケーションの特徴について詳しく見てみましょう。チーム1(MatthieuとGabriel)は、チーム2(WissamとMalik)と対戦したいと思っています。すべてのプレーヤーは、以下に表示されるスキルレベルを表す異なる評価を持っています。

勝率の計算
どの試合においても、プレーヤーはまず勝率を計算したいと思います。
そのため、「勝率の計算」ビューでは、ユーザーがドロップダウンメニューを使用して4人のプレーヤーを選択し、選択したチームの勝率を生成することができます。
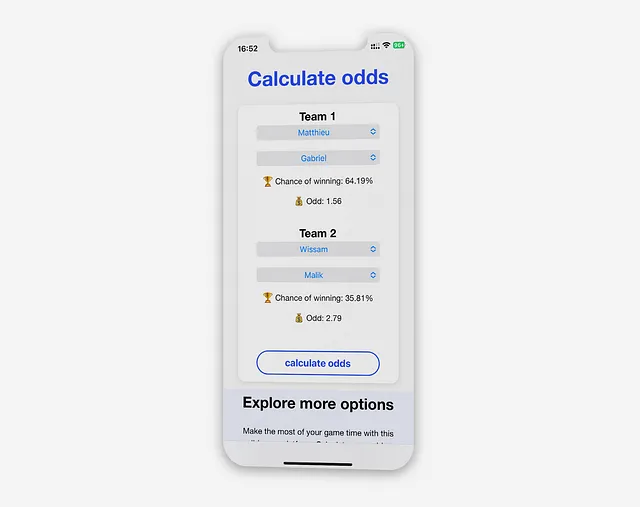
この機能は、主に試合前に使用され、試合がバランスが取れているかどうかを確認し、プレーヤーに勝率について通知します。例えば、チーム1は勝つ確率が高い(64.19%)ですが、チーム2は勝つ確率が35.81%です。このビューでは、各プレーヤーにステークとリスクを通知します。
フォームが送信されると、アプリケーションは選択された4人のプレーヤーに基づいてゲームの予測結果を計算するアルゴリズムの最初の部分のみを計算します。
ゲームのアップロード
「ゲームのアップロード」ビューは、アプリケーションのホームページとして機能します。これにより、ユーザーはアプリを開いた瞬間にゲームをアップロードすることができます。
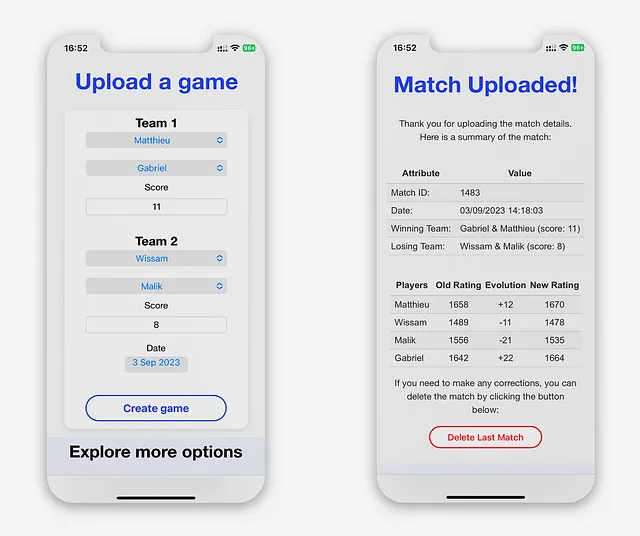
フォームが送信される前に、アプリケーションはJavaScriptを使用してデータのバリデーションを行い、以下のことを確認します:
- 異なる4人のプレーヤーが選択されている
- スコアは非負の整数である
- スコアが11であり、引き分けは許されず、勝利チームが1つだけである
バリデーションが成功すると、アプリケーションはデータを処理し、データベースの対応するテーブルを更新し、ユーザーにアップロードの確認を与えます。
「アップロードされたマッチの表示」は、各マッチが個々のレーティングに与える影響をユーザーに示すために設計されています。マッチのアップロード前後のプレイヤーのレーティングの差を計算します。
上記のように、ゲームは各プレイヤーのレーティングに同じ影響を与えません。これは、各プレイヤーのアルゴリズムの個別のパラメータ(予想スコア、プレイしたゲームの数、チームメイト、対戦相手のチームなど)のためです。
Eloランキング
「プレイヤーランキング」ビューでは、ユーザーはリアルタイムの月次ランキングにアクセスして、他のプレイヤーと比較することができます。ユーザーは自分のレーティング、月間のプレイしたゲームの数、最後にプレイしたゲームでの最新のレーティングを見ることができます。
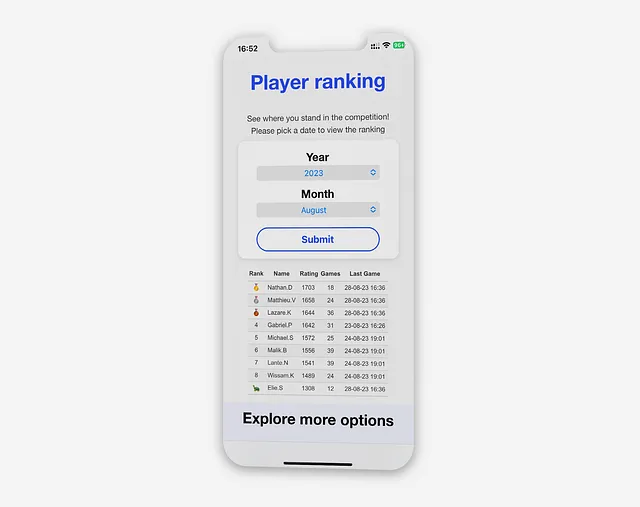
「プレイヤーランキング」ビューにアクセスするか、新しい期間が提出されると、アプリケーションはCTEアプローチを使用してデータベースをクエリします。
これには、必要なすべてのテーブルを結合し、期間セレクタを使用してクエリをフィルタリングして、最新のランキング更新を表示することが含まれます:
def get_latest_player_ratings(month=None, year=None): now = datetime.now() default_month = now.month default_year = now.year selected_year = int(year) if year else default_year selected_month = int(month) if month else default_month start_date = f'{selected_year}-{selected_month:02d}-01 00:00:00' end_date = f'{selected_year}-{selected_month:02d}-{get_last_day_of_month(selected_month, selected_year):02d} 23:59:59' query = ''' WITH max_player_rating_timestamp AS ( SELECT pm.player_id, MAX(pr.player_rating_timestamp) as max_timestamp FROM PlayerMatch pm JOIN PlayerRating pr ON pm.player_match_id = pr.player_match_id WHERE pr.player_rating_timestamp BETWEEN %s AND %s GROUP BY pm.player_id ), filtered_player_match AS ( SELECT pm.player_id, pm.match_id FROM PlayerMatch pm JOIN max_player_rating_timestamp mprt ON pm.player_id = mprt.player_id ), filtered_matches AS ( SELECT match_id FROM Match WHERE match_timestamp BETWEEN %s AND %s ) SELECT CONCAT(p.first_name, '.', SUBSTRING(p.last_name FROM 1 FOR 1)) as player_name, pr.rating, COUNT(DISTINCT fpm.match_id) as num_matches, pr.player_rating_timestamp FROM Player p JOIN max_player_rating_timestamp mprt ON p.player_id = mprt.player_id JOIN PlayerMatch pm ON p.player_id = pm.player_id JOIN PlayerRating pr ON pm.player_match_id = pr.player_match_id AND pr.player_rating_timestamp = mprt.max_timestamp JOIN filtered_player_match fpm ON p.player_id = fpm.player_id JOIN filtered_matches fm ON fpm.match_id = fm.match_id GROUP BY p.player_id, pr.rating, pr.player_rating_timestamp ORDER BY pr.rating DESC; '''データの可視化
この包括的なソリューションの開発の主な目標は、各プレイヤーのパフォーマンスを視覚的に表現するリアルタイムのランキングシステムをユーザーに提供することでした。
データの可視化にはPowerBIやQlikなどの強力なツールが利用できますが、ライセンス料を発生させずにデバイス上でリアルタイムの洞察を得ることができる、完全にモバイル対応のソリューションが選ばれました。
これを実現するために、次の2つの手法が使用されました:
- まず、Flaskアプリケーションの上にインタラクティブでデータ駆動型のアプリケーションを構築することができるPythonフレームワークであるDash Plotlyが使用されました
- 次に、データベースから情報を取得し表示するために、さまざまなSQLクエリと静的なHTMLページが使用され、ユーザーが常にリアルタイムのデータにアクセスできるようにしました
レーティングの進化
この可視化により、プレイヤーは各ゲームがランキングに与える影響を観察し、より大きなトレンドを特定することができます。たとえば、誰かに追い抜かれるタイミングを正確に見ることができたり、連勝や連敗の影響を見ることができます。
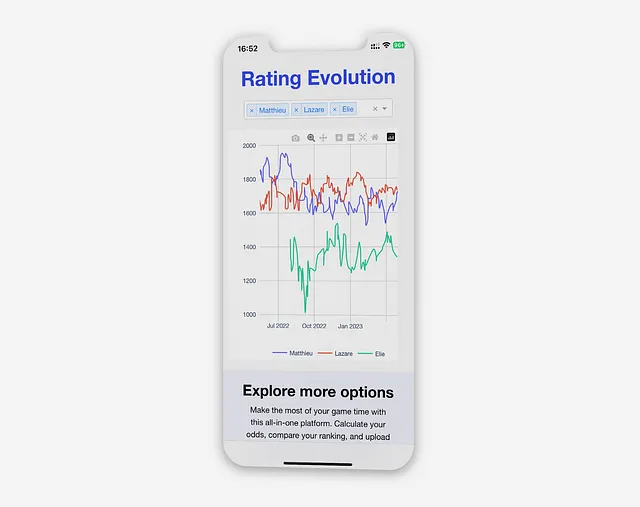
「Rating Evolution(レーティングの進化)」ビューにアクセスすると、アプリケーションは選択したプレイヤーごとにデータベース上でクエリを実行し、各日の試合の最新のランキング更新を取得します:
SELECT DISTINCT ON (DATE_TRUNC('day', m.match_timestamp)) DATE_TRUNC('day', m.match_timestamp) AS day_start, CASE WHEN p.first_name = '{player}' THEN pr.rating ELSE NULL END AS ratingFROM PlayerMatch pmJOIN Player p ON pm.player_id = p.player_idJOIN PlayerRating pr ON pm.player_match_id = pr.player_match_idJOIN Match m ON pm.match_id = m.match_idWHERE p.first_name = '{player}'ORDER BY DATE_TRUNC('day', m.match_timestamp) DESC, m.match_timestamp DESC取得したデータテーブルは、Dashを使用して列を軸に変換して折れ線グラフに変換されます。
データベースの負荷を軽減し、グラフでのデータの表示を簡素化するために、各日について最新のランキング更新のみが表示されます。
プレイヤーメトリクス
Spotify Wrappedに触発され、定常的なデータ収集から派生した洞察を提供することを目的としています。プレイヤーの洞察を視覚化するための膨大なポテンシャルがある中、個々のパフォーマンスとプレイヤー間の関係を強調するメトリクスに焦点を当てています。
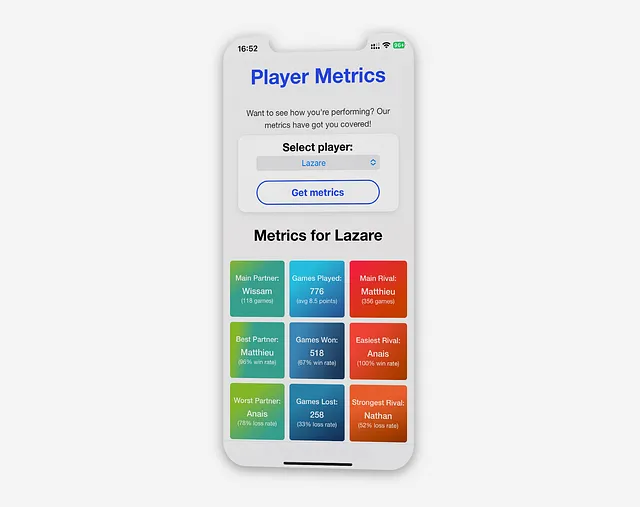
これらのメトリクスは、パートナー、ゲーム、およびライバルの3つの色分けされたカテゴリに整理されており、各メトリクスにはタイトル、値、詳細のためのサブメジャーが付随しています。
ゲームメトリクスこれらのメトリクスは画面の中央に配置され、中立を示す青で表示されます。これにはデータ収集が開始されてからプレイされたゲームの総数が含まれます。
パートナーメトリクスパートナーメトリクスは画面の左側に表示されます。これらはポジティブな意味合いを持つため、緑色で表示されます。
- トップのボックスでは、選択したプレイヤーが最も多くの試合をプレイした主要なパートナーが強調されます
- 2番目のメトリクスでは、プレイヤーの最高勝率に基づいて最高のパートナーが特定されます
- このカテゴリの3番目のメトリクスは、選択したプレイヤーの最悪のパートナーです。これは最低勝率(または最高敗率)に基づいて計算されます
ライバルメトリクスライバルメトリクスは、対立を示すために赤で表示されます。ライバルメトリクスはプレイヤー間の競争的な関係を表します。
- トップのボックスには、最も一般的な対戦相手が表示され、パートナーメトリクスと同様に一緒にプレイした試合の数を示すサブメトリクスがあります
- 2番目のメトリクス「最も簡単なライバル」は、プレイヤーが最も高い勝率を持つ対戦相手を表します。これはより弱い相手を示しています
- 最後のメトリクスは、選択したプレイヤーが最も低い勝率を持つ相手です。このメトリクスは最も困難な対戦相手を示します
結論
この記事を書いている時点で、このアプリケーションは6ヶ月間使用されており、これまでの結果は以下の通りです:
- このEloシステムに基づくランキングシステムは、試合結果を予測し、実際のパフォーマンスに基づいてプレイヤーを正確にランク付けします
- データの可視化により、プレイヤーは自分のパフォーマンスについてより意識するようになり、競争心が高まりました
- リスクを冒すプレイヤーに報酬を与える改善された公式により、プレイヤーはより包括的になりました。通常一緒にプレイしないプレイヤー同士がペアを組むインセンティブが生まれました
データ駆動の戦略を取り入れることで、このプロジェクトはデータの深い影響と重要性を浮き彫りにしました。
プレイヤーのパフォーマンスの単純な分析を超えて、このプロジェクトはフースボールゲームへのアプローチや他のプレイヤーや新参者との相互作用の仕方を変革しました。データの力により、より包括的で競争力のある環境が育まれました。
ここまでお読みいただき、ありがとうございます!この記事が役に立ったと思っていただければ幸いです。フルペーパーを読みたい方は、こちらでご覧いただけます。また、すべてのコードはGithubで利用できます。
コメントでご意見をお聞かせください 🙂
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
