2023年にディープラーニングのためのマルチGPUシステムを構築する方法
2023年にマルチGPUシステムを作る方法

この記事では、ディープラーニングのためのマルチGPUシステムを構築する方法についてのガイドを提供し、研究時間と実験時間を節約できることを願っています。
目標
銀行を破らずに、コンピュータビジョンとLLMsモデルのトレーニングのためのマルチGPUシステムを構築します!🏦
ステップ1. GPUs
楽しい(そして高価💸💸💸)パートから始めましょう!

GPUを購入する際の主な考慮事項は次のとおりです:
- 「言語モデルは自分自身のツールを作ることができるのか?」
- 「教師あり学習の理論と概要の理解」
- このAI論文は、自律言語エージェントのためのオープンソースのPythonフレームワークである「Agents」を紹介しています
- メモリ(VRAM)
- パフォーマンス(テンソルコア、クロック速度)
- スロット幅
- 電力(TDP)
メモリ
現在のディープラーニングタスクでは、非常に多くのメモリが必要です。 LLMは微調整にさえ非常に大きく、コンピュータビジョンタスクは特に3Dネットワークを使用するとメモリを大量に消費します。自然に、最も重要な要素はGPUのVRAMです。LLMでは、少なくとも24 GBのメモリを推奨し、コンピュータビジョンタスクでは12 GBを下回らないようにします。
パフォーマンス
2番目の基準はパフォーマンスであり、FLOPS(秒あたりの浮動小数点演算)で推定することができます:
過去における重要な数値は、回路内のCUDAコアの数でした。しかし、ディープラーニングの登場により、NVIDIAは専用のテンソルコアを導入しました。これらのテンソルコアは、1クロックあたりに多くのFMA(Fused Multiply-Add)演算を実行できます。これらは既に主要なディープラーニングフレームワークでサポートされており、2023年にはこれを探すべきです。
以下は、手作業でまとめたメモリごとのGPUの生のパフォーマンスのチャートです:
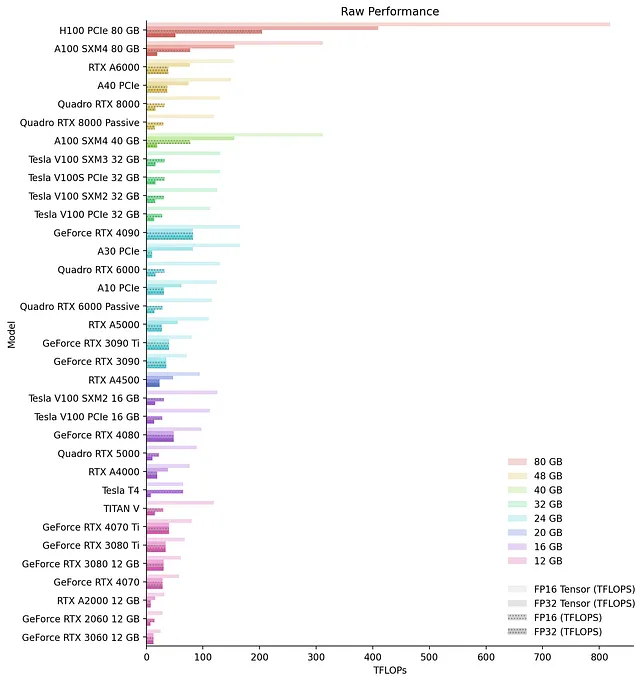
異なるGPUのパフォーマンスを比較する際には、特に注意が必要です。異なる世代/アーキテクチャのテンソルコアは比較できません。例えば、A100は1クロックあたりに256のFP16 FMA演算を実行し、V100は「わずか」64を実行します。さらに、古いアーキテクチャ(チューリング、ボルタ)では32ビットテンソル演算をサポートしていません。比較を困難にするもう1つの要因は、NVIDIAが常にFMAを報告していないことです。同じアーキテクチャのGPUでも、異なるFMAsを持つことがあります。私もこれで頭を打ちました 😵💫。また、NVIDIAはスパース性をテンソルFLOPSで広告することがよくありますが、これは推論時にのみ使用できる機能です。
価格に関して最適なGPUを特定するために、ebayのAPIを使用してebayの価格を収集し、新しいカードのドル(USD)あたりの相対パフォーマンスを計算しました:
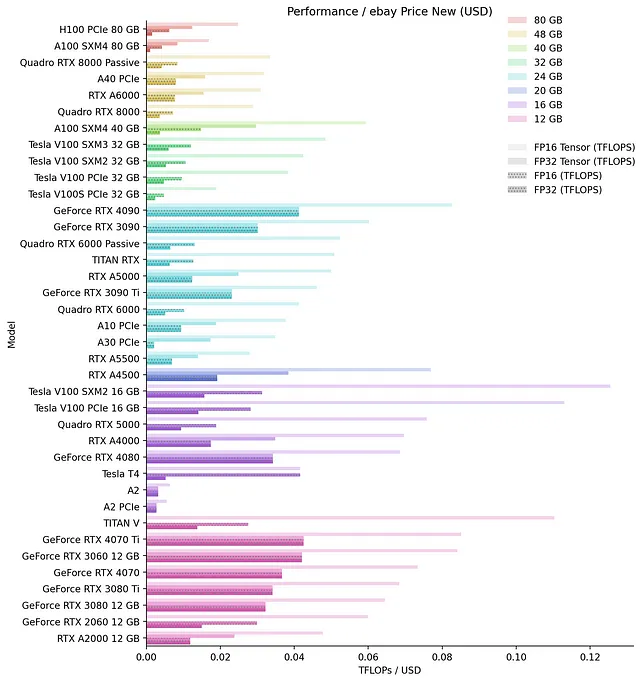
同様に、中古カードについても同じことを行いましたが、ランキングがあまり変わらないため、プロットは省略します。
予算に合った最適なGPUを選ぶためには、予算で買える最大のメモリを持つトップのGPUのうちの1つを選ぶことができます。私のおすすめは次のとおりです:
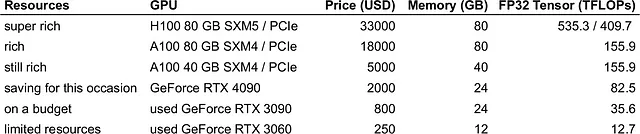
より技術的な側面について深く掘り下げたい場合は、Tim Dettmers氏の「深層学習に適したGPUの選び方」についての優れたガイドを読むことをお勧めします。
スロットの幅
マルチGPUシステムを構築する際には、GPUをPCケースに物理的に収める方法を計画する必要があります。特にゲーミングシリーズのように、GPUはますます大きくなっているため、これはより重要な問題となっています。コンシューマーマザーボードには最大7つのPCIeスロットがあり、PCケースはこのセットアップに基づいて構築されています。一部のメーカーによっては、4090は4つのスロットを占有することがありますので、なぜこれが問題になるかがわかると思います。また、ブロワースタイルやウォータークーリングではないGPUの間には少なくとも1つのスロットを空ける必要があります。以下のオプションがあります:
ウォータークーリングウォータークーリング仕様のGPUは最大2つのスロットを占有しますが、価格が高くなります。代わりにエアクーリングのGPUを変換することもできますが、これは保証が無効になります。オールインワン(AIO)のソリューションを使用しない場合は、カスタムのウォータークーリングループを構築する必要があります。これは、AIOラジエータがケースに収まらない場合にも当てはまります。自分でループを組むことはリスキーであり、高価なカードでは個人的には行いません。私はメーカー直販のAIOソリューションのみを購入します(リスク回避 🙈)。
エアクーリングの2-3スロットカードとPCIeリザーこのシナリオでは、PCIeスロット上にカードを交互に配置し、PCIeリザーケーブルで接続します。PCIeリザーカードはPCケースの内部のどこかに配置するか、オープンエアで配置することができます。いずれの場合でも、GPUが確実に固定されていることを確認してください(PCケースのセクションも参照)。
電力(TDP)
現代のGPUはますます電力を消費する傾向にあります。例えば、4090は450W、H100は最大で700Wを必要とします。電力料金のほかにも、3つ以上のGPUを取り付けることは問題となります。特に、アメリカでは電源ソケットから約1800Wまで供給できることが多いため、これは特に当てはまります。
もしPSU / 電源ソケットから最大電力に近づいている場合、問題に対する解決策は電力制限です。GPUが引き出せる最大電力を削減するために必要なのは:
sudo nvidia-smi -i <GPUのインデックス> -pl <電力制限>(ここで、GPUのインデックスはnvidia-smiで表示されるカードのインデックス(数値)です。電力制限は使用したい電力(W)です)10-20%の電力制限は、パフォーマンスの低下が5%未満であり、カードの冷却を保つことが示されています(Puget Systemsによる実験)。たとえば、4つの3090を20%の電力制限で制限すると、消費電力は1120Wに減少し、1600WのPSU / 1800Wのソケットに容易に収まります(他のコンポーネントに400Wを想定した場合)。
ステップ2. マザーボードとCPU
ビルドの次のステップは、複数のGPUを許容するマザーボードを選ぶことです。ここでの主な考慮事項はPCIeレーンです。各カードには少なくともPCIe 3.0スロットでx8レーンが必要です(Tim Dettmers氏の記事を参照してください)。PCIe 4.0または5.0は稀であり、ほとんどの深層学習用途では必要ありません。
スロットタイプの他に、スロットの間隔がGPUを配置できる場所を決定します。間隔を確認し、GPUを配置したい場所に実際に配置できるかどうかを確認してください。多くのマザーボードでは、複数のGPUを使用する場合には一部のx16スロットに対してx8構成を使用します。この情報を確実に取得する唯一の方法は、カードのマニュアルを参照することです。
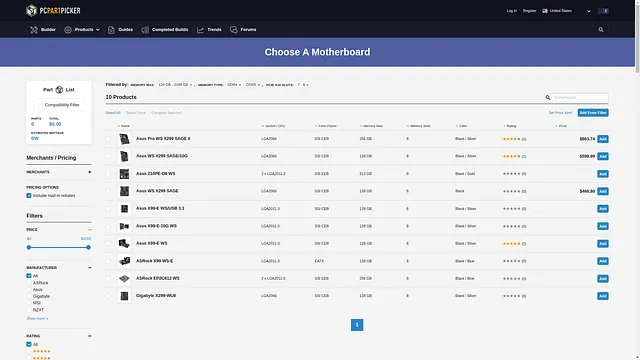
調査に数時間費やさずに、さらに将来に対応したシステムを構築する最も簡単な方法は、すべての場所にx16スロットを持つマザーボードを選ぶことです。PCPartPickerを使用して、7つ以上のPCIe x16スロットを持つマザーボードをフィルタリングすることができます。これにより、10個の製品から選択肢を絞り込むことができます(例えば、128GBの最小RAM量とDDR4 / DDR5タイプを選択して、10個の製品に絞り込むことができます):
上記リストのサポートされているCPUソケットは、LGA2011-3とLGA2066です。次に、CPUの選択に移り、所望のコア数を持つCPUを選択します。これらは主にデータのローディングとバッチの準備に必要です。GPUごとに2つのコア/4つのスレッドを少なくとも目指してください。 CPUでは、サポートするPCIeレーンもチェックする必要があります。過去10年間のどのCPUでも、少なくとも40レーン(4つのGPUをx8レーンでカバーする)をサポートするはずですが、念のために安全を確保する方が良いでしょう。上記のソケットでのフィルタリング(16以上のコア)により、次のCPUが表示されます:
- Intel Xeon E5(LGA2011-3):8つの結果
- Intel Core i9(LGA2066):9つの結果
次に、コアの数、入手可能性、価格に基づいて、お気に入りのマザーボードとCPUの組み合わせを選びます。
LGA2011-3とLGA2066の両方のソケットは非常に古い(それぞれ2014年と2017年)ため、ebayでマザーボードとCPUの両方のお得な取引が見つかることがあります。使用済みの状態でASRock X99 WS-Eマザーボードと18コアのIntel Xeon E5-2697 V4を購入すると、300ドル未満で手に入ることがあります。CPUの安価なESやQSバージョンを購入しないでください。これらはエンジニアリングサンプルであり、故障する可能性があります⚠️️。
より強力かつ最新のもの、またはAMD CPUを購入したい場合は、4つ以上のPCIe x16スロットを備えたマザーボードを検討してくださいが、スロットの間隔を確認する必要があります。
この段階では、PCPartPickerビルドを開始するのが良いアイデアです。🛠️ PCPartPickerは、コンポーネント間の互換性をチェックし、あなたの生活を簡単にします。
ステップ3. RAM 🐏
ここでは、RAMの量が最も重要な要素です。 RAMは、ディスクからデータをロードしてバッチを作成し、モデルをロードし、もちろんプロトタイピングに使用されます。必要な量は、アプリケーションによって大きく異なります(たとえば、3D画像データはさらに多くの追加RAMが必要です)、ただし、GPUの総VRAMの1倍から2倍を目指すべきです。タイプは少なくともDDR4である必要がありますが、RAMクロックはあまり重要ではないため、そこにお金を費やす必要はありません🕳️。
RAMを購入する際には、フォームファクター、タイプ、モジュール数、およびモジュールあたりのメモリがすべてマザーボードの仕様と一致していることを確認する必要があります(PCPartPickerが便利です!)。
ステップ4. ディスク
ディスクも節約できるコンポーネントです 😌。また、ディスク容量も重要で、アプリケーションに依存します。超高速のディスクやNVMEは、ディープラーニングのパフォーマンスに影響を与えませんので、必要ありません。データはすでにRAMにロードされており、ボトルネックを作成しないために、より多くの並列CPUワーカーを使用するだけです。
ステップ5. 電源(PSU) 🔌
GPUは消費電力が大きいコンポーネントです。マルチGPUシステムを設定する際には、PSUの選択が重要な考慮事項となります。ほとんどのPSUは最大1600Wまで供給できます-これは米国のソケットの電力制限に合致しています。それ以上の電力を供給できるPSUもいくつかありますが、調査が必要であり、特にマイナーを対象としています。
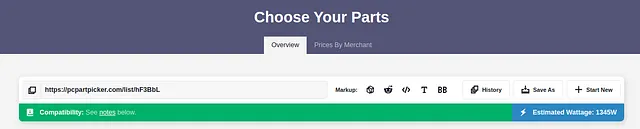
システムのワット数を決定するには、再びPCPartPickerを使用して、ビルドの総量を計算できます。ここには、GPUの仕様よりも大きな電力スパイクがあるため、心配のために10%以上の余裕を追加する必要があります。
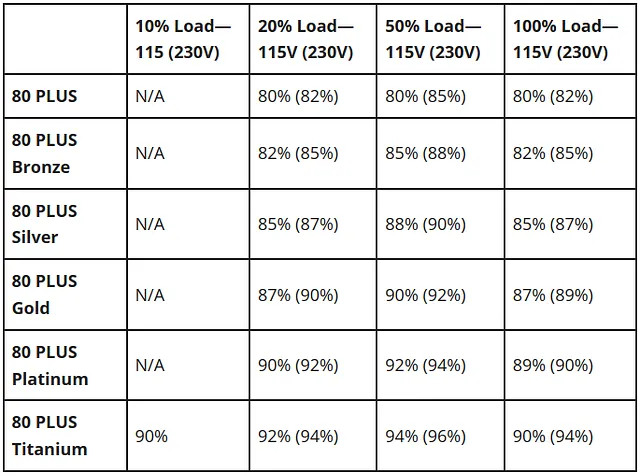
重要な基準は、80 PLUSの評価で示されるPSUの効率です。供給力は広告通りに達するものの、その過程で一部の電力を失います。80 PLUS Bronzeの供給力は82%の効率で評価されますが、Goldの場合は87%の効率に達します。たとえば、1600Wを消費するシステムを20%の時間使用する場合、Gold評価のGPUを使用すると、年間22ドルを節約できます。ただし、1kWhあたりの費用が0.16ドルと仮定しています。価格を比較する際には、これを考慮に入れて計算してください。
フルロード時には、一部のPSUは高回転数のファンを使用するため、他のPSUよりも騒音が大きい場合があります。もしケースに近い場所で作業している(または寝ている)場合は、これがいくらかの影響を及ぼす可能性があるため、マニュアルからデシベル数を確認することは良いアイデアです 😵。
電源を選ぶ際には、すべてのパーツに十分なコネクタがあることを確認する必要があります。特にGPUは8(または6+2)ピンケーブルを使用します。ここで重要なポイントは、GPUの各電力スロットには個別の8ピンケーブルを使用し、同じケーブルの複数の出力を使用しない(デイジーチェーン)ことです。8ピンケーブルは一般的に約150Wの評価です。1つのケーブルを複数の電力スロットに使用すると、GPUに十分な電力が供給されずに制限がかかる場合があります。
ステップ6. PCケース
最後に、PCケースの選択は簡単ではありません。GPUは非常に大きくなることがあり、いくつかのケースには収まりません。たとえば、4090は36cmの長さになることがあります 👻!
さらに、PCIeリザーを使用してGPUを取り付ける場合は、いくつかの工夫が必要です。Phanteks Enthoo 719のようなデュアルシステムケースなど、追加のカードを取り付けることができる新しいケースもあります。また、Lian-Li O11D EVOでは、Lian-Li Upright GPU Bracketを使用してGPUを縦向きに取り付けることができます。私はこれらのケースを持っていないので、3090 / 4090などの複数のGPUがどれほど収まるかはわかりません。ただし、Lian-Liブラケットを使用すれば、PCケースが直接サポートしていなくてもGPUを縦向きに取り付けることはできます。ケースに2〜3つの穴を開ける必要がありますが、それほど難しくはありません(後でガイドを紹介します!)。
最後に
このガイドをお楽しみいただき、いくつかの有用なヒントが見つかることを願っています。このガイドは、マルチGPUシステムの構築に関する研究のお手伝いをすることを目的としており、それを代替するものではありません。ご質問やコメントがあれば、お気軽にお送りください。上記の内容について何か誤った情報があれば、コメントやDMをいただけると幸いです 🙏!
注意:特に記載がない限り、すべての画像は著者によるものです。いくつかのアフィリエイトAmazonリンクも含まれています。リンクを介して商品を購入すると追加費用はかかりませんが、私には少額の手数料が入る可能性があります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「vLLMに会ってください:高速LLM推論とサービスのためのオープンソース機械学習ライブラリ」
- 「Würstchenをご紹介します:高速かつ効率的な拡散モデルで、テキスト条件付きコンポーネントは画像の高圧縮潜在空間で動作します」
- AutoMLのジレンマ
- 「CodiumAIに会ってください:開発者のための究極のAIベースのテストアシスタント」
- スタビリティAIが安定したオーディオを導入:テキストプロンプトからオーディオクリップを生成できる新しい人工知能モデル
- 「リソース制約のあるアプリケーションにおいて、スパースなモバイルビジョンMoEsが密な対応物よりも効率的なビジョンTransformerの活用を解き放つ方法」
- 機械学習、イラストで解説:インクリメンタル学習






