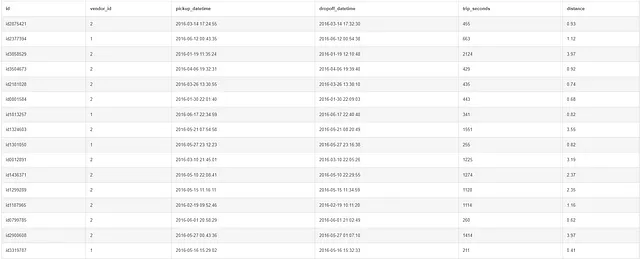
SELECT CAST(STRFTIME('%H', pickup_datetime) AS INT) AS hour_of_day, trip_seconds, distance FROM taxi WHERE pickup_datetime > '2016-01-01' AND pickup_datetime < '2016-04-01' ORDER BY hour_of_day;
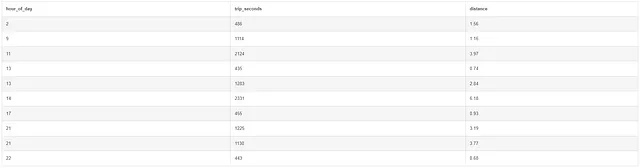
WITH relevantrides AS (SELECT CAST(STRFTIME('%H', pickup_datetime) AS INT) AS hour_of_day, trip_seconds, distance FROM taxi WHERE pickup_datetime > '2016-01-01' AND pickup_datetime < '2016-04-01' ORDER BY hour_of_day) SELECT hour_of_day, COUNT(1) as num_trips, ROUND(3600 * SUM(distance) / SUM(trip_seconds), 2) as avg_speed FROM relevantrides GROUP BY hour_of_day ORDER BY hour_of_day;
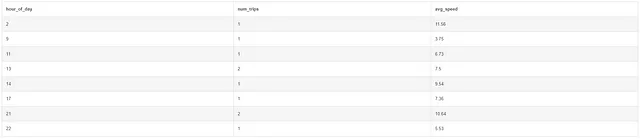
SELECT hour_of_day, COUNT(1) as num_trips, ROUND(3600 * SUM(distance) / SUM(trip_seconds), 2) as avg_speed FROM ( SELECT CAST(STRFTIME('%H', pickup_datetime) AS INT) AS hour_of_day, trip_seconds, distance FROM taxi WHERE pickup_datetime > '2016-01-01' AND pickup_datetime < '2016-04-01' ORDER BY hour_of_day) GROUP BY hour_of_day ORDER BY hour_of_day;
SELECT CAST(STRFTIME('%m', pickup_datetime) AS INT) AS month, COUNT(1) AS trip_count, ROUND(SUM(distance), 3) AS total_distance, ROUND(AVG(distance), 3) AS avg_distance, MIN(distance) AS min_distance, MAX(distance) AS max_distanceFROM taxiGROUP BY month;
ウィンドウ関数を実行するための構文はOVER(PARTITION BY ...)です。これは前の例でのGROUP BY文と考えることができます。
実際の動作を見てみましょう。
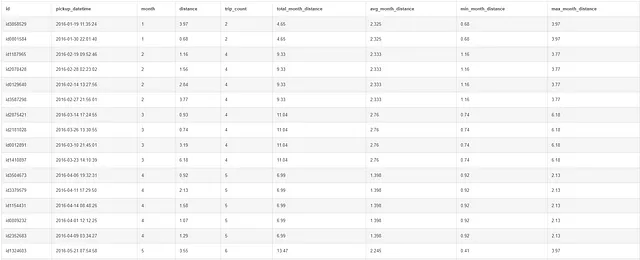
WITH aggregate AS(SELECT id, pickup_datetime, CAST(STRFTIME('%m', pickup_datetime) AS INT) AS month, distanceFROM taxi)SELECT *, COUNT(1) OVER(PARTITION BY month) AS trip_count, ROUND(SUM(distance) OVER(PARTITION BY month), 3) AS total_month_distance, ROUND(AVG(distance) OVER(PARTITION BY month), 3) AS avg_month_distance, MIN(distance) OVER(PARTITION BY month) AS min_month_distance, MAX(distance) OVER(PARTITION BY month) AS max_month_distanceFROM aggregate;
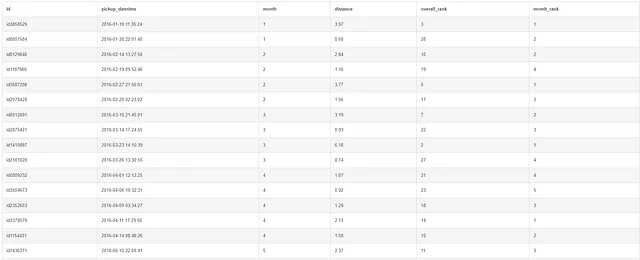
WITH ranking AS(SELECT id, pickup_datetime, CAST(STRFTIME('%m', pickup_datetime) AS INT) AS month, distanceFROM taxi)SELECT *, RANK() OVER(ORDER BY distance DESC) AS overall_rank, RANK() OVER(PARTITION BY month ORDER BY distance DESC) AS month_rankFROM rankingORDER BY pickup_datetime;
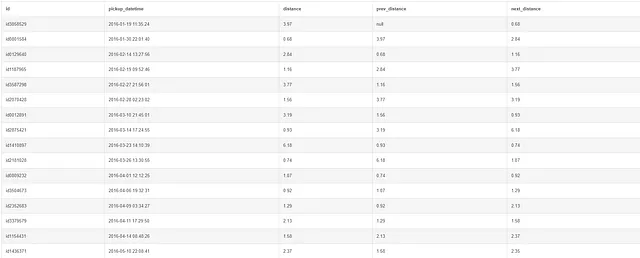
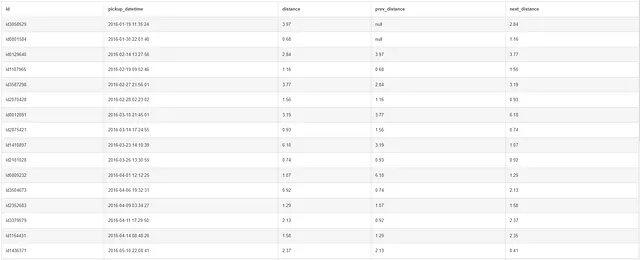
SELECT id, pickup_datetime, distance, LAG(distance) OVER(ORDER BY pickup_datetime) AS prev_distance, LEAD(distance) OVER(ORDER BY pickup_datetime) AS next_distanceFROM taxiORDER BY pickup_datetime;
Lag returns the value of the preceding row. Image by Author.Lead returns the value of the subsequent row. Image by Author.
上記の例では、LAG 関数を使用して前の行の値を返し、LEAD 関数を使用して次の行の値を返しています。最初の行の lag 列は null で、最後の行の lead 列も null であることに注意してください。
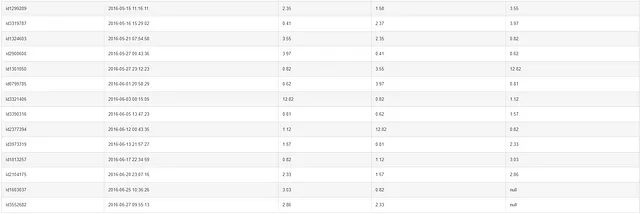
SELECT id, pickup_datetime, distance, LAG(distance, 2) OVER(ORDER BY pickup_datetime) AS prev_distance, LEAD(distance, 2) OVER(ORDER BY pickup_datetime) AS next_distanceFROM taxiORDER BY pickup_datetime;
The first two rows are null when lag offset is set to 2. Image by Author.The last two rows are null when lead offset is set to 2. Image by Author.
同様のノートで、LEAD および LAG 関数のオフセットも設定することができます。オフセットが2に設定された場合、lag 列の最初の2行が null であり、lead 列の最後の2行も null であることがわかります。