AIの10年間のレビュー
10-year Review of AI
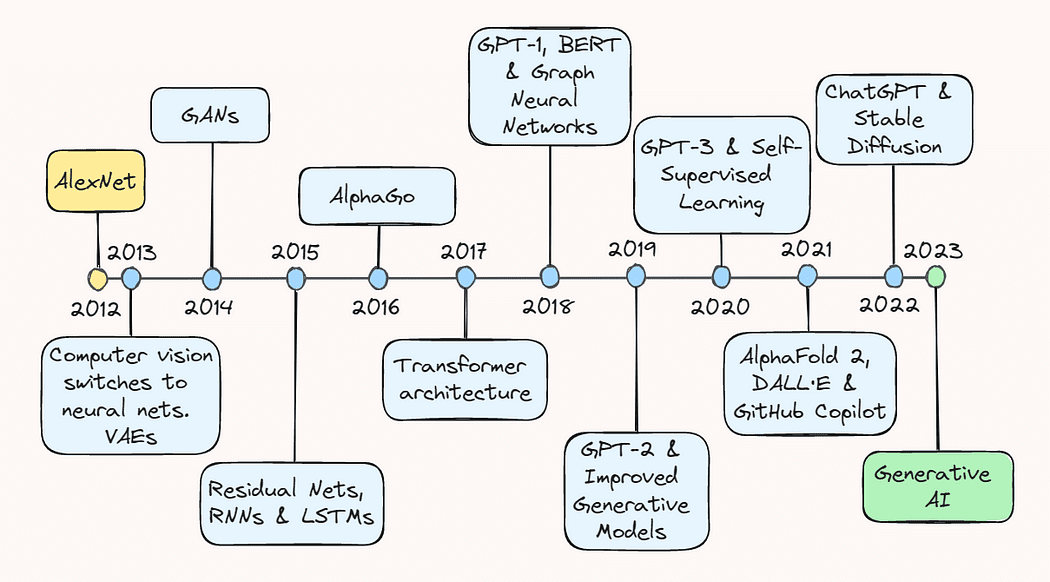
人工知能(AI)の分野は、過去10年間で驚くべき進歩を遂げました。ディープラーニングの可能性に対する探求が次第に広がり、今では、eコマースのおすすめシステムから自律走行車の物体検出、現実的な画像から一貫したテキストまで、あらゆるものを生成できる生成モデルまで含まれるようになりました。
本記事では、過去のキーブレイクスを振り返り、現在の状況に至るまでの進歩を総合的に把握していただけるようになっています。AIの熟練者であるか、単に分野の最新動向に興味を持っている方であれば、この記事はAIが世間に知られるようになった驚異的な進歩を包括的に説明します。
2013年:AlexNetと変分オートエンコーダー
2013年は、主にコンピュータビジョンの重大な進展により、ディープラーニングの「成人期」と位置づけられています。Geoffrey Hintonの最近のインタビューによると、「2013年までには、ほとんどのコンピュータビジョン研究がニューラルネットワークに切り替わっていた」とのことです。2012年には、画像認識の驚異的なブレークスルーがあったこともあり、機械学習の勃興が起こりました。
2012年9月、深層畳み込みニューラルネットワーク(CNN)であるAlexNetが、ImageNet Large Scale Visual Recognition Challenge(ILSVRC)で記録的な成績を収め、画像認識タスクにおけるディープラーニングの可能性を実証しました。Top-5エラー率は15.3%であり、最も近い競合者より10.9%低かったです。
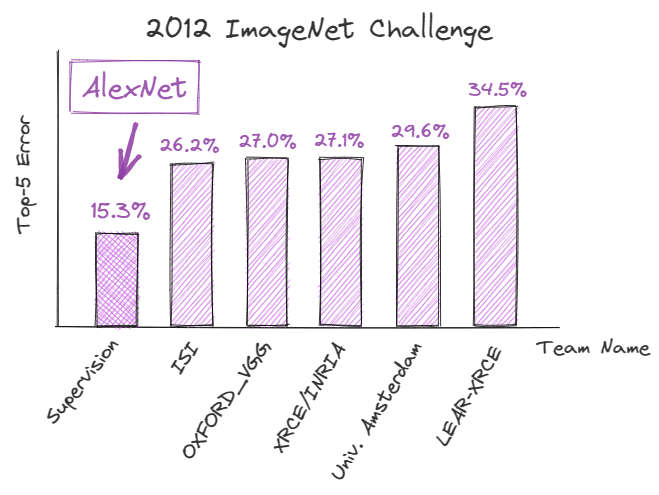
この成功の背後にある技術的な改善は、AIの将来の軌跡を決定し、ディープラーニングの見方を劇的に変えました。
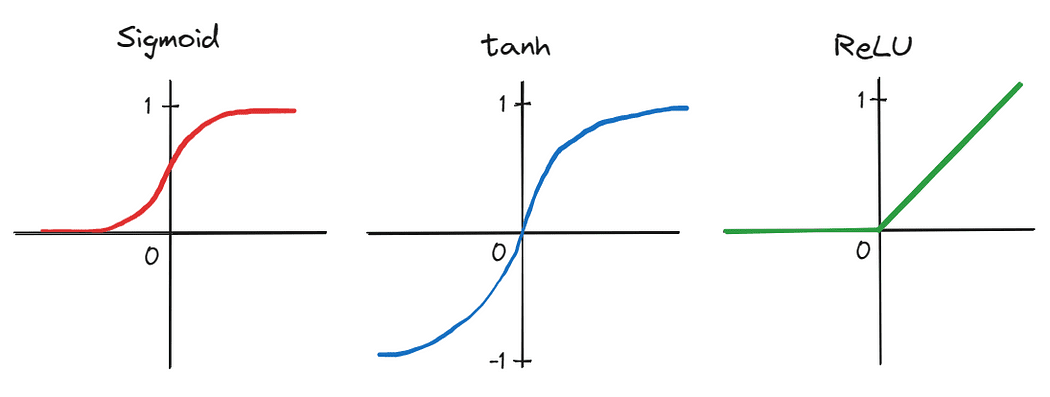
まず、著者は、5つの畳み込み層と3つの完全連結線形層から構成される深いCNNを適用しました。当時、多くの人によって実用的でないと見なされていました。さらに、ネットワークの深さによって生成されるパラメータの数が多いため、トレーニングは2つのグラフィックスプロセッシングユニット(GPU)で並列に行われ、大規模なデータセットでトレーニングを大幅に加速することができることが示されました。また、シグモイドやtanhなどの従来の活性化関数を、より効率的なReLUに置き換えることで、トレーニング時間をさらに短縮しました。
これらの進歩は、AlexNetの成功につながり、AIの歴史の転換点となり、学術界や技術コミュニティの両方にディープラーニングに対する興味を引き起こしました。その結果、2013年以降、ディープラーニングが本格的に始まったと位置づけられるようになりました。
また、2013年には、AlexNetに比べてやや控えめではありますが、変分オートエンコーダー(VAE)の開発もありました。VAEは、画像や音声などのデータを表現して生成できる生成モデルです。入力データの圧縮表現を学習し、低次元空間で表現します。これにより、学習された潜在空間からサンプリングすることで、新しいデータを生成することができます。VAEは、後に、芸術、デザイン、ゲーミングなどの分野で生成モデリングやデータ生成の新しいアプローチを開拓しました。
2014年:敵対的生成ネットワーク
翌年、2014年6月には、Ian Goodfellow氏らによって敵対的生成ネットワーク(GAN)が導入され、ディープラーニングの分野はさらなる進展を遂げました。
GANは、訓練セットに似た新しいデータサンプルを生成できるニューラルネットワークの一種です。基本的には、2つのネットワークが同時にトレーニングされます。つまり、(1)ジェネレーターネットワークが偽のサンプルを生成し、(2)識別器ネットワークがその真正性を評価します。このトレーニングは、ジェネレーターが識別器を騙すサンプルを作成しようとする一種のゲームのような構成で行われます。
当時のGANは、画像や動画の生成だけでなく、音楽や芸術の生成にも使用され、明示的なラベルに頼らずに高品質のデータサンプルを生成する可能性を示すことにより、教師なし学習の進展に貢献しました。
2015年:ResNetsとNLPのブレークスルー
2015年、AI分野はコンピュータビジョンと自然言語処理(NLP)の両方で大きな進歩を遂げました。
Kaiming He氏らは「Deep Residual Learning for Image Recognition」と題する論文を発表し、残差ニューラルネットワークまたはResNetと呼ばれる構造を導入しました。ResNetは、ネットワーク内の情報がスキップされることで、ネットワーク内で情報の流れをより簡単にするアーキテクチャです。通常のニューラルネットワークとは異なり、各層が前の層の出力を入力として受け取るのではなく、ResNetでは、1つまたは複数の層をスキップして、より深い層に直接接続する追加の残差接続が追加されます。
その結果、ResNetは消失勾配の問題を解決し、当時思われていたよりもはるかに深いニューラルネットワークのトレーニングを可能にしました。これにより、画像分類やオブジェクト認識タスクの大幅な改善がもたらされました。
同じ頃、リカレントニューラルネットワーク(RNN)と長短期記憶(LSTM)モデルの開発について研究者たちは大きな進展を遂げました。これらのモデルは1990年代から存在していたにもかかわらず、トレーニングに使用されるより大きく、より多様なデータセットが利用可能になったこと、より高速なコンピュータとハードウェアの改善が可能になったこと、さらにはより洗練されたゲート機構などの改良が行われたことなどの要因により、2015年頃から注目を集めるようになりました。
その結果、これらのアーキテクチャにより、言語モデルがテキストの文脈と意味をよりよく理解できるようになり、言語翻訳、テキスト生成、感情分析などのタスクの大幅な改善がもたらされました。RNNとLSTMの成功は、私たちが今日見ている大規模言語モデル(LLMs)の開発の道を開いたのです。
2016年:AlphaGo
1997年のGarry Kasparov氏のIBMのDeep Blueによる敗北に続いて、もう1つの人間対マシンの戦いが2016年にゲーム世界に衝撃を与えました:GoogleのAlphaGoが世界チャンピオンのLee Sedolを破りました。

Sedol氏の敗北は、コンピュータが処理するのにあまりにも複雑すぎると考えられていたゲームで、最も熟練した人間プレーヤーさえも打ち負かすことができることを示しました。AlphaGoは、深層強化学習とモンテカルロツリー探索の組み合わせを使用して、過去のゲームから数百万のポジションを分析し、最適な手を評価する戦略を採用しています。この戦略は、この文脈での人間の意思決定をはるかに超えています。
2017年:Transformerアーキテクチャと言語モデル
おそらく、2017年は、私たちが今日目撃している生成的AIのブレークスルーの基礎を築いた最も重要な年でした。
2017年12月、Vaswani氏らは、シーケンシャルな入力データを処理するために自己注意の概念を活用するTransformerアーキテクチャを紹介した基礎的な論文「Attention is all you need」を公表しました。これにより、従来のRNNアーキテクチャにとって課題であった長距離依存関係のより効率的な処理が可能になりました。

Transformerは、エンコーダとデコーダの2つの必須コンポーネントで構成されています。エンコーダは、例えば単語のシーケンスである入力データをエンコードし、入力シーケンスを取り、自己注意とフィードフォワードニューラルネットワークの複数層を適用して、文内の関係と特徴を捉え、意味のある表現を学習します。
基本的に、自己注意は、モデルが文の中の異なる単語間の関係を理解することを可能にします。従来のモデルが単語を固定順序で処理するのに対し、Transformerは実際にすべての単語を一度に検討します。それらは、文の他の単語との関連性に基づいて、何かというと、注意点を各単語に割り当てます。
一方、デコーダは、エンコーダから受け取ったエンコードされた表現を取り、出力シーケンスを生成します。機械翻訳やテキスト生成などのタスクでは、デコーダはエンコーダから受け取った入力に基づいて翻訳シーケンスを生成します。エンコーダと同様に、デコーダにも自己注意とフィードフォワードニューラルネットワークの複数層が含まれます。ただし、エンコーダの出力にフォーカスできる追加の注意機構も含まれています。これにより、デコーダは、出力を生成する際に入力シーケンスから関連する情報を考慮することができます。
Transformerアーキテクチャは、LLMsの開発において重要な要素となり、機械翻訳、言語モデル、質問応答などのNLP領域全体での大幅な改善につながっています。
2018年:GPT-1、BERT、およびグラフニューラルネットワーク
Vaswaniらが基礎となる論文を発表して数ヶ月後、OpenAIは2018年6月にG enerative P retrained T ransformer、またはGPT-1を導入しました。このモデルは、transformerアーキテクチャを利用して、テキストの長距離依存関係を効果的に捉えることができます。GPT-1は、教師なしの事前学習に続く特定のNLPタスクでの微調整の有効性を実証した最初のモデルの1つでした。
また、まだ比較的新しいtransformerアーキテクチャを活用したのはGoogleで、2018年末には、B idirectional E ncoder R epresentations from T ransformers、またはBERTと呼ばれる独自の事前学習手法をリリースしてオープンソース化しました。以前のモデルとは異なり(GPT-1を含む)、BERTは各単語の文脈を同時に両方向から考慮します。著者は、非常に直感的な例を提供してこれを示しています。
「私は銀行口座にアクセスしました」という文で、単方向のコンテキストモデルでは、「銀行」は「私がアクセスした」に基づいて表されますが、「口座」は表されません。しかし、BERTは、非常に深いニューラルネットワークの最下層から始めて、前後の文脈「私は…口座にアクセスしました」を使用して「銀行」を表します。これにより、BERTは深く双方向になります。
双方向性の概念は非常に強力で、BERTはベンチマークタスクの多くで最先端のNLPシステムを凌駕しました。
GPT-1とBERTに加えて、グラフニューラルネットワーク、またはGNNも話題になりました。これらは、グラフデータで動作するように特別に設計されたニューラルネットワークのカテゴリーに属しています。GNNは、グラフのノードとエッジを横断して情報を伝達するメッセージパッシングアルゴリズムを利用します。これにより、ネットワークはデータの構造と関係をより直感的な方法で学習することができます。
この作業により、データからより深い洞察を抽出することができ、それにより、ディープラーニングが適用できる問題の範囲が拡大しました。GNNにより、社会ネットワーク分析、推薦システム、薬剤探索などの分野で大きな進歩が可能になりました。
2019年:GPT-2および改良された生成モデル
2019年は、特にGPT-2の導入により、生成モデルのいくつかの注目すべき進展がありました。このモデルは、多くのNLPタスクで最先端のパフォーマンスを達成し、さらに、非常にリアルなテキストを生成することができるようになりました。これは、後にこの領域で何が起こるかの予告編を私たちに与えました。
この領域の他の改良には、DeepMindのBigGANが含まれ、高品質の画像を生成し、ほとんど本物の画像と区別できないものになりました。さらに、NVIDIAのStyleGANは、生成された画像の外観をより良く制御することができるようになりました。
これらの生成AIの進展は、この領域の境界をさらに押し広げ、…
2020年:GPT-3およびセルフスーパーバイズドラーニング
…その後、別のモデルが誕生し、テックコミュニティの外でも馴染みのある名前になりました:GPT-3。このモデルは、LLMsの規模と機能性において大きな飛躍を表しました。GPT-1は117 millionのパラメーターを持っていましたが、GPT-2では15億、GPT-3では1750億に増えました。
この膨大なパラメータースペースにより、GPT-3は、幅広いプロンプトやタスクにわたって非常に一貫したテキストを生成することができます。また、テキストの補完、質問応答、創造的な文章作成など、様々なNLPタスクで印象的なパフォーマンスを発揮しました。
さらに、GPT-3は、大量の未ラベルデータでモデルを訓練することができるセルフスーパーバイズドラーニングの可能性を再び示しました。これにより、これらのモデルは広範な言語理解を獲得できるため、タスク固有のトレーニングが必要なくなり、経済的になります。
Yann LeCunは、セルフスーパーバイズドラーニングに関するNYTの記事についてツイートしています。
2021年:AlphaFold 2、DALL·E、およびGitHub Copilot
タンパク質の折り畳みから画像生成、自動コーディング支援まで、2021年はAlphaFold 2、DALL·E、GitHub Copilotのリリースにより、イベントフルな年となりました。
AlphaFold 2は、数十年にわたるタンパク質の折り畳み問題に終止符を打つ待望のソリューションとして歓迎されました。DeepMindの研究者たちは、進化的戦略を利用してモデルの最適化を行うためのアーキテクチャであるevoformerブロックを作成するために、トランスフォーマーアーキテクチャを拡張しました。これにより、タンパク質の1Dアミノ酸配列に基づいてタンパク質の3D構造を予測することができるモデルが構築されました。このブレイクスルーには、医薬品の開発、バイオエンジニアリング、生物学的システムの理解などの領域を革新するという巨大なポテンシャルがあります。
OpenAIもまた、GPTスタイルの言語モデルと画像生成の概念を組み合わせたDALL·Eのリリースで再びニュースに登場しました。このモデルは、テキストの記述から高品質の画像を生成することができます。
このモデルがどれだけ強力であるかを示すために、以下の画像を考えてみてください。この画像は、「飛行車がある未来的な世界の油絵」というプロンプトで生成されたものです。

最後に、GitHubは後に開発者の親友となるCopilotをリリースしました。OpenAIとの協力により、Codexと呼ばれる基礎となる言語モデルが提供され、さまざまなプログラミング言語でコードを理解して生成することを学習するために、大量の公開コードのコーパスでトレーニングされました。開発者は、解決しようとしている問題を示すコードコメントを提供するだけで、Copilotを使用することができます。その他の機能には、自然言語で入力コードを説明したり、プログラミング言語間でコードを翻訳したりする機能があります。
2022年:ChatGPTとStable Diffusion
過去10年間にわたるAIの急速な発展は、OpenAIのChatGPTという画期的な進歩につながりました。このチャットボットは、2022年11月にリリースされ、NLPの最先端の成果であり、幅広いクエリやプロンプトに対して、首尾一貫した文脈に即した回答を生成することができます。さらに、会話を展開し、説明を提供し、創造的な提案を行い、問題解決を支援し、コードを書いて説明し、さまざまな人格や文体をシミュレートすることもできます。

また、ボットとのインタラクションを可能にするシンプルで直感的なインターフェースは、使用性の急激な向上を刺激しました。以前は、AIに基づく最新の発明を試していたのは主にテックコミュニティでした。しかし、現在では、AIツールは、ソフトウェアエンジニアから作家、音楽家、広告業者まで、ほとんどの専門分野に浸透しています。多くの企業が、顧客サポート、言語翻訳、FAQへの回答などのサービスを自動化するためにこのモデルを使用しています。実際、見ている自動化の波は、自動化される可能性のある仕事についての懸念を再燃させ、議論を刺激しました。
2022年には、ChatGPTが注目を集めていましたが、画像生成にも重要な進歩がありました。Stable diffusionという潜在的なテキストから画像への拡散モデルが、Stability AIによってリリースされました。このモデルは、画像にノイズを反復的に追加してから逆のプロセスでデータを回復することによって動作する従来の拡散モデルを拡張して設計されました。これは、低次元表現または潜在空間に直接入力画像を操作することで、このプロセスを高速化するためです。また、ユーザーからのトランスフォーマーに埋め込まれたテキストプロンプトをネットワークに追加することにより、拡散プロセスを変更して、各イテレーションで画像生成プロセスをガイドできるようにしました。
全体的に、2022年のChatGPTとStable Diffusionのリリースは、多様なモダルで生成されるAIの可能性を示し、この分野のさらなる開発と投資を大幅に促進しました。
2023年:LLMsとボット
現在の年は、明らかにLLMsとチャットボットの年として浮上しています。ますます多くのモデルが、急速に増加するペースで開発されてリリースされています。
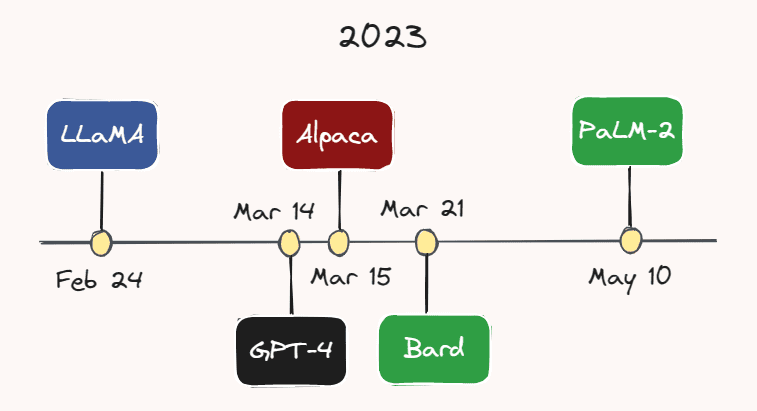 Image by the Author.
Image by the Author.
例えば、Meta AIは2月24日にLLaMAをリリースしました。これは、GPT-3よりもはるかに小さなパラメータ数であるにもかかわらず、ほとんどのベンチマークでGPT-3を上回るLLMです。1か月もしないうちに、3月14日には、OpenAIがGPT-3よりも大きく、より能力が高く、マルチモーダルなバージョンであるGPT-4をリリースしました。GPT-4の正確なパラメータ数は不明ですが、数兆と推定されています。
3月15日、スタンフォード大学の研究者たちは、LLaMAから派生した instruction-following demonstrations で微調整された軽量言語モデル Alpaca をリリースしました。数日後の3月21日、GoogleはそのChatGPTのライバルであるBardを立ち上げました。Googleはまた、この月の初めに最新のLLM、PaLM-2をリリースしました。この分野の開発が着実に進んでいるため、あなたがこれを読んでいる時点で別のモデルが出現する可能性が非常に高いです。
私たちはまた、これらのモデルを製品に取り込む企業が増えていることを見ています。例えば、Duolingoは、個々に合わせた言語レッスンを提供する新しいサブスクリプション層であるGPT-4パワードのDuolingo Maxを発表しました。SlackはSlack GPTというAIパワードのアシスタントを導入し、返信の下書きを作成したり、スレッドを要約したりすることができます。さらに、ShopifyはChatGPTパワードのアシスタントを同社のShopアプリに導入し、様々なプロンプトを使って顧客が希望する商品を特定するのを手助けします。
Shopifyは、Twitter上でChatGPTパワードのアシスタントを発表しました。
興味深いことに、AIチャットボットは現在、人間のセラピストの代替手段としても考えられています。たとえば、米国のチャットボットアプリReplikaは、常にあなたの味方であり、話し聞き役としてのAIコンパニオンを提供しています。創業者のEugenia Kuydaは、アプリには自閉症の子供から「人間との交流の前に暖まる」ために利用する人、単に友達が必要な孤独な大人まで様々な顧客がいると述べています。
結論に入る前に、過去10年間のAI開発の頂点となり得るものを強調しておきたいと思います。それは、人々が実際にBingを使用し始めたことです。今年初め、Microsoftは「ウェブのための共同作業者」としてカスタマイズされたGPT-4パワードのものを導入し、長年にわたってGoogleの支配力に対する初めての真剣な競争相手として現れました。
振り返りと展望
過去10年間のAI開発を振り返ると、私たちは仕事の仕方、ビジネス、およびお互いとの相互作用に深い影響を与えた変革を見てきました。特にLLMにおいて最近達成された著しい進歩の大部分は、「大きければ良い」という共通の信念に従っているように思われます。これは、GPTシリーズで特に目立っており、117百万のパラメータ(GPT-1)から始まり、各次のモデルがおおよそ1桁増えるごとに、最大で数兆のパラメータを持つGPT-4に至ったからです。
しかし、最近のインタビューによると、OpenAIのCEOであるSam Altmanは、「大きければ良い」という時代は終わったと考えています。今後もパラメータ数は増加すると考えていますが、将来のモデルの改善の主な焦点は、モデルの能力、有用性、および安全性の向上にあると彼は考えています。
後者は特に重要です。これらの強力なAIツールが研究室の制御された環境にとどまらず、一般の人々の手にあることを考えると、これらのツールが安全であり、人類の最善の利益に沿ったものであることを確認するために、慎重に進むことが今以上に重要になっています。他の分野で見られたように、AIの安全性に対する開発と投資が同様に進むことを願っています。
PS: もし、この記事に含まれるべき核心的なAIコンセプトやブレークスルーを見逃してしまった場合は、以下のコメント欄で教えてください!
Thomas A Dorferは、Microsoftのデータ&アプリケーションサイエンティストです。現在の役割以前に、彼はバイオテクノロジー産業のデータサイエンティストとして、また、神経フィードバックの分野の研究者として働いていました。彼は統合的な神経科学の修士号を持ち、余暇にはデータサイエンス、機械学習、およびAIの技術ブログ記事をVoAGIに書いています。
オリジナル。許可を得て再掲載。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





