「埋め込みを使った10の素敵なこと!【パート1】」
10 Wonderful Things with Embeddings! [Part 1]
これらの概念を応用して、ディープラーニングの実世界の産業問題を解決する
古典的な機械学習(ML)から一歩踏み出し、埋め込みはほとんどのディープラーニング(DL)のユースケースの核心です。この概念を把握することで、特徴空間で柔軟なタスクを実行し、コンピュータビジョンや自然言語処理における高次元データを含むML / DLの問題を異なる視点で再構築することができます。
埋め込みは、大規模な言語モデル(LLM)を含む現在のさまざまなアプリケーション領域に重要な影響を与えています。埋め込みに関するこれらの素晴らしいが散在した概念の中で、文献に欠けているのは、異なる業界のアプリケーションとその領域での開始方法に関する明確な設計図です!そのため、このブログでは、埋め込みを活用し、実世界の産業問題に適用するさまざまな方法を紹介します。
「この記事は2部構成の第1部です。これはさまざまなタイプの人気のあるオープンソースモデルの初心者ガイドであり、埋め込みのコアコンセプトについて理解を深めることを目的としています。」
埋め込みの直感的な説明
埋め込みは、離散変数の低次元の学習された連続ベクトル表現です[1]。
この定義を分解して重要なポイントを吸収することができます:
- 入力データよりも低い次元
- データの圧縮表現
- モデルが学習した複雑な非線形関係を線形表現として捉える
- 関連情報を保存し、ノイズを破棄することで次元を削減する
- 通常はニューラルネットワークの最終層(分類器の直前)から抽出される
例を使って定義と埋め込みの真のポテンシャルを直感的に理解しましょう。コールセンターオペレーターのパフォーマンスを、顧客のアンケートフォームに基づいて分析しているとします。フォームは数千人の顧客から提出され、数百万のユニークな単語を含んでいます。テキスト分析を行うためには、入力パラメータセットが非常に大きく、パフォーマンスが低下する可能性があります。ここで、埋め込みが登場します!
元の入力パラメータセットを取る代わりに、すべてのユニークな単語を埋め込みとして表現します。これにより、次元を削減し、モデルがより消化しやすい9という入力フィーチャセットに縮小します。オペレーターの埋め込みを視覚化すると、オペレーターBとCが類似の顧客フィードバックを受けたことがわかります。別の例はこちらで見つけることができます。[2]

埋め込みで何ができるのか?
シリーズの第I部では、埋め込みの以下のアプリケーションを探求します:
- テキスト埋め込みを使用して類似のテキストを見つける
- ビジュアル埋め込みを使用して類似の画像を見つける
- 異なるタイプの埋め込みを使用して類似のアイテムを見つける
- 埋め込みに異なる重みを使用して類似のアイテムを見つける
- 画像とテキストの埋め込みを同じ空間に配置する(マルチモーダル)
各ポイントは前のポイントに基づいて構築され、乗算効果を引き起こします。コードの断片は自己完結型で初心者にも使いやすく、遊びながら試すことができます。これらは、より複雑なシステムを作成するための基本的な構成要素として使用することができます。では、以下の各ユースケースについて詳しく見ていきましょう。
I. テキスト埋め込みを使用して類似のテキストを見つける
テキスト埋め込み = 低次元空間においてテキスト(単語または文)を実数値ベクトルとして表現すること。
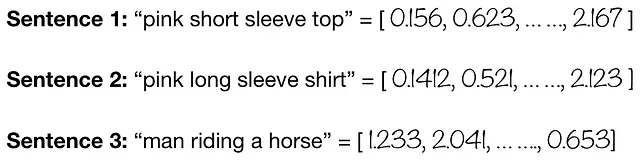
さて、上記の文がどれだけ似ているか、または異なっているかを知りたいとします。テキストエンコーダを使用してそれを行うことができます。ここでは、Hugging Faceの事前学習済みのDistilBERTを使用してテキスト埋め込みを計算し、コサイン類似度を使用して類似度を計算します!
コサイン類似度を使用して、異なるテキスト間のDistilBERTテキスト埋め込みを比較します
似たような単語を含むテキストは、より高い類似度スコアを示すことが観察されます。一方で、単語の選択、意味、文脈(モデルによって異なる!)などが異なるテキストは、以下に示すようにより低い類似度スコアとなります。したがって、テキスト埋め込みは、意味的な関係を確立するために単語の意味的な近さを使用することを目指しています。

現実世界の応用:ドキュメント検索、情報検索、感情分析、検索エンジン[3]
II. 類似画像を見つけるためにビジュアル埋め込みを使用する
ビジュアル埋め込み = 画像(つまり、ピクセル値)を低次元の実数ベクトルとして表現すること
テキストの代わりに、今度は2つの画像の視覚的な類似性を知りたいとします。それには画像エンコーダを使用することができます。ここでは、事前学習されたResNet-18を使用してビジュアル埋め込みを計算します。画像はこちらからダウンロードできます[4]。
テキストとの類似性を描写することで、画像から学習された埋め込みは類似した視覚的な特徴に基づいて類似性を見つけるかもしれません。例えば、視覚的な埋め込みは、猫の耳、鼻、ひげを認識することを学習し、スコアが0.81となるかもしれません。一方、犬は猫とは異なる視覚的な特徴を持っているため、スコアは0.50となるかもしれません。ただし、選択された画像に基づいていくつかのバイアスがあるかもしれませんが、これは一般的な基本原則です。したがって、ビジュアル埋め込みは、画像のピクセルの近さを使用して意味のある関係を確立することを目指しています。

現実世界の応用:おすすめシステム、画像検索、類似性検索
III. 類似アイテムを見つけるために異なるタイプの埋め込みを使用する
先ほど、埋め込みは入力情報を圧縮された形式で表現する方法であると説明しました。この情報は、さまざまなテキスト属性からビジュアル属性まで、さまざまなタイプの情報である可能性があります。自然に、アイテムを記述するために使用できる属性が多いほど、類似性の信号は強くなります。
以下に、5つの食品アイテムのデータセットがあります。属性は私自身が作成し、Pillowライブラリを使用してスワッチの色を生成しました(スクリプトはこちらで探索できます)。データはこちらからダウンロードできます(製品画像は[5]によるもの)。
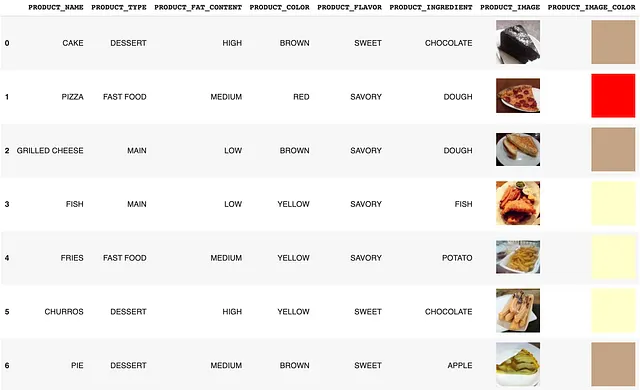
これらの属性のそれぞれについて、特定の属性を表す埋め込みベクトルを抽出することができます。これから自然に浮かぶ疑問は、何が類似していると見なされるのかということです。例えば、2つの文が類似していると見なされるかもしれませんが、それらを視覚化した場合、同じように見えるでしょうか?逆に、2つの動物は似ているかもしれませんが、特徴を使用してそれらを特徴づけると、それらはまだ似ているのでしょうか?これが私たちが利用できるさまざまなタイプの埋め込みを活用する機会があるところです。
まず、単語を単純に連結して「TEXTUAL_ATTR」という単一のテキスト特徴を作成します。ここでは単純な例を示していますが、実際のユースケースでは、連結する前にテキストデータをクリーンアップするために高度なNLP技術を適用する必要があります。

以下のGIFは、テキスト埋め込みまたはビジュアル埋め込みを考慮した場合に何が起こるかを示しています。


どちらのアプローチにも制限がありますが、上記で説明したように、機械学習のアンサンブルアプローチを利用することで、上記の埋め込みを組み合わせてアイテムに関するできるだけ多くの情報を提供することができます。これにより、より強力な類似性の信号を得ることができます。例えば、テキスト、商品画像、商品の色の埋め込みを使用して類似アイテムを見つけることができます。
では、すべての埋め込みを組み合わせた場合に何が起こるか見てみましょう!

実世界の応用例:推薦システム、代替検索
IV. 類似アイテムを見つけるために異なる重みを埋め込みに使用する
この概念は、IIIのポイントに基づいており、より柔軟な拡張です。以下の3つの異なるシナリオを考えましょう:
- Costcoで代替トースターを探しています。以前のトースターと同じ機能を求めています。この場合、トースターが以前のものと同じように見えるかどうかは気にしませんが、提供される機能(つまり、テキストの特徴)には興味があります。この場合、テキストの埋め込みのみを使用したいと思うでしょう
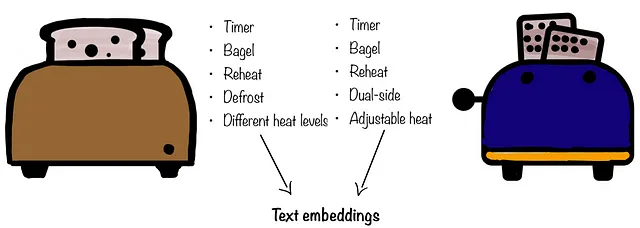
- お気に入りのパンツを破いてしまったため、できるだけ近い代替品を求めたいと思います。以前のパンツが持っていた一部の機能を犠牲にすることも覚悟していますが、外観や自分にどのように見えるかには興味があります。このシナリオでは、視覚的な埋め込みにより重みを高くし、テキストの埋め込みにやや低い重みを付けることができます。
- 与えられたデータには人間のモデルなどの背景要素が含まれている場合、興味のある実際の商品ではなく、人間のモデルの特徴を学習するリスクがあります。以下の例では、バスケットボールの特徴を学習したいのですが、モデルがそれを持っている様子を学習してしまう可能性があります。このような場合は、画像セグメンテーションの代わりに、全身画像の重みを低くし、テキストの属性や商品の色により重みを置くことで、所望の埋め込みを取得することができます。
![[6]による画像](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Fq9taYS1MDiiUFx-8m1fkQ.png)
これらのケースでは、異なる重みを使用することで、どの埋め込みセットが重要であり、それらをどのように操作するかに制御を与えることができます。このアイデアは、さまざまなタイプのビジネス問題を解決するための柔軟なシステムの構築に利用することができます。
実世界の応用例:バイアスの削減、調整可能な推薦システム、調整可能な類似性検索[7][8]
V. 画像とテキストの埋め込みを同じ空間に配置する(マルチモーダル)
これまでは、テキストとビジュアルデータを完全に別々の入力として扱ってきました。最も近いアプローチは、IIIのポイントで推論段階での効果を組み合わせることです。しかし、テキストと画像をオブジェクトとして考えるとどうでしょうか?これらのオブジェクトをどのように共通して表現しますか?
その答えがマルチモダリティとCLIP(Contrastive Language–Image Pre-training [9])です。マルチモダリティとは、異なるタイプのデータ(テキスト、画像、音声、数値)を組み合わせてより正確な予測を行うことを意味します。CLIPを使用することで、テキストや画像などのオブジェクトを数値ベクトル(埋め込み)として表現し、それらを同じ埋め込み空間に射影するのに役立ちます。
CLIPのマルチモーダルな性質の真の価値は、テキストと画像の類似する概念を類似のベクトルに変換することにあります。これらのベクトルは、それらの類似性に応じて近くに配置されます。つまり、テキストが画像の概念をうまく捉えている場合、そのテキストはその画像に近く配置されます。同様に、文でよく説明されている画像は、その文に近く配置されます。以下の例では、テキスト「犬がビーチで遊んでいる」は、犬がビーチで遊んでいる画像と似た埋め込みを出力します。
![類似のオブジェクト(テキスト、画像など)は、ベクトル空間内で近くにエンコードされます。GIF by author & images by [10]](https://miro.medium.com/v2/resize:fit:640/1*L-xy0aBKaJojlRXoXahs1g.gif)
上のイラストで見られるように、CLIPはテキストの意味と画像の視覚的な要素を組み合わせることで、テキストと画像のドメインを移動する能力を開放します(イメージからテキスト、テキストからイメージ)。また、テキストからテキストまたはイメージからイメージのような特定のドメイン内に留まることもできます。これにより、推薦システムから自動運転車、ドキュメント分類など、強力なアプリケーションの可能性が広がります!
HuggingFaceによるCLIPを使用したテキストからイメージの例を示しましょう。点IIIに示されているように、食品の画像[5]を使用します。アイデアは、テキストから直接画像に移動することです。
以下のビデオをご覧いただくか、こちらで自分自身で試してみてください!
上記のデモで素晴らしい結果が見られます!データセットには、食品のケーキの2つの画像が含まれています。「ケーキ」と検索すると、まずチョコレートケーキの画像が表示されます。しかし、「レッドベルベット」というより詳細なキーワードを追加すると、赤いベルベットのスライスが表示されます。これらの画像はどちらもある意味でケーキを表していましたが、モデルが認識したのは赤いベルベットケーキだけでした。同様に、「フィッシュアンドチップス」と検索すると、魚とフライドポテトのプレートが表示されますが、「チップス」と検索するとフライドポテトの箱が表示されます。さらに、フライドポテトとチュロスを見分けることもできます。
次に、同様の方法で画像からテキストへの変換を行いましょう。ここでは、点IIからの例[4]を使用して、画像が犬か猫かを分類します。
各画像について、テキストと画像の一致確率を取得します。猫の画像の場合、ラベル「猫」の確率が高くなります。一方、犬の画像は「犬」と分類されます。

実世界の応用:テキストからイメージ(検索)、イメージからイメージ(類似度)、イメージからテキスト(分類)
シリーズの第2部では、アートからクールな可視化まで、さらに多くの応用例を見ていきます。お楽しみに!
この記事が役に立った場合、他の人にも役立つと思われる場合は、拍手をしてください!連絡を取り合いたい場合は、こちらのLinkedInで見つけることができます。
Zubiaは、ファッションの製品開発、パーソナライゼーション、生成デザインに取り組むシニアマシンラーニングサイエンティストです。彼女は、コンピュータビジョン、データサイエンス、STEMにおける女性/有色人種の女性、テック業界でのキャリアに関連するトピックについて、メンター、インストラクター、スピーカーとして活動しています。
参考文献
[1]: 埋め込みの定義
[2]: 埋め込みの説明
[3]: BERTテキストエンコーダを使用したGoogleの検索エンジン
[4]: Dogs vs. Catsの画像(Kaggle)
[5]: Food Images(Food-101)の画像
[6]: Malik Skydsgaard氏による写真(Unsplash)
[7]: 異なるタイプの埋め込みの組み合わせ
[8]: 推薦システムのための埋め込み
[9]: OpenAIのCLIP
[10]: Oscar Sutton氏、Hossein Azarbad氏による画像
[11]: CLIPブログ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ツールの使用方法を言語モデルに教える
- 「LegalBenchとは:英語の大規模言語モデルにおける法的推論を評価するための共同構築されたオープンソースAIベンチマークです」
- 2023年9月にチェックすべき40以上のクールなAIツール
- メタAIは、「Code Llama」という最先端の大規模言語モデルをリリースしましたこれはコーディングのためのものです
- 大規模言語モデルの評価:包括的かつ客観的なテストのためのタスクベースAIフレームワーク、AgentSimsに会いましょう
- 「インクリメンタルラーニング:メリット、実装、課題」
- テキストによる画像および3Dシーン編集の高精度化:『Watch Your Steps』に出会う





