1時間以内に初めてのディープラーニングアプリを作成しましょう
1時間で初めてのディープラーニングアプリを作ろう
HuggingFace SpacesとGradioを使用して画像分類モデルを展開する
私はほぼ10年間データ分析を行ってきました。時折、機械学習の技術を使用してデータから洞察を得るため、クラシックな機械学習に慣れています。
ニューラルネットワークとディープラーニングに関するいくつかのMOOCを受講しましたが、これらを仕事で使用したことはありませんし、この領域は私にとってかなり挑戦的に思えました。私には以下のような先入観がありました:
- ディープラーニングを始めるためには多くの学習が必要です:数学、異なるフレームワーク(少なくとも「PyTorch」、「TensorFlow」、「Keras」という3つについて聞いたことがあります)およびネットワークのアーキテクチャ。
- モデルを適合させるには巨大なデータセットが必要です。
- パワフルなコンピューター(Nvidia GPUを搭載している必要もあります)なしでは、まともな結果を得ることは不可能ですので、セットアップを行うことは非常に困難です。
- MLをパワープラグインしたサービスをすぐに使えるようにするためには、多くの労力が必要です:フロントエンドとバックエンドの両方を取り扱う必要があります。
私は分析の主な目的はデータに基づいて製品チームが正しい意思決定をするのを助けることだと信じています。現在、ニューラルネットワークは私たちの分析を確かに改善することができます。例えば、NLPはテキストからはるかに多くの洞察を得るのに役立ちます。そのため、私はディープラーニングの力を活用するためにもう一度挑戦することが役立つと考えました。
それが私がFast.AIコースを始めた方法です(2022年の初めに更新されましたので、TDSの以前のレビューからコンテンツが変わったと思われます)。私は自分のタスクをディープラーニングを使って解決することはそれほど難しくないことに気づきました。
このコースはトップダウンのアプローチを取っています。つまり、動作するシステムの構築から始め、その後に必要な基礎とニュアンスを理解するためにより深く掘り下げます。
私は2週目に最初のMLパワードアプリを作成しました(こちらでお試しください)。これは私のお気に入りの犬の品種を識別できる画像分類モデルです。驚くべきことに、私のデータセットにはわずか数千の画像しかありませんが、うまく機能しています。10年前にはまるで魔法のように完全なサービスを構築できるようになったことに私は感銘を受けています。
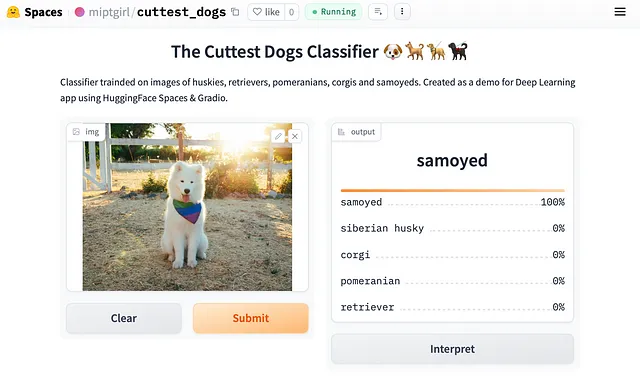
したがって、この記事では、機械学習によって動作する最初のサービスを構築して展開するための初心者向けチュートリアルを紹介します。
ディープラーニングとは何ですか?
ディープラーニングは、多層ニューラルネットワークをモデルとして使用する機械学習の特定のユースケースです。
ニューラルネットワークは非常に強力です。汎用近似定理によれば、ニューラルネットワークは任意の関数を近似することができるため、任意のタスクを解決することができます。
現時点では、このモデルは入力(私たちの場合は犬の画像)を受け取り、出力(私たちの場合はラベル)を返すブラックボックスとして扱ってください。

モデルの構築
このステージの完全なコードはKaggleで見つけることができます。
ディープラーニングモデルを構築するためにKaggle Notebooksを使用します。まだKaggleのアカウントをお持ちでない場合は、登録手続きを行う価値があります。Kaggleはデータサイエンティストに人気のあるプラットフォームで、データセットを見つけたり、コンペに参加したり、コードを実行して共有したりすることができます。
ここでは、Kaggleでノートブックを作成し、ローカルのJupyter Notebookと同じようにコードを実行できます。KaggleはGPUも提供しているため、NNモデルを比較的高速にトレーニングすることができます。
まずは、多くのFast.AIツールを使用するためにすべてのパッケージをインポートしましょう。
from fastcore.all import *from fastai.vision.all import *from fastai.vision.widgets import *from fastdownload import download_urlデータの読み込み
モデルを訓練するためにはデータセットが必要です。画像のセットを取得する最も簡単な方法は、検索エンジンを使用することです。
DuckDuckGo検索エンジンには使いやすいAPIと便利なPythonパッケージduckduckgo_search(詳細)がありますので、それを使用します。
犬の画像を検索してみましょう。Creative Commonsライセンスの画像のみを使用するため、license_image = anyと指定しています。
from duckduckgo_search import DDGSimport itertoolswith DDGS() as ddgs: res = list(itertools.islice(ddgs.images('photo samoyed happy', license_image = 'any'), 1))出力では、画像の名前、URL、サイズに関するすべての情報が得られました。
{ "title": "Happy Samoyed dog photo and wallpaper. Beautiful Happy Samoyed dog picture", "image": "http://www.dogwallpapers.net/wallpapers/happy-samoyed-dog-wallpaper.jpg", "thumbnail": "https://tse2.mm.bing.net/th?id=OIP.BqTE8dYqO-W9qcCXdGcF6QHaFL&pid=Api", "url": "http://www.dogwallpapers.net/samoyed-dog/happy-samoyed-dog-wallpaper.html", "height": 834, "width": 1193, "source": "Bing"}これで、Fast.AIツールを使用して画像をダウンロードし、サムネイルを表示することができます。
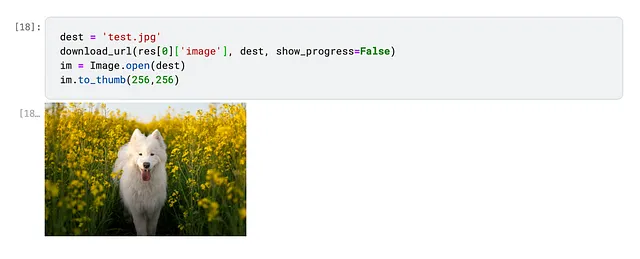
ハッピーなサモエドが表示されているので、正常に動作していることがわかります。さらに写真を読み込みましょう。
私は5つの異なる犬種(私のお気に入り)を識別することを目指しています。各犬種の写真を読み込み、別々のディレクトリに保存します。
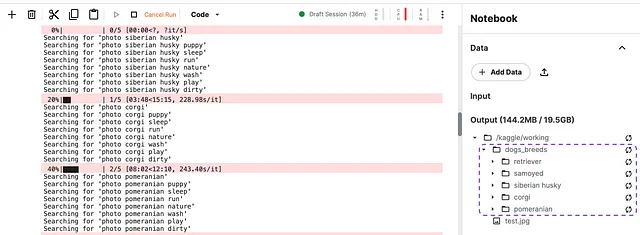
breeds = ['siberian husky', 'corgi', 'pomeranian', 'retriever', 'samoyed']path = Path('dogs_breeds') # パスを定義するfor b in tqdm.tqdm(breeds): dest = (path/b) dest.mkdir(exist_ok=True, parents=True) download_images(dest, urls=search_images(f'photo {b}')) sleep(10) download_images(dest, urls=search_images(f'photo {b} puppy')) sleep(10) download_images(dest, urls=search_images(f'photo {b} sleep')) sleep(10) resize_images(path/b, max_size=400, dest=path/b)このコードを実行すると、Kaggleの右パネルにすべての読み込まれた写真が表示されます。
次のステップは、データをFast.AIモデルに適した形式であるDataBlockに変換することです。
このオブジェクトに指定する必要があるいくつかの引数がありますが、最も重要なものだけを強調します:
splitter=RandomSplitter(valid_pct=0.2, seed=18):Fast.AIでは、検証セットを選択する必要があります。検証セットはモデルの品質を推定するために使用される保持データです。検証データは過学習を防ぐためにトレーニング中に使用されません。今回はデータセットのランダムな20%を検証セットとしました。同じ分割を再現できるようにseedパラメータを指定しました。item_tfms=[Resize(256, method='squish')]:ニューラルネットワークはバッチごとに画像を処理します。そのため、同じサイズの画像を用意する必要があります。画像のリサイズにはさまざまなメソッドがありますが、現時点では’スクイッシュ’を使用しました。後ほど詳しく説明します。
データブロックを定義しました。関数show_batchは、ランダムな画像とラベルを表示することができます。
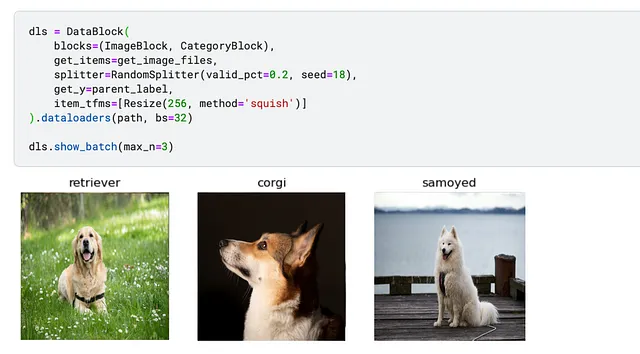
データは大丈夫なので、トレーニングを進めましょう。
モデルのトレーニング
<p驚かれるかもしれませんが、以下の2行のコードだけですべての作業が行われます。
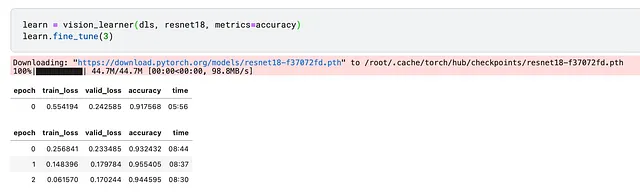
事前学習済みモデル(18層のディープレイヤーを持つ畳み込みニューラルネットワーク、Resnet18)を使用しました。そのため、関数fine_tuneを呼び出しました。
<pモデルを3エポックトレーニングしました。これは、モデルがデータセット全体を3回見たことを意味します。
また、メトリックであるaccuracy(正しくラベル付けされた画像の割合)を指定しました。各エポックの後にこのメトリックが結果に表示されます(結果を歪めないように、検証セットのみを使用して計算されます)。ただし、最適化プロセスでは使用されず、情報提供のみです。
全体のプロセスは約30分かかり、現在モデルは94.45%の正確さで犬の品種を予測することができます。お疲れ様でした!しかし、この結果を改善することはできるでしょうか?
モデルの改善:データのクリーニングと拡張
できるだけ早く最初のモデルを動作させたい場合は、このセクションを後回しにしてモデルのデプロイメントに移動しても構いません。
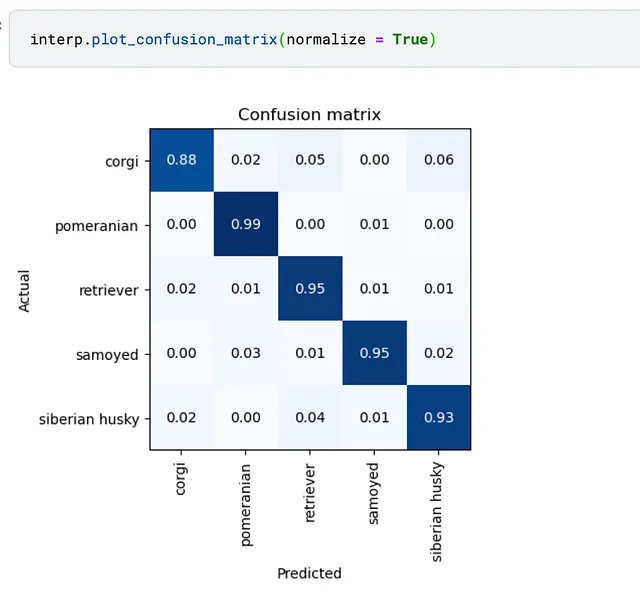
まず、モデルのエラーを確認しましょう。コーギーとハスキー、ポメラニアンとレトリバーを区別できないかどうかを確認できます。それにはconfusion_matrixを使用できます。注意:混同行列も検証セットのみを使用して計算されます。
Fast.AIコースで共有されているもう1つのライフハックは、モデルをデータのクリーニングに使用できることです。そのために、最も損失の大きい画像を見ることができます:モデルが高い確信度で誤っているか、または低い確信度ですが正しい場合です。
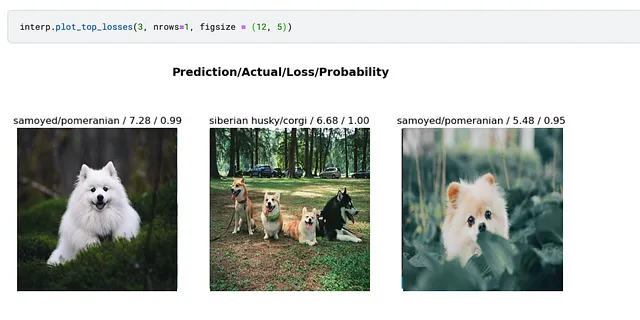
明らかに、最初の画像は間違ったラベルを持っているようですが、2番目の画像にはハスキーとコーギーの両方が含まれています。改善の余地があります。
<p幸いなことに、Fast.AIには便利なImageClassifierCleanerウィジェットがあり、データの問題を素早く修正するのに役立ちます。ノートブックで初期化することができ、その後データセットのラベルを変更できます。
cleaner = ImageClassifierCleaner(learn)cleaner<p各カテゴリーの後に、以下のコードを実行して問題を修正できます:画像を削除するか、正しいフォルダに移動します。
for idx in cleaner.delete(): cleaner.fns[idx].unlink()for idx,breed in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/breed)<p今度はモデルを再トレーニングし、正確性が向上したことを確認できます:95.4%対94.5%。
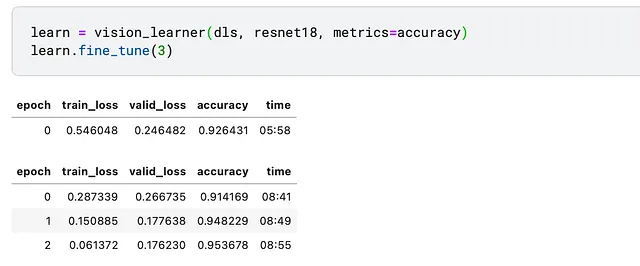
正しく識別されたコーギーの割合が88%から96%に増加しました。素晴らしい!
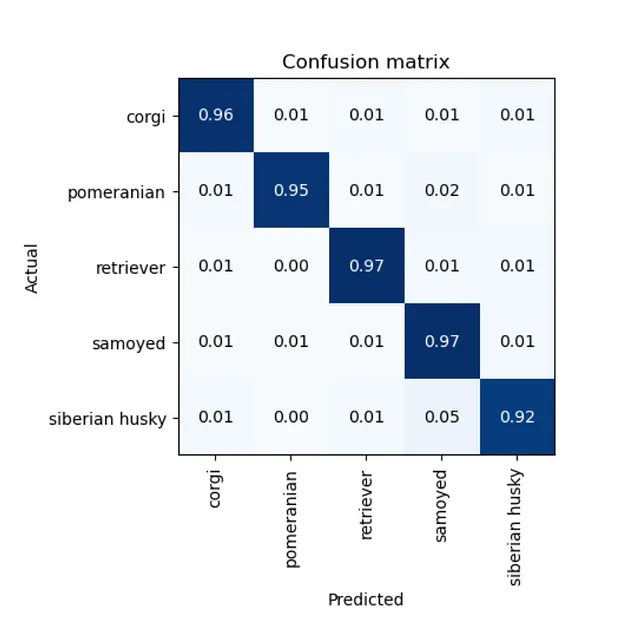
モデルを改善するもう一つの方法は、リサイズのアプローチを変えることです。私たちはスクイッシュメソッドを使用しましたが、自然物の比率を変える可能性があります。より想像力を働かせて、オーグメンテーションを使用してみましょう。
オーグメンテーションは画像の変更(たとえば、コントラストの改善、回転、切り抜きなど)です。これにより、モデルにより多様なデータが提供され、品質が向上することを期待しています。
Fast.AIではいつものように、オーグメンテーションを追加するためのパラメーターをいくつか変更する必要があります。
また、オーグメンテーションを使用すると、各エポックでわずかに異なる画像がモデルに表示されるため、エポック数を増やすことができます。6エポック後、95.65%の精度を達成しました – より良い結果です。全体のプロセスには約1時間かかりました。
モデルのダウンロード
最後のステップは、モデルをダウンロードすることです。非常に簡単です。
learn.export('cuttest_dogs_model.pkl')そうすると、標準のpickleファイル(オブジェクトを保存するための共通のPython形式)が保存されます。Kaggle Notebookの右パネルにあるファイルの隣にあるその他のアクションを選択するだけで、モデルをコンピューターに取得できます。
これでトレーニングされたモデルができたので、結果を世界と共有するためにデプロイしましょう。
モデルのデプロイ
HuggingFace SpacesとGradioを使用して、Webアプリを構築します。
HuggingFace Spaceの設定
HuggingFaceは、機械学習の便利なツールを提供する企業であり、人気のあるtransformersライブラリやモデルとデータセットを共有するためのツールなどがあります。今日は、彼らのSpacesを使用してアプリケーションをホストします。
まず、まだ登録していない場合はアカウントを作成する必要があります。数分でできます。このリンクに従ってください。
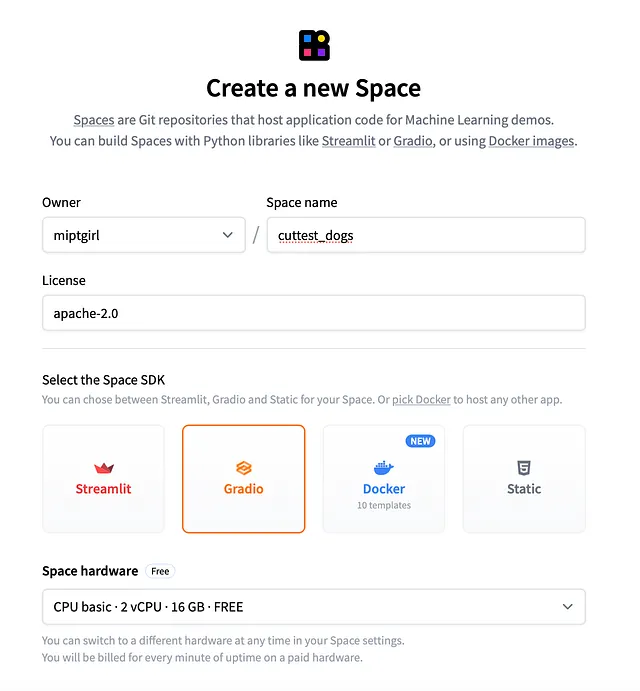
そして、新しいSpaceを作成する時間です。Spacesタブに移動し、「作成」ボタンを押します。詳細な指示はドキュメントにあります。
次に、以下のパラメーターを指定する必要があります:
- 名前(アプリのURLに使用されるため、慎重に選んでください)
- ライセンス(オープンソースのApache 2.0ライセンスを選択しました)
- SDK(この例ではGradioを使用します)。
その後、使いやすいHuggingFaceが指示を表示します。簡単に言うと、今やGitリポジトリが作成され、コードをコミットする必要があります。
Gitには1つのニュアンスがあります。モデルがかなり大きいため、Git LFS(Large File Storage)を設定する方が良いです。インストール方法は、サイトの指示に従ってください。
-- cloning repogit clone https://huggingface.co/spaces/<your_login>/<your_app_name>cd <your_app_name>-- setting up git-lfsgit lfs installgit lfs track "*.pkl"git add .gitattributesgit commit -m "update gitattributes to use lfs for pkl files"Gradio
Gradioは、Pythonだけを使って快適で使いやすいWebアプリを構築するためのフレームワークです。それが私のようなJavaScriptの知識が深くない人にとっては非常に便利なツールです。
Gradioでは、以下のパラメータを指定してインターフェースを定義します:
- input — 画像
- output — 5つの可能なクラスのラベル
- title、description および 例のセットの画像(リポジトリにもコミットする必要があります)
enable_queue=Trueは、アプリが非常に人気が出て大量のトラフィックを処理するのをサポートします- function — 入力画像に対して実行される関数
入力画像のラベルを取得するためには、モデルをロードし、各クラスの確率を持つ辞書を返す予測関数を定義する必要があります。
最終的に、app.py の以下のコードが得られます:
import gradio as grfrom fastai.vision.all import *learn = load_learner('cuttest_dogs_model.pkl')labels = learn.dls.vocab # モデルのクラスのリストdef predict(img): img = PILImage.create(img) pred,pred_idx,probs = learn.predict(img) return {labels[i]: float(probs[i]) for i in range(len(labels))}gr.Interface( fn=predict, inputs=gr.inputs.Image(shape=(512, 512)), outputs=gr.outputs.Label(num_top_classes=5), title="最も可愛い犬の分類器 🐶🐕🦮🐕🦺", description="ハスキー、レトリーバー、ポメラニアン、コーギー、サモエドの画像でトレーニングされた分類器。HuggingFace SpacesとGradioを使用したディープラーニングアプリのデモとして作成されました。", examples=['husky.jpg', 'retriever.jpg', 'corgi.jpg', 'pomeranian.jpg', 'samoyed.jpg'], enable_queue=True).launch()Gradioについてさらに学びたい場合は、ドキュメントを参照してください。
また、requirements.txt ファイルを作成し、fastai を記述しておくと、このライブラリがサーバーにインストールされます。
あとはすべてをHuggingFace Gitリポジトリにプッシュするだけです。
git add * git commit -am '最初のバージョンの最も可愛い犬アプリ'git pushGitHubで完全なコードを見つけることができます。
ファイルをプッシュした後、HuggingFace Spaceに戻ると、ビルドプロセスを示す類似の画像が表示されます。すべてが正常な場合、アプリは数分で実行されます。
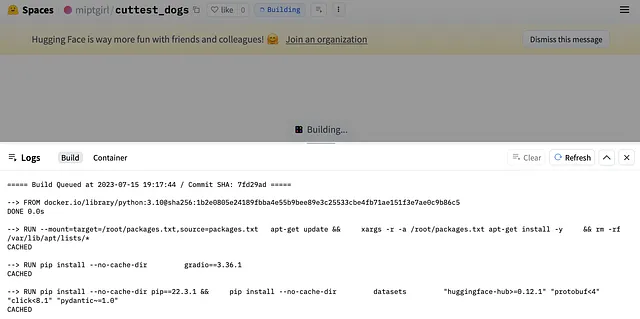
問題が発生した場合は、スタックトレースが表示されます。その場合はコードに戻り、バグを修正し、新しいバージョンをプッシュし、数分待つ必要があります。
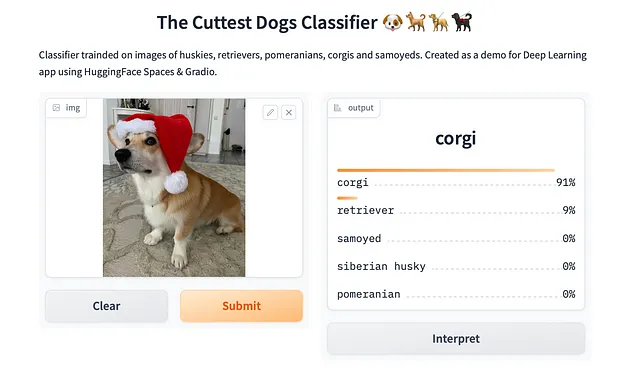
動作しています
これで、実際の写真でこのモデルを使用することができます。例えば、私の家族の犬が本当にコーギーであるかどうかを確認するために使用できます。
今日は、データセットの取得からモデルのフィッティング、Webアプリの作成とデプロイまで、ディープラーニングアプリケーションの全体的なプロセスを経験しました。このチュートリアルを完了できたことを願っています。そして、今は素晴らしいモデルを本番環境でテストしていることでしょう。
この記事を読んでいただき、ありがとうございました。お役に立てたかどうか、フィードバックや質問がありましたら、コメントセクションにお願いします。また、アプリのリンクを共有することもお気軽にどうぞ。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 新しいAIメソッド、StyleAvatar3Dによるスタイル化された3Dアバターの生成画像テキスト拡散モデルとGANベースの3D生成ネットワークを使用
- 「OpenAIは、パーソナライズされたAIインタラクションのためのChatGPTのカスタムインストラクションを開始」
- 「CHARMに会ってください:手術中に脳がんのゲノムを解読し、リアルタイムの腫瘍プロファイリングを行う新しい人工知能AIツール」
- 「SwiggyがZomatoとBlinkitに続き、生成AIを統合する」
- 「私たちはLLMがツールを使うことを知っていますが、LLMが新しいツールを作ることもできることを知っていますか? LLMツールメーカー(LATM)としての出会い:LLMが自分自身の再利用可能なツールを作ることを可能にするクローズドループシステム」
- 類似検索、パート6:LSHフォレストによるランダム射影
- このAI論文では、「Retentive Networks(RetNet)」を大規模言語モデルの基礎アーキテクチャとして提案していますトレーニングの並列化、低コストの推論、そして良好なパフォーマンスを実現しています






