1日に150億のログを処理し、ビッグクエリを1秒以内に完了させる方法
1日150億ログを処理し、ビッグクエリを1秒以内に完了する方法
このデータウェアハウスのユースケースはスケールについてです。ユーザーは中国ユニコムであり、世界最大の通信サービスプロバイダーの1つです。Apache Dorisを使用して、30以上のビジネスラインから1日150億件のログを追加するために複数のペタバイトスケールのクラスターを数十台のマシンに展開しています。このような巨大なログ分析システムは、彼らのサイバーセキュリティ管理の一部です。リアルタイムのモニタリング、脅威の追跡、アラート機能のために、ログとイベントレコードを自動的に収集、保存、分析、可視化するログ分析システムが必要です。
アーキテクチャの観点から、システムはさまざまな形式のログのリアルタイム分析を行うことができる必要があります。もちろん、巨大で増大し続けるデータサイズをサポートするためにスケーラブルである必要があります。この記事の残りは、彼らのログ処理アーキテクチャの概要と、安定したデータ取り込み、低コストのストレージ、迅速なクエリの実現方法について説明します。
システムアーキテクチャ
- 「ブラックボックスの解除:ディープニューラルネットワークにおけるデータ処理の理解のための定量的法則」
- 「トップデータプライバシーツール2023」
- 「Pythonを使用した地理空間データの分析(パート2 – 仮説検定)」
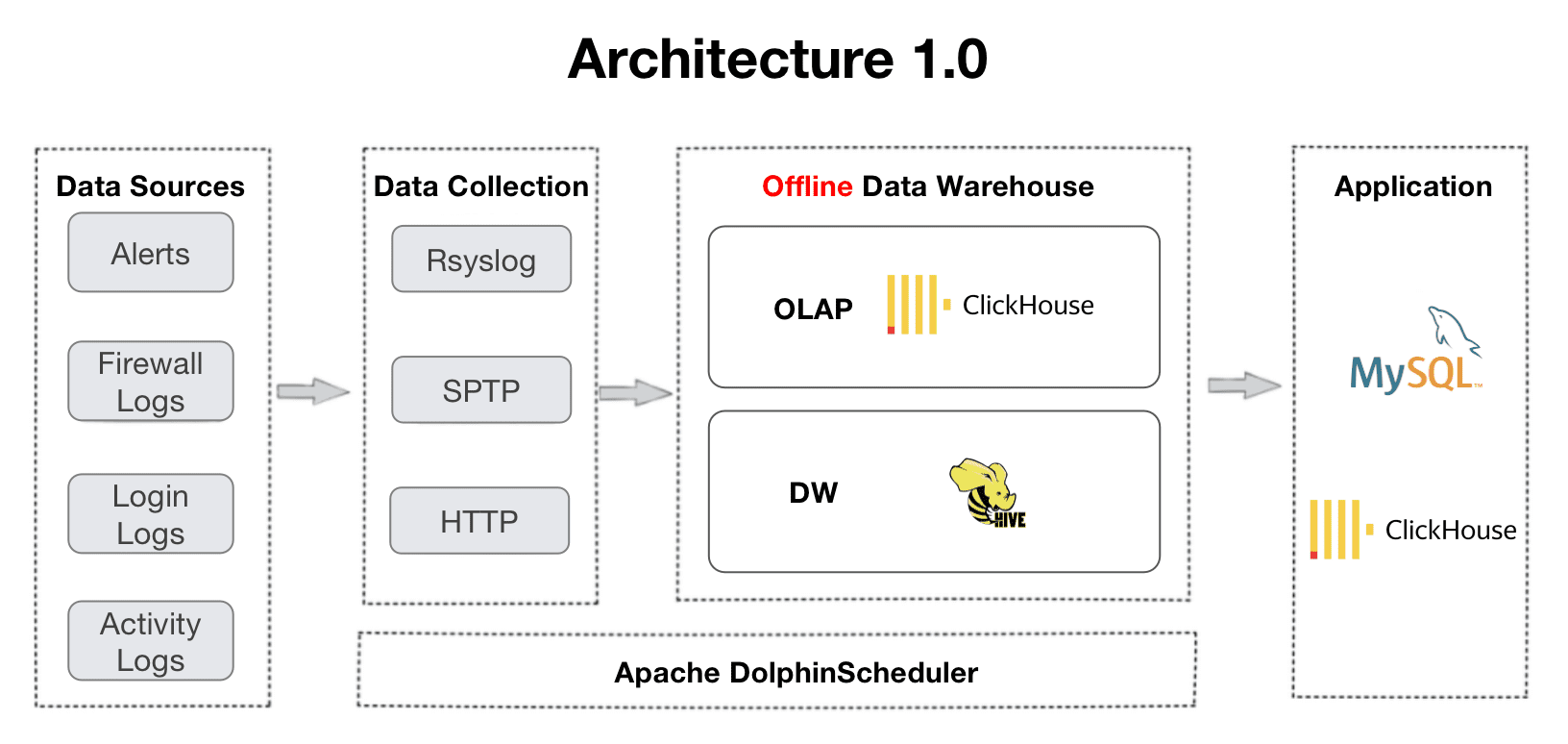
これは彼らのデータパイプラインの概要です。ログはデータウェアハウスに収集され、いくつかの処理レイヤーを経ています。
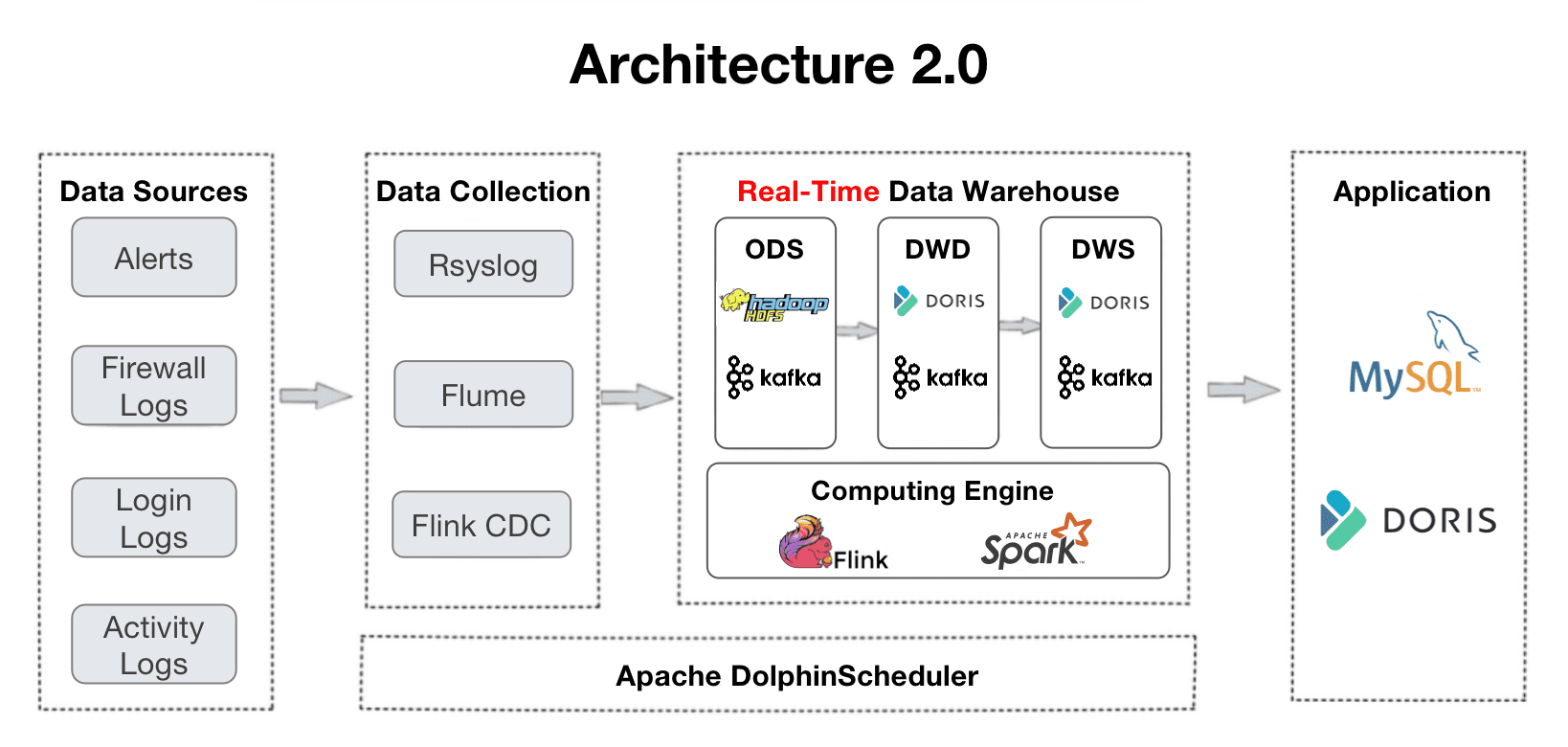
- ODS:すべてのソースからの元のログとアラートはApache Kafkaに集められます。同時に、それらのコピーはデータの検証や再生のためにHDFSに保存されます。
- DWD:これが事実テーブルがある場所です。Apache Flinkはデータをクリーンにし、標準化し、バックフィルし、匿名化し、それをKafkaに書き戻します。これらの事実テーブルはApache Dorisにも配置されますので、Dorisは特定のアイテムを追跡したり、ダッシュボードやレポート作成に使用したりすることができます。ログは重複する可能性があるため、事実テーブルはApache DorisのDuplicate Keyモデルで配置されます。
- DWS:このレイヤーはDWDからデータを集約し、クエリと分析の基盤を築きます。
- ADS:このレイヤーでは、Apache DorisはそのAggregate Keyモデルを使用してデータを自動的に集計し、Unique Keyモデルを使用してデータを自動的に更新します。
アーキテクチャ2.0は、ClickHouseとApache Hiveによってサポートされているアーキテクチャ1.0から進化しました。この移行は、リアルタイムデータ処理と複数テーブルの結合クエリへのユーザーのニーズから生じました。古いアーキテクチャの経験から、ダッシュボードでの頻繁なタイムアウトや分散結合でのOOMエラーなど、並行性と複数テーブル結合のサポートが不十分であることがわかりました。
では、アーキテクチャ2.0におけるデータの取り込み、ストレージ、クエリの実践を見てみましょう。
実践事例
1日150億件のログの安定した取り込み
このユーザーの場合、彼らのビジネスは1日に150億件のログを生成します。このようなデータボリュームを迅速かつ安定して取り込むことは実際の問題です。Apache Dorisを使用する場合、推奨される方法はFlink-Doris-Connectorを使用することです。これはApache Dorisコミュニティによって大規模データ書き込み用に開発されたものです。このコンポーネントは簡単な構成が必要です。ストリームロードを実装し、データ分析のワークロードを中断することなく、秒間20万〜30万件のログを書き込む速度を達成することができます。
経験から学んだ教訓は、高頻度の書き込みにFlinkを使用する場合、データバージョンの蓄積を避けるためにケースに適したパラメータ構成を見つける必要があるということです。この場合、ユーザーは以下の最適化を行いました:
- Flink Checkpoint:チェックポイント間隔を15秒から60秒に増やし、書き込み頻度と単位時間あたりにDorisが処理するトランザクション数を減らします。これにより、データの書き込み圧力が軽減され、多くのデータバージョンが生成されるのを防ぐことができます。
- データの事前集計:同じIDのデータがさまざまなテーブルから来る場合、Flinkは主キーIDに基づいてデータを事前集計し、フラットなテーブルを作成します。これにより、マルチソースデータの書き込みによる過剰なリソース消費を防ぐことができます。
- Dorisのコンパクション:適切なDorisバックエンド(BE)パラメータを見つけて、データコンパクションに適切なCPUリソースを割り当て、適切なデータパーティション、バケツ、およびレプリカの数を設定する(データタブレットが多すぎると大きなオーバーヘッドが発生するため)、およびバージョンの蓄積を避けるためにmax_tablet_version_numを調整することです。
これらの対策は、日々のデータの安定した取り込みを保証します。ユーザーは、Dorisバックエンドでの安定したパフォーマンスと低い圧縮スコアを目撃しています。さらに、Flinkにおけるデータの前処理とDorisにおけるユニークキーモデルの組み合わせにより、より迅速なデータの更新が保証されます。
コストを50%削減するためのストレージ戦略
ログのサイズと生成率は、ストレージに圧力をかけます。膨大なログデータの中で、情報価値の高い部分だけが存在するため、ストレージは差別化されるべきです。ユーザーは、コストを削減するために3つのストレージ戦略を持っています。
- ZSTD(ZStandard)圧縮アルゴリズム:1TB以上のテーブルに対して、テーブルの作成時に圧縮方法を「ZSTD」と指定すると、圧縮率10:1が実現されます。
- ホットデータとコールドデータの階層化ストレージ:これはDorisの新機能によってサポートされています。ユーザーは「冷却」期間を7日に設定します。つまり、過去7日間のデータ(つまり、ホットデータ)はSSDに格納されます。時間が経つにつれて、ホットデータは「冷えていき」(7日以上前のデータになる)HDDに自動的に移動されます。HDDはより安価です。さらに、「さらに冷たくなった」データは、オブジェクトストレージに移動され、格納コストがさらに低くなります。さらに、オブジェクトストレージでは、データは3つのコピーではなく1つのコピーで格納されます。これにより、コストが削減され、冗長なストレージによってもたらされるオーバーヘッドが軽減されます。
- 異なるデータパーティションに対する異なるレプリカ数:ユーザーはデータを時間範囲でパーティション分割しています。原則として、新しいデータパーティションにはより多くのレプリカがあり、古いデータパーティションにはより少ないレプリカがあります。彼らの場合、過去3ヶ月のデータは頻繁にアクセスされるため、このパーティションには2つのレプリカがあります。3〜6ヶ月前のデータには2つのレプリカがあり、6ヶ月前のデータには1つの単一のコピーがあります。
これらの3つの戦略により、ユーザーはストレージコストを50%削減しました。
データサイズに基づく異なるクエリ戦略
一部のログは即座に追跡および特定する必要があります。例えば、異常イベントや障害のログです。これらのクエリに対するリアルタイムな応答を確保するために、ユーザーは異なるデータサイズに対して異なるクエリ戦略を持っています:
- 100G未満:ユーザーはDorisの動的パーティショニング機能を利用しています。小さなテーブルは日付でパーティション分割され、大きなテーブルは時間でパーティション分割されます。これにより、データの偏りを回避できます。データパーティション内のバランスをさらに確保するために、ユーザーはスノーフレークIDをバケット化フィールドとして使用しています。また、開始オフセットも設定しています。最近の20日間のデータは保持されます。これは、データの積み残しと分析ニーズのバランスポイントです。
- 100G〜1T:これらのテーブルには、Dorisに格納された事前計算結果セットであるマテリアライズドビューがあります。したがって、これらのテーブルへのクエリははるかに高速でリソース消費が少なくなります。DorisでのマテリアライズドビューのDDL構文は、PostgreSQLとOracleと同じです。
- 100T以上:これらのテーブルは、Apache Dorisの集約キーモデルに配置され、事前集約されます。これにより、20億行のログレコードのクエリを1〜2秒で実行することが可能になります。
これらの戦略により、クエリの応答時間が短縮されました。たとえば、特定のデータアイテムのクエリは以前は数分かかっていましたが、現在はミリ秒で完了するようになりました。さらに、100億のデータレコードを含む大きなテーブルに対して、異なる次元のクエリはすべて数秒で実行できます。
進行中の計画
ユーザーは現在、Apache Dorisに新たに追加された逆インデックスをテストしています。これは、文字列の全文検索、数値および日時の等価性および範囲クエリの高速化を目的として設計されています。また、ユーザーはDorisの自動バケット分割ロジックに関する貴重なフィードバックも提供しています。現在、Dorisは前のパーティションのデータサイズに基づいてパーティションごとのバケット数を決定しています。ユーザーの問題は、ほとんどの新しいデータが昼間に入るため、夜間にはほとんど入らないということです。したがって、ユーザーの場合、Dorisは夜間のデータに対して余分なバケットを作成しすぎており、昼間には十分なバケットを作成していません。彼らは、Dorisがバケットの数を決定するための参照として、前日のデータサイズと分布を使用する新しい自動バケット分割ロジックを追加したいと考えています。彼らはApache Dorisコミュニティに参加し、現在この最適化に取り組んでいます。 Zaki Lu は、Baiduの元製品マネージャーであり、現在はApache DorisオープンソースコミュニティのDevRelです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
