🤗 Transformersにおけるネイティブサポートされた量子化スキームの概要
🤗 Transformersにおける量子化スキームの概要
私たちは、トランスフォーマーでサポートされている各量子化スキームの利点と欠点を明確に示し、どれを選ぶべきかを判断するのに役立つ概要を提供することを目指しています。
現在、モデルの量子化は主に2つの目的で使用されています:
- 大きなモデルの推論をより小さなデバイスで実行すること
- 量子化モデルの上にアダプタを微調整すること
現時点で、2つの統合の取り組みが行われ、トランスフォーマーでネイティブにサポートされています:bitsandbytesとauto-gptqです。なお、🤗オプティマムライブラリでは他の量子化スキームもサポートされていますが、このブログ投稿では対象外です。
サポートされている各スキームの詳細については、以下で共有されているリソースのいずれかをご覧ください。また、ドキュメントの適切なセクションもご確認ください。
また、以下で共有されている詳細は、PyTorchモデルにのみ有効であり、TensorflowおよびFlax/JAXモデルについては現在のところ対象外です。
目次
- リソース
- bitsandbyesとauto-gptqの利点と欠点
- 速度ベンチマークの詳細
- 結論と最終的な言葉
- 謝辞
リソース
- GPTQブログ投稿 – GPTQ量子化方法と使用方法について概説しています。
- bitsandbytes 4ビット量子化ブログ投稿 – このブログ投稿では4ビット量子化と効率的なファインチューニング手法であるQLoRaについて紹介しています。
- bitsandbytes 8ビット量子化ブログ投稿 – このブログ投稿ではbitsandbytesとの8ビット量子化の仕組みについて説明しています。
- GPTQの基本的な使用法Google Colabノートブック – このノートブックでは、GPTQ方法でトランスフォーマーモデルを量子化し、推論を行い、量子化されたモデルでのファインチューニングを行う方法を示しています。
- bitsandbytesの基本的な使用法Google Colabノートブック – このノートブックでは、すべてのバリアントを使用した4ビットモデルの推論方法や、20BパラメータモデルであるGPT-neo-Xを無料のGoogle Colabインスタンス上で実行する方法を示しています。
- 量子化に関するMerveのブログ投稿 – このブログ投稿では、量子化とトランスフォーマーでネイティブにサポートされている量子化方法について、わかりやすく紹介しています。
bitsandbyesとauto-gptqの利点と欠点
このセクションでは、bitsandbytesとgptqの量子化の利点と欠点について説明します。これらはコミュニティからのフィードバックに基づいており、これらの機能のいくつかは各ライブラリのロードマップに含まれるため、時間とともに変化する可能性があります。
bitsandbytesの利点
簡単:bitsandbytesは、入力データ(ゼロショット量子化とも呼ばれる)で量子化モデルをキャリブレーションする必要がないため、どんなモデルでも簡単に量子化できる方法です。 torch.nn.Linearモジュールを含んでいる限り、新しいアーキテクチャがトランスフォーマーに追加されるたびに、accelerateのdevice_map="auto"でロードできる限り、bitsandbytesの量子化を最小限の性能低下で直ちに利用できます。量子化はモデルのロード時に実行されるため、ポストプロセッシングや準備の手順は必要ありません。
クロスモダリティの相互運用性:モデルを量子化する唯一の条件は、torch.nn.Linearレイヤーを含んでいることですので、どんなモダリティでも量子化はそのままで可能であり、Whisper、ViT、Blip2などのモデルを8ビットまたは4ビットでロードすることができます。
アダプタのマージ時のパフォーマンス低下なし:(アダプタとPEFTについては、このブログ投稿で詳しく説明しています)。量子化されたベースモデルの上にアダプタをトレーニングした場合、アダプタはデプロイメントのためにベースモデルの上にマージでき、推論のパフォーマンスは低下しません。デクォンタイズされたモデルの上にもアダプタをマージすることができます!これはGPTQではサポートされていません。
autoGPTQの利点
テキスト生成において高速:GPTQ量子化されたモデルは、テキスト生成においてbitsandbytes量子化されたモデルと比べて速いです。適切なセクションでスピード比較について説明します。
n-bitサポート:GPTQアルゴリズムにより、モデルを2ビットまで量子化することが可能になりました!ただし、これには厳しい品質の低下が伴う場合があります。推奨されるビット数は4であり、現時点ではGPTQにとって素晴らしいトレードオフとなっています。
簡単にシリアライズ可能:GPTQモデルは、任意のビット数に対してシリアライズをサポートしています。TheBloke名前空間からモデルをロードすることができます:https://huggingface.co/TheBloke(-GPTQで終わるモデルを探してください)。必要なパッケージがインストールされている限り、そのままサポートされます。Bitsandbytesは8ビットのシリアライズをサポートしていますが、現時点では4ビットのシリアライズはサポートされていません。
AMDサポート:統合はAMD GPUに対してそのまま動作するはずです!
bitsandbytesのデメリット
テキスト生成においてGPTQよりも遅い:bitsandbytesの4ビットモデルは、generateを使用した場合にGPTQに比べて遅いです。
4ビットの重みはシリアライズできません:現在、4ビットのモデルはシリアライズできません。これはコミュニティからの頻繁な要望であり、bitsandbytesのメンテナンス担当者が近々対応するべきだと考えています。
autoGPTQのデメリット
キャリブレーションデータセットが必要:GPTQを選択することを躊躇させる要因の一つとして、キャリブレーションデータセットが必要となることがあります。また、モデルの量子化には数時間かかる場合があります(例:180Bモデルの場合、4 GPU時間がかかる)
今のところ言語モデルのみ対応:現時点では、auto-GPTQを使用してモデルを量子化するためのAPIは言語モデルのみをサポートするように設計されています。GPTQアルゴリズムを使用して非テキスト(またはマルチモーダル)モデルを量子化することは可能であるはずですが、オリジナルの論文やauto-gptqのリポジトリで詳細が記述されていません。コミュニティがこのトピックに興味を持っている場合、将来的に考慮される可能性があります。
速度ベンチマークについて詳しく
bitsandbytesとauto-gptqを使用した推論とファインチューニングアダプタの広範なベンチマークを提供することにしました。推論において提案された異なるアプローチの速度の違いをユーザーに示し、bitsandbytesとGPTQベースモデルの上にアダプタをファインチューニングする際にどのアプローチを使用するかを決定する際にはっきりとしたアイデアをユーザーに提供します。
以下のセットアップを使用します:
- bitsandbytes:4ビットの量子化で、
bnb_4bit_compute_dtype=torch.float16を使用します。高速な4ビットカーネルにはbitsandbytes>=0.41.1を使用してください。 - auto-gptq:exllamaカーネルを使用した4ビットの量子化。ex-llamaカーネルを使用するには
auto-gptq>=0.4.0が必要です。
推論速度(フォワードパスのみ)
このベンチマークは、トレーニング中のフォワードパスに対応するプリフィルステップのみを測定しています。プロンプトの長さは512で、単一のNVIDIA A100-SXM4-80GB GPUで実行されました。使用したモデルはmeta-llama/Llama-2-13b-hfです。
バッチサイズ=1の場合:
バッチサイズ=16の場合:
ベンチマークからは、bitsandbyesとGPTQが同等であり、大きなバッチサイズに対してはGPTQの方がわずかに速いことがわかります。これらのベンチマークの詳細については、以下のリンクを参照してください。
生成速度
以下のベンチマークは、モデルの推論時の生成速度を測定しています。再現性のために、ベンチマークスクリプトはこちらで参照できます。
use_cache
生成中に隠れ状態をキャッシュすることの影響をよりよく理解するために、use_cacheをテストしてみましょう。
このベンチマークは、プロンプトの長さが30で、30トークンを生成したA100で実行されました。使用したモデルはmeta-llama/Llama-2-7b-hfです。
use_cache=Trueを使用して
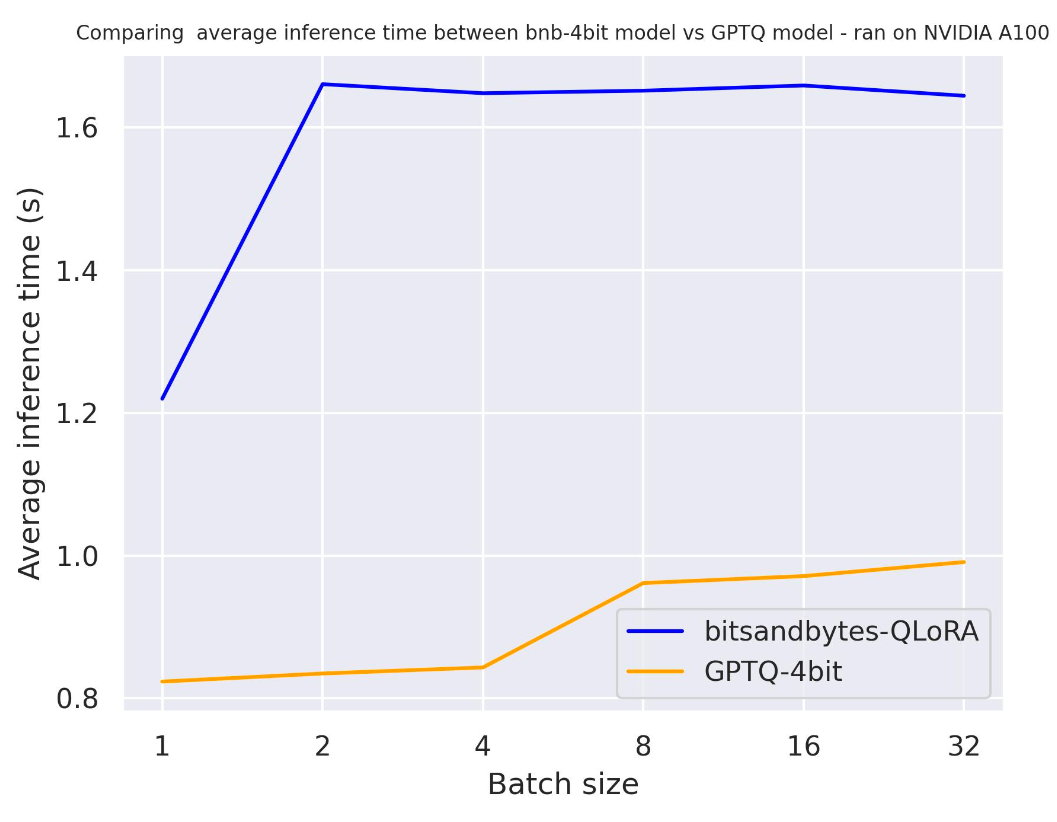
use_cache=Falseを使用して
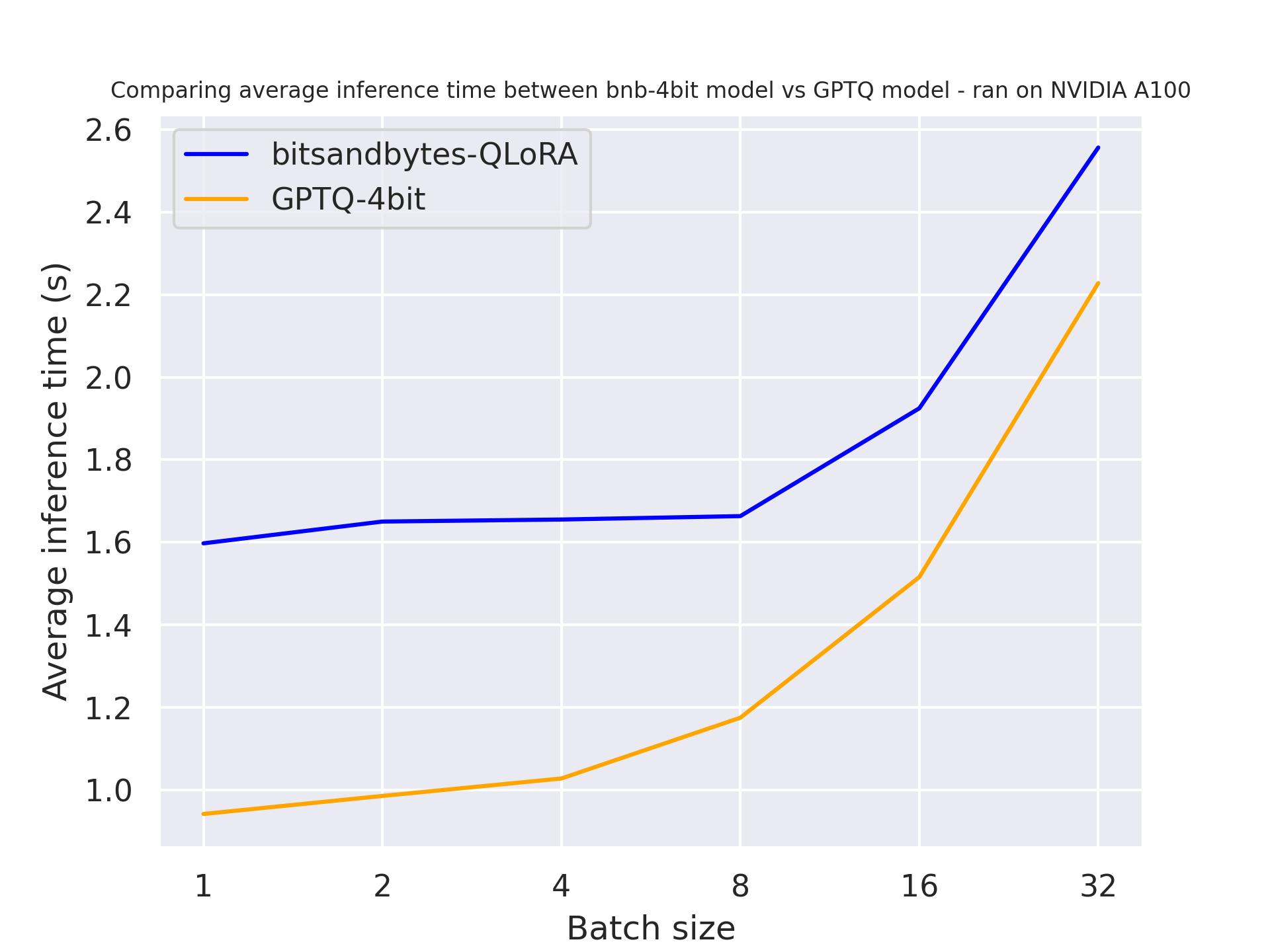
2つのベンチマークから、期待通り、注意キャッシングを使用すると生成がより速くなることがわかります。さらに、GPTQは一般的にbitsandbytesよりも速いです。例えば、batch_size=4およびuse_cache=Trueの場合、2倍の速さです!したがって、次のベンチマークではuse_cacheを使用しましょう。ただし、use_cacheを使用するとメモリを消費します。
ハードウェア
次のベンチマークでは、異なるハードウェアを試して、量子化モデルへの影響を確認します。プロンプトの長さは30で、正確に30トークンを生成しました。使用したモデルはmeta-llama/Llama-2-7b-hfです。
NVIDIA A100を使用して:
NVIDIA T4を使用して:
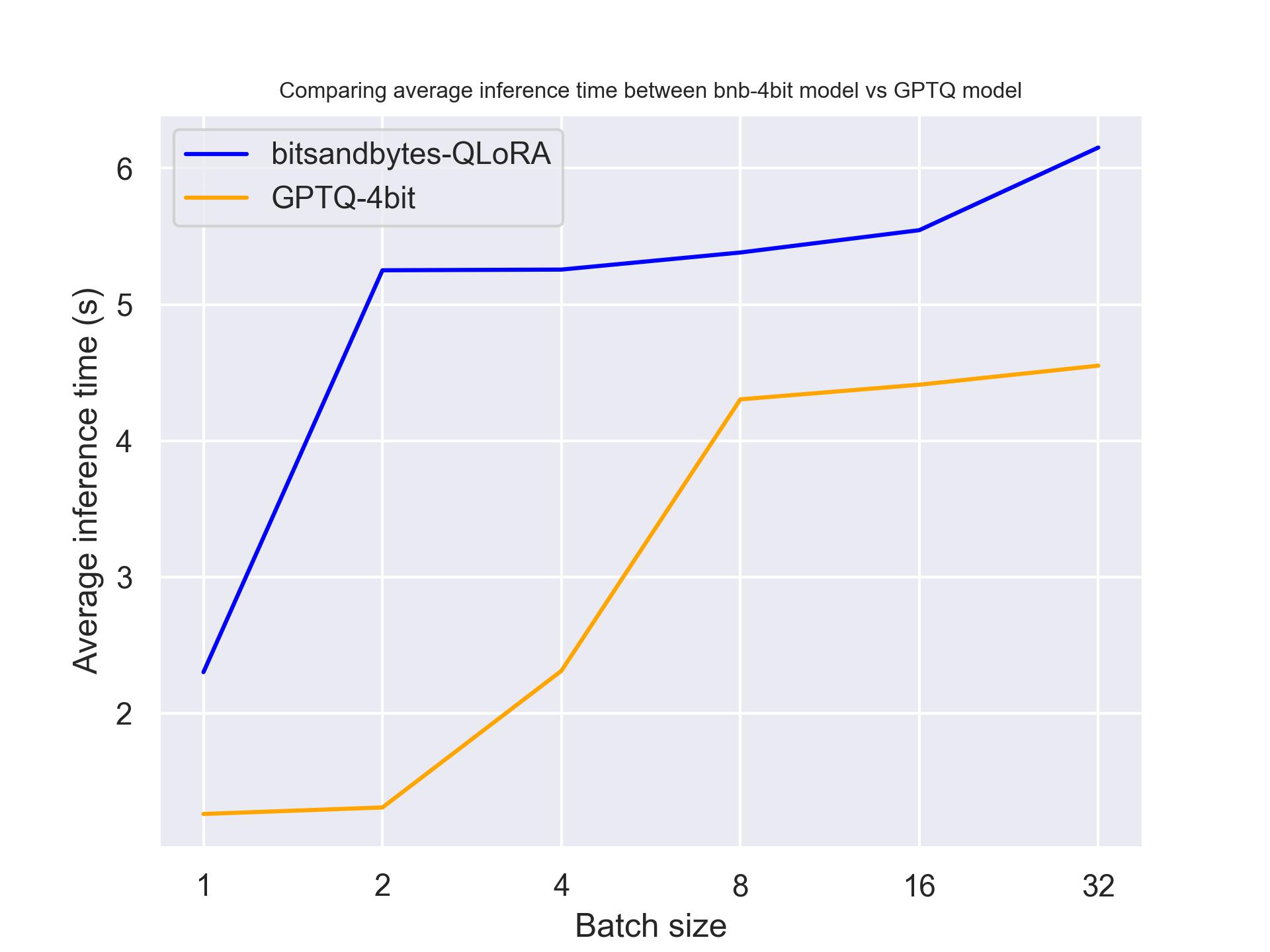
Titan RTXを使用して:
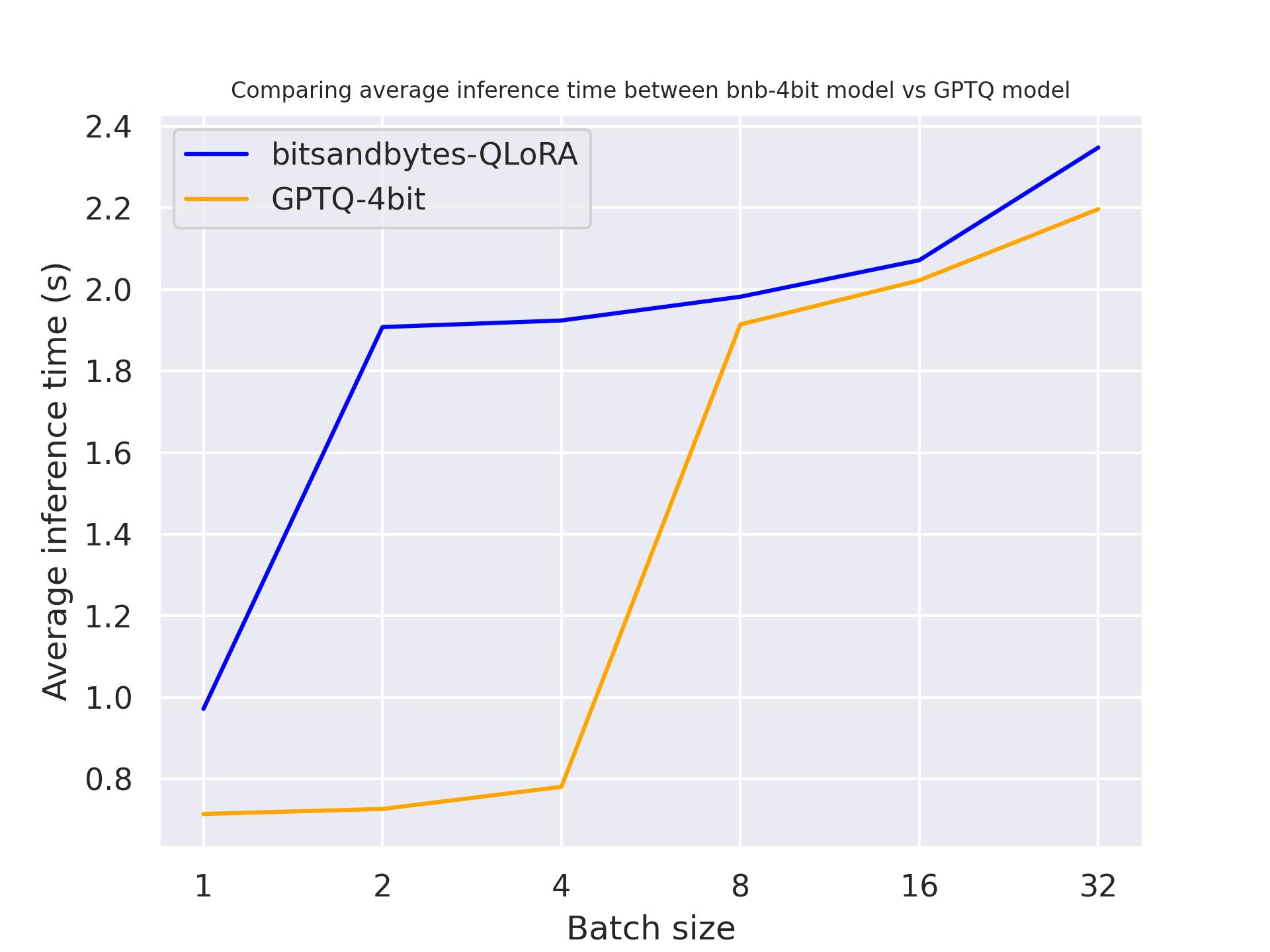
上記のベンチマークから、これらの3つのGPUではGPTQがbitsandbytesよりも速いことがわかります。
生成の長さ
次のベンチマークでは、異なる生成の長さを試して、量子化モデルへの影響を確認します。A100で実行し、プロンプトの長さは30、生成トークン数を変化させました。使用したモデルはmeta-llama/Llama-2-7b-hfです。
30トークン生成時:
512トークン生成時:
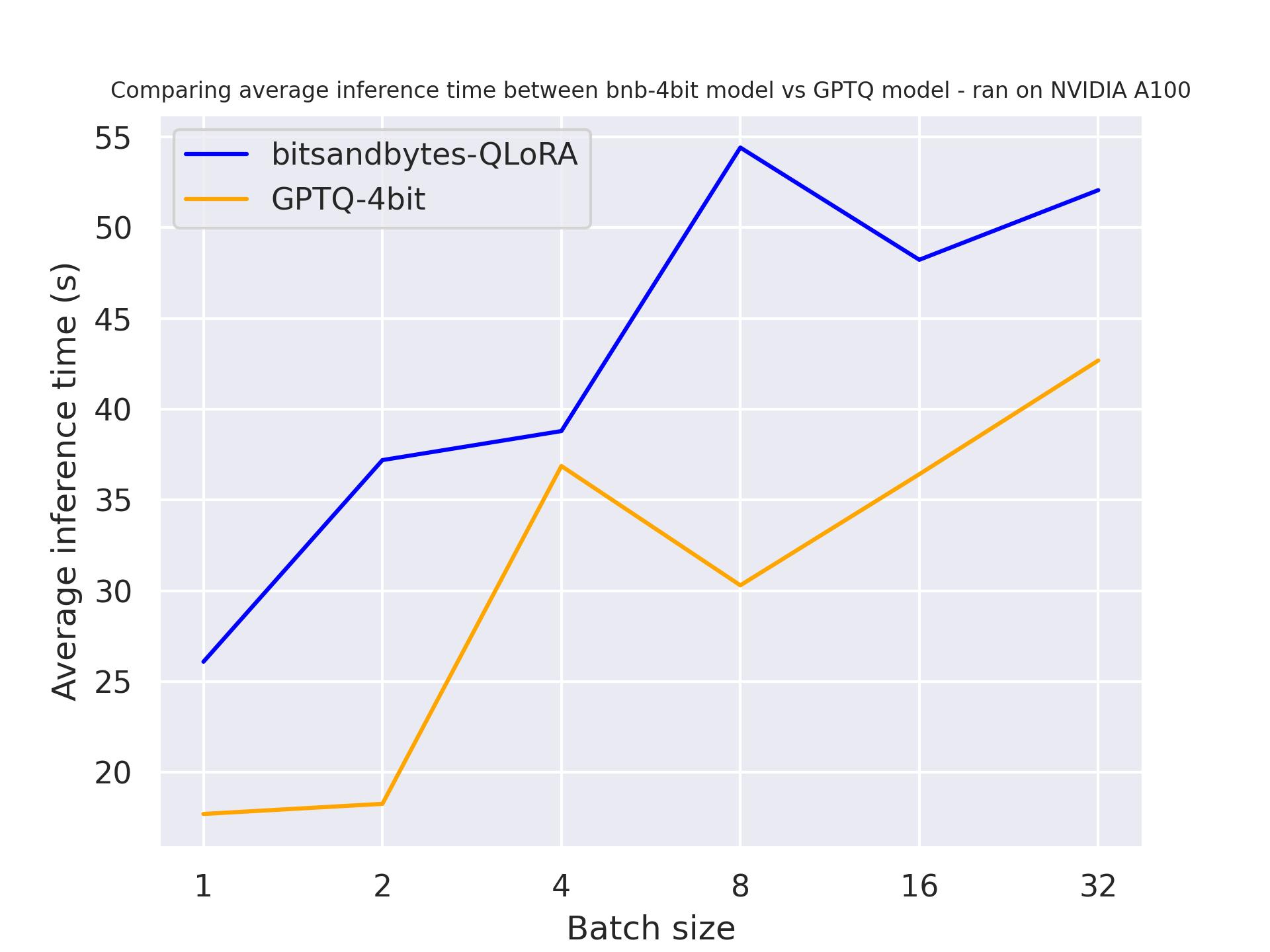
上記のベンチマークから、生成の長さに関係なく、GPTQがbitsandbytesよりも速いことがわかります。
アダプタの微調整(前進+後退)
量子化モデルでは純粋なトレーニングはできません。ただし、パラメータ効率の良いファインチューニング手法(PEFT)を活用して、これらのアダプタをトップにファインチューニングして、モデル内で適切に読み込むことで、量子化モデルを細かく調整できます。ファインチューニングの速度を比較しましょう!
ベンチマークはNVIDIA A100 GPUで実行され、Hubからmeta-llama/Llama-2-7b-hfモデルを使用しました。GPTQモデルの場合、ファインチューニングにはexllamaカーネルを無効にする必要があることに注意してください。
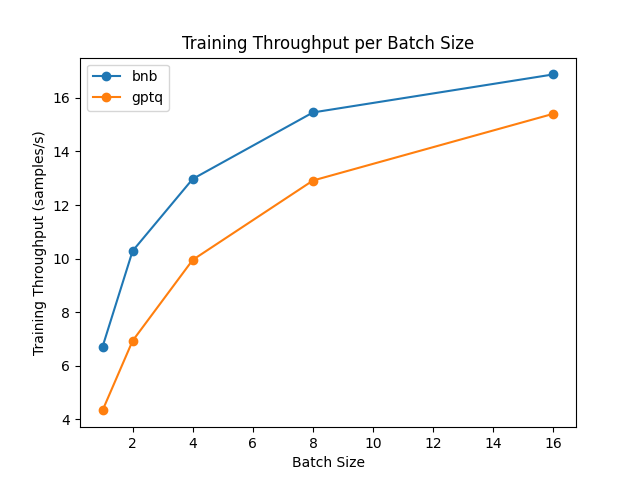
結果から、ファインチューニングではbitsandbytesがGPTQよりも速いことがわかります。
パフォーマンスの低下
量子化はメモリの消費を減らすために優れていますが、パフォーマンスの低下も伴います。Open-LLMリーダーボードを使用してパフォーマンスを比較しましょう!
7bモデルの場合:
13bモデルの場合:
上記の結果から、大きなモデルでは劣化が少ないことを結論付けます。さらに興味深いことに、その劣化は最小限です!
結論と最終的な言葉
このブログ記事では、複数のセットアップでbitsandbytesとGPTQの量子化を比較しました。bitsandbytesは微調整に適している一方、GPTQは生成に適しています。この観察から、より良い統合モデルを得る方法の一つは以下の通りです:
- (1) bitsandbytesを使用してベースモデルを量子化する(ゼロショット量子化)
- (2) アダプターを追加して微調整する
- (3) ベースモデルまたは非量子化モデルの上にトレーニングされたアダプターをマージする!
- (4) GPTQを使用してマージされたモデルを量子化し、デプロイに使用する
この概要が誰もがLLMを自分のアプリケーションやユースケースで簡単に使用できるようになり、どんなものを構築するかを楽しみにしています!
謝辞
ベンチマーキングにおけるIlyas、Clémentine、Felixの助けに感謝します。
最後に、このブログ記事の執筆におけるPedro Cuencaの助けに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





