パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
'🤗 PEFT はパラメータ効率の高いファインチューニングの手法です'
動機
トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。
しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました!
PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。
また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。
- ゼロショット画像からテキスト生成 BLIP-2
- Hugging FaceとAWSが協力し、AIをよりアクセスしやすくするためにパートナーシップを結成
- Swift 🧨ディフューザー – Mac用の高速安定拡散
つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。
本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です:
- LoRA:LORA:大規模言語モデルの低ランク適応
- Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます
- Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力
- P-Tuning:GPTも理解しています
ユースケース
ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です:
-
Google Colabで、Nvidia GeForce RTX 2080 Ti、Nvidia GeForce RTX 3080などの11GBのRAMを搭載したコンシューマーハードウェアで、
bigscience/T0_3Bモデル(30億のパラメータ)を🤗 PEFT LoRAを使用して微調整する例:peft_lora_seq2seq_accelerate_ds_zero3_offload.py -
Google Colabで、🤗 PEFT LoRAとbitsandbytesを使用して
OPT-6.7bモデル(67億のパラメータ)のINT8チューニングを有効にする例:
-
11GBのRAMを搭載したコンシューマーハードウェアで、🤗 PEFTを使用してStable Diffusion Dreamboothのトレーニングを行う例:smangrul/peft-lora-sd-dreambooth
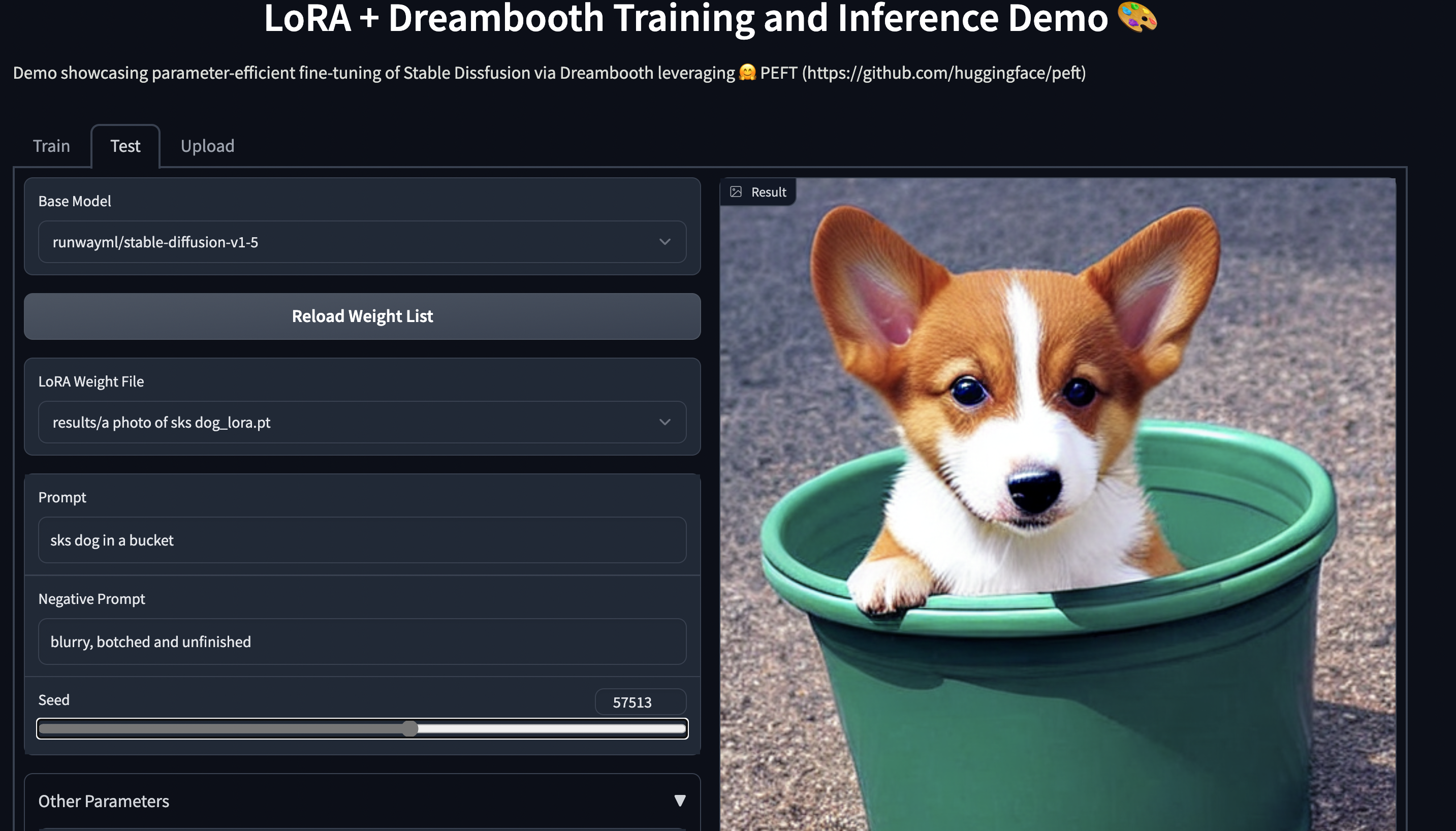 PEFT LoRA ドリームブース グラディオ スペース
PEFT LoRA ドリームブース グラディオ スペース
🤗 PEFTを使用してモデルをトレーニングする
LoRAを使用してbigscience/mt0-largeをファインチューニングする場合を考えてみましょう。
- 必要なインポートを取得しましょう
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"- PEFTメソッドに対応する設定を作成する
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)get_peft_modelを呼び出して基本の🤗 Transformersモデルをラップする
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# 出力: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282以上です!トレーニングループの残りの部分は同じままです。エンドツーエンドの例については、peft_lora_seq2seq.ipynbを参照してください。
- 推論用にモデルを保存する準備ができたら、以下のコードを実行して保存できます。
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") も可能ですこれにより、トレーニングされた増分PEFTウェイトのみが保存されます。例えば、LoRAを使用してtwitter_complaintsデータセット上でbigscience/T0_3Bを調整したモデルは、こちらで見つけることができます:smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM 。注意してください、2つのファイルしか含まれていないことに注目してください:adapter_config.jsonとadapter_model.binで、後者はわずか19MBです。
- 推論のためにモデルをロードするには、以下のスニペットに従ってください:
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'次のステップ
PEFTは、大規模なLLMをダウンストリームのタスクやドメインに効率的にチューニングする方法としてリリースされており、フルファインチューニングと比較可能なパフォーマンスを実現しながら、計算とストレージを節約することができます。今後の数ヶ月間、(IA)3やボトルネックアダプターなどのPEFTメソッドをさらに探求し、PEFTアプローチを使用してwhisper-largeモデルのINT8トレーニングやポリシーとランカーのチューニングなど、新しいユースケースに焦点を当てます。
一方で、業界の実践者がPEFTを自分のユースケースに適用する様子を見るのはとても楽しみです – 質問やフィードバックがある場合は、GitHubのリポジトリで問題を開いてください 🤗。
パラメータ効率的なファインチューニングをお楽しみください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





