🤗変換器を使用した確率的な時系列予測
'🤗確率的な時系列予測の変換器使用'
![]()
はじめに
時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。
確率予測
通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。
一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。
- Apple SiliconでのCore MLを使用した安定した拡散を利用する
- GPT2からStable Diffusionへ:Hugging FaceがElixirコミュニティに参入します
- 高速なトレーニングと推論 Habana Gaudi®2 vs Nvidia A100 80GB
つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。
確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。
時系列トランスフォーマ
時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。
このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。
まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。
第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。
トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。
Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。
🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。
環境のセットアップ
まず、必要なライブラリをインストールしましょう:🤗 Transformers、🤗 Datasets、🤗 Evaluate、🤗 Accelerate、およびGluonTS。
次に、データを変換して特徴量を作成し、適切なトレーニング、検証、およびテストバッチを作成するためにGluonTSを使用します。
!pip install -q transformers
!pip install -q datasets
!pip install -q evaluate
!pip install -q accelerate
!pip install -q gluonts ujsonデータセットの読み込み
このブログポストでは、オーストラリアの366の地域の月次観光量が含まれるtourism_monthlyデータセットを使用します。このデータセットは、様々なドメインの時系列データセットのコレクションであるMonash Time Series Forecastingリポジトリの一部です。時系列予測のGLUEベンチマークと見なすことができます。
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "tourism_monthly")データセットには、トレーニング、検証、およびテストの3つの分割が含まれていることがわかります。
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
})各例にはいくつかのキーが含まれており、そのうちのstartとtargetが最も重要です。データセットの最初の時系列を見てみましょう:
train_example = dataset['train'][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])startは単に時系列の開始を示しており、targetには時系列の実際の値が含まれています。
startは、時系列値に時間関連の特徴を追加するための追加の入力としてモデルに役立ちます(例:「年の月」)。データの頻度がmonthlyであることがわかっているため、例えば2番目の値はタイムスタンプ1979-02-01を持つことがわかります。
print(train_example['start'])
print(train_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5772.876953125]検証セットはトレーニングセットと同じデータを含んでおり、ただしprediction_lengthよりも長い期間です。これにより、モデルの予測を正解と比較することができます。
テストセットは、検証セットよりも再びprediction_lengthよりも長いデータです(または複数のローリングウィンドウでトレーニングセットと比較して複数の倍数のprediction_lengthよりも長いデータです)。
validation_example = dataset['validation'][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])最初の値は対応するトレーニング例とまったく同じです:
print(validation_example['start'])
print(validation_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5985.830078125]ただし、この例ではトレーニング例と比較して、prediction_length=24個の追加の値があります。確認しましょう。
freq = "1M"
prediction_length = 24
assert len(train_example["target"]) + prediction_length == len(
validation_example["target"]
)これを可視化しましょう:
import matplotlib.pyplot as plt
figure, axes = plt.subplots()
axes.plot(train_example["target"], color="blue")
axes.plot(validation_example["target"], color="red", alpha=0.5)
plt.show()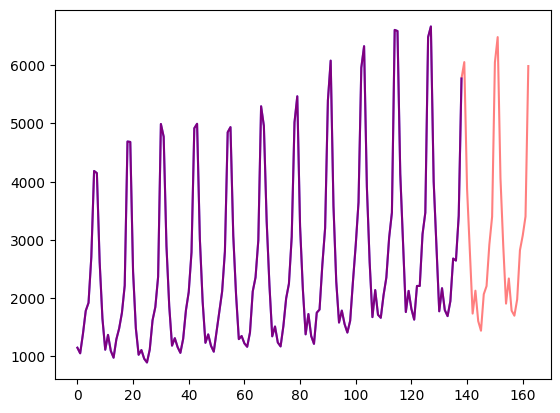
データを分割しましょう:
train_dataset = dataset["train"]
test_dataset = dataset["test"]`start`を`pd.Period`に更新する
最初に、各時系列の`start`フィーチャーをデータの`freq`を使用してpandasの`Period`インデックスに変換します:
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batchこれをインプレースでリアルタイムで行うために、`datasets`の`set_transform`機能を使用します:
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))モデルの定義
次に、モデルをインスタンス化します。モデルはゼロからトレーニングされるため、ここでは`from_pretrained`メソッドを使用せず、モデルをランダムに初期化します。
モデルにいくつかの追加パラメータを指定します:
prediction_length(この場合、24ヶ月):これはTransformerのデコーダーが予測するホライズンです;context_length:モデルは、context_length(エンコーダーの入力)をprediction_lengthと等しく設定します。ただし、context_lengthが指定されていない場合は、prediction_lengthと等しくなります;- 特定の周波数のラグ:これは「遡る」量を指定します。追加の特徴量として追加されます。たとえば、
日次の周波数では、[1, 2, 7, 30,...]のような遡る量を考慮するか、分単位のデータでは[1, 30, 60, 60*24,...]などを考慮するかなどです; - 時間特徴量の数:この場合、
2とします。つまり、MonthOfYearとAgeの特徴量を追加します; - 静的カテゴリ特徴量の数:この場合、単一の「時系列ID」特徴量を追加するため、
1とします; - 基数:各静的カテゴリ特徴量の値の数を、リストとして指定します。この場合は
[366]となります。 - 埋め込み次元:各静的カテゴリ特徴量の埋め込み次元を、リストとして指定します。たとえば
[3]は、366の時系列(地域)それぞれに対してサイズ3の埋め込みベクトルを学習することを意味します。
与えられた周波数(”monthly”)に対して、GluonTSが提供するデフォルトのラグを使用しましょう:
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 23, 24, 25, 35, 36, 37]これは、各タイムステップについて最大37ヶ月まで遡ることができることを意味します。
GluonTSが提供するデフォルトの時系列特徴量もチェックしてみましょう:
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function month_of_year at 0x7fa496d0ca70>]この場合、”month of year”という単一の特徴量があります。つまり、各タイムステップに対して、月をスカラー値として追加します(たとえば、タイムスタンプが “january” の場合は “1”、 “february” の場合は “2” など)。
モデルを定義するために必要なすべてが揃いました:
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerForPrediction
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
# コンテキスト長:
context_length=prediction_length * 2,
# 周波数に応じたラグ:
lags_sequence=lags_sequence,
# 時間特徴量に2つの特徴量("month of year"と"age")を追加します:
num_time_features=len(time_features) + 1,
# シングルの静的カテゴリカル特徴量である時系列IDがあります:
num_static_categorical_features=1,
# 366の可能な値があります:
cardinality=[len(train_dataset)],
# モデルは366の可能な値ごとにサイズ2の埋め込みを学習します:
embedding_dimension=[2],
# トランスフォーマーパラメータ:
encoder_layers=4,
decoder_layers=4,
d_model=32,
)
model = TimeSeriesTransformerForPrediction(config)重要な点として、🤗 Transformersライブラリの他のモデルと同様に、TimeSeriesTransformerModelはエンコーダーデコーダートランスフォーマーであり、上部にはヘッドがありません。また、TimeSeriesTransformerForPredictionは、TimeSeriesTransformerModelに分布ヘッドが付いたものです。デフォルトでは、モデルはStudent-t分布を使用します(が、これは設定可能です):
model.config.distribution_output
>>> student_tこれは、NLP向けのTransformersとは異なり、ヘッドが通常、nn.Linearレイヤーとして実装された固定カテゴリカル分布であることとは重要な違いです。
変換を定義する
次に、データの変換を定義します。特に、時間特徴量の作成に関する変換を行います(データセットまたはユニバーサルな特徴量に基づいて)。
ここでも、GluonTSライブラリを使用します。変換のChainを定義します(これは画像のためのtorchvision.transforms.Composeに少し似ています)。複数の変換を単一のパイプラインに組み合わせることができます。
from gluonts.time_feature import (
time_features_from_frequency_str,
TimeFeature,
get_lags_for_frequency,
)
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)以下の変換はコメントで説明されており、それぞれが何を行うかを説明しています。高レベルでは、データセットの個々の時系列を反復処理し、フィールドや特徴量を追加または削除します:
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
# torchvision.transforms.Composeのようなもの
return Chain(
# ステップ1:指定されていない場合は静的/動的フィールドを削除
[RemoveFields(field_names=remove_field_names)]
# ステップ2:データをNumPyに変換(必要な場合のみ)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# 多変量の場合は追加の次元を期待します:
expected_ndim=1 if config.input_size == 1 else 2,
),
# ステップ3:NaNを処理し、ターゲットにゼロを埋め込んでマスクを返します
# (観測値にはtrue、nanにはfalseがあります)
# デコーダーはこのマスクを使用します(未観測値に対しては損失は発生しません)
# xxxForPredictionモデル内のloss_weightsを参照してください
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# ステップ4:データセットの周波数に基づいて時間特徴量を追加します
# freq="M"の場合は月の年
# これらは位置エンコーディングとして機能します
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# ステップ5:もう1つの時間特徴量を追加します(単一の数値のみ)
# 時系列の値がモデルのライフサイクルのどこにあるかを示します
# 一種のランニングカウンターです
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# ステップ6:すべての時間特徴量を垂直にスタックし、キーFEAT_TIMEに配置します
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# ステップ7:HuggingFaceの名前に合わせてフィールド名をリネーム
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)インスタンス分割器を定義する
トレーニング/検証/テストのために、次にデータセットからウィンドウをサンプリングするために使用されるInstanceSplitterを作成します(時間とメモリの制約により、値の完全な履歴をTransformerに渡すことはできませんので、ウィンドウをサンプリングする必要があります)。
インスタンス分割器は、データからランダムにcontext_lengthの大きさのウィンドウとその後のprediction_lengthの大きさのウィンドウをサンプリングし、対応するウィンドウのために一時キーにpast_またはfuture_を追加します。これにより、valuesはpast_valuesとその後のfuture_valuesのキーに分割され、それぞれエンコーダとデコーダの入力として使用されます。同様のことがtime_series_fields引数のキーに対しても行われます:
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)データローダーを作成する
次に、データローダーを作成します。これにより、(入力、出力)のペアであるバッチ(つまり、 past_values 、 future_values )を持つことができます。
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# トレーニングインスタンスを初期化します
instance_splitter = create_instance_splitter(config, "train")
# インスタンス分割器は、ターゲットの時系列データ内からランダムに
# コンテキスト長 + ラグ + ピクチャ長(366個の変換済み時系列の中から)のウィンドウを
# サンプリングし、イテレータを返します
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(
stream, is_train=True
)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# テストインスタンス分割器を作成し、エンコーダのみでのみトレーニング中に
# 最後に見たコンテキストウィンドウをサンプリングします
instance_sampler = create_instance_splitter(config, "test")
# テストモードで変換を適用します
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=train_dataset,
batch_size=256,
num_batches_per_epoch=100,
)
test_dataloader = create_test_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)最初のバッチをチェックしましょう:
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 85, 2]) torch.FloatTensor
past_values torch.Size([256, 85]) torch.FloatTensor
past_observed_mask torch.Size([256, 85]) torch.FloatTensor
future_time_features torch.Size([256, 24, 2]) torch.FloatTensor
static_categorical_features torch.Size([256, 1]) torch.LongTensor
future_values torch.Size([256, 24]) torch.FloatTensor
future_observed_mask torch.Size([256, 24]) torch.FloatTensor上記のように、エンコーダには input_ids と attention_mask を与えません(これはNLPモデルの場合のようなものです)。代わりに、past_values と past_observed_mask 、 past_time_features 、および static_categorical_features を与えます。
デコーダの入力は、future_values 、 future_observed_mask 、および future_time_features です。 future_values は、NLPの decoder_input_ids に相当するものと考えることができます。
それぞれの詳細については、ドキュメントを参照してください。
Forward Pass
作成したバッチで単一のフォワードパスを実行しましょう:
# フォワードパスを実行
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
print("Loss:", outputs.loss.item())
>>> Loss: 9.069628715515137モデルは損失を返すことに注意してください。デコーダは、予測値とラベルとの間で損失を計算するために、future_values を右に1つシフトします。
また、デコーダは予測する必要のある値が future_values テンソルにあるため、未来を見ないようにするために因果マスクを使用します。
モデルの訓練
モデルを訓練する時間です!標準的なPyTorchの訓練ループを使用します。
ここでは、自動的にモデル、オプティマイザ、およびデータローダーを適切な device に配置するために、🤗 Accelerateライブラリを使用します。
from accelerate import Accelerator
from torch.optim import AdamW
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(40):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# 逆伝播
accelerator.backward(loss)
optimizer.step()
if idx % 100 == 0:
print(loss.item())推論
推論時には、NLPモデルと同様に、自己回帰生成のためにgenerate()メソッドを使用することが推奨されています。
予測には、テストインスタンスサンプラーからデータを取得する必要があります。これにより、データセットの各時系列から直近のcontext_lengthサイズのウィンドウの値がサンプリングされ、モデルに渡されます。なお、デコーダには事前にわかっているfuture_time_featuresも渡されます。
モデルは、予測分布から一定数の値を自己回帰的にサンプリングし、それらをデコーダに返して予測出力を返します:
model.eval()
forecasts = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts.append(outputs.sequences.cpu().numpy())モデルは、形状が( batch_size , number of samples , prediction length )のテンソルを出力します。
この場合、バッチ内の各例に対して、次の24か月について100個の可能な値が得られます(バッチのサイズは64です):
forecasts[0].shape
>>> (64, 100, 24)これらを垂直に積み重ねて、テストデータセットの全時系列の予測を取得できます:
forecasts = np.vstack(forecasts)
print(forecasts.shape)
>>> (366, 100, 24)テストセットに含まれる真のアウトオブサンプル値に対して、予測結果を評価することもできます。MASEおよびsMAPEのメトリックを使用し、データセットの各時系列に対して計算します:
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.2564196892177717
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.1609541520852549また、データセットの各時系列の個別のメトリックをプロットし、わずかな時系列が最終的なテストメトリックに大きく寄与していることを観察することもできます:
plt.scatter(mase_metrics, smape_metrics, alpha=0.3)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()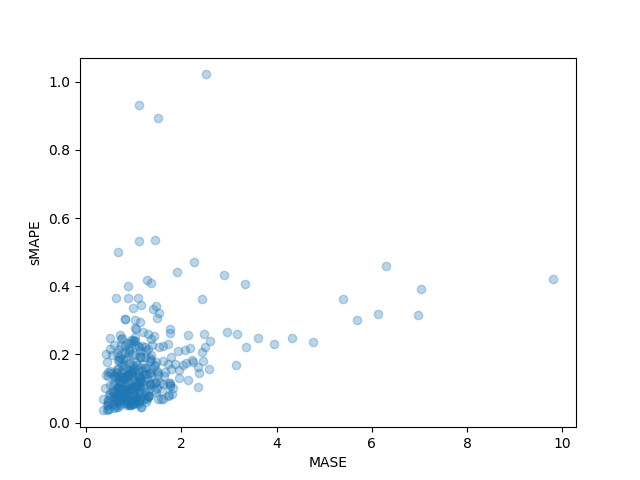
任意の時系列に対する予測を地面の真のテストデータと比較してプロットするために、次のヘルパーを定義します:
import matplotlib.dates as mdates
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_dataset[ts_index][FieldName.START],
periods=len(test_dataset[ts_index][FieldName.TARGET]),
freq=freq,
).to_timestamp()
# Major ticks every half year, minor ticks every month,
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=(1, 7)))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
ax.plot(
index[-2*prediction_length:],
test_dataset[ts_index]["target"][-2*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.fill_between(
index[-prediction_length:],
forecasts[ts_index].mean(0) - forecasts[ts_index].std(axis=0),
forecasts[ts_index].mean(0) + forecasts[ts_index].std(axis=0),
alpha=0.3,
interpolate=True,
label="+/- 1-std",
)
plt.legend()
plt.show()例えば:
plot(334)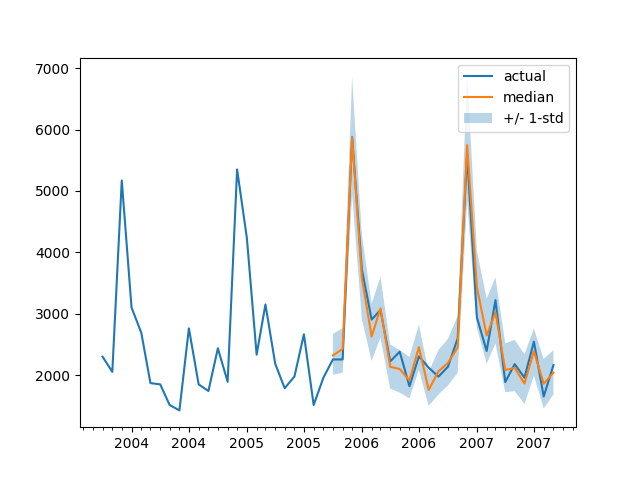
他のモデルと比較する方法は? Monash Time Series Repositoryには、テストセットのMASE指標の比較表があります。
注意点として、私たちのモデルは他のすべてのモデルを上回っています(対応する論文の表2も参照)。また、ハイパーパラメータの調整は行っていません。ただ、Transformerを40エポックでトレーニングしただけです。
もちろん、ニューラルネットワークを用いた時系列の最先端の結果を主張することには注意が必要です。 “XGBoostは通常必要なもの” のようです。ただ、私たちはニューラルネットワークがどこまで私たちを導くのか、そしてTransformerがこの領域で役立つのかを非常に興味津々です。この特定のデータセットは、それを調査する価値があることを示しています。
次のステップ
読者には、Hubから他の時系列データセットを試してみて、適切な周波数と予測長のパラメータを置き換えることをお勧めします。データセットをGluonTSで使用される規則に変換する必要がありますが、それは彼らのドキュメントで詳しく説明されています。また、データセットを🤗データセット形式に変換する方法を示したサンプルノートブックも用意しています。
時系列の研究者は知っているように、Transformerベースのモデルを時系列問題に適用することに関心が高まっています。バニラTransformerは単に注意力ベースのモデルの1つであり、ライブラリにはさらに多くのモデルが必要です。
現時点では、多変量時系列のモデリングに制限はありませんが、多変量分布ヘッドを持つモデルをインスタンス化する必要があります。現在、対角独立分布のみがサポートされており、他の多変量分布が追加される予定です。将来のブログ記事にはチュートリアルが含まれる予定です。
ロードマップ上のもう一つの項目は、時系列分類です。これには、異常検出タスクなどの分類ヘッドを持つ時系列モデルをライブラリに追加することが含まれます。
現在のモデルは、時系列値とともに日時の存在を前提としていますが、野生のすべての時系列にはそうでない場合もあります。Woodsのような神経科学のデータセットなどを参照してください。したがって、現在のモデルを一般化して、パイプライン全体で一部の入力をオプションにする必要があります。
最後に、NLP/ビジョンの領域は大規模な事前学習モデルの恩恵を受けていますが、私たちは時系列の領域ではそのようなケースがないと認識しています。Transformerベースのモデルは、この研究の方向性を追求するための明らかな選択肢のように思われ、研究者や実践者がどのような成果を出すのかを楽しみにしています!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





