iPhone、iPad、およびMacでのCore MLによる高速で安定した拡散
高速で安定した拡散は、iPhone、iPad、およびMacでのCore MLによって実現されています
先週、WWDC’23(Apple Worldwide Developers Conference)が開催されました。キーノート中のVision Proの発表に焦点が当てられましたが、それだけではありません。毎年のように、WWDC週はAppleのオペレーティングシステムとフレームワークの新機能について深く掘り下げる200以上の技術セッションが詰まっています。今年は特に、圧縮と最適化のためのCore MLの変更に興奮しています。これらの変更により、Stable Diffusionなどのモデルの実行が高速化され、メモリ使用量も少なくなります!一例として、12月にiPhone 13で実行したテストと現在の6ビットパレット化を使用した速度の比較を考えてみましょう:
 12月のiPhoneでのStable Diffusionと現在の6ビットパレット化
12月のiPhoneでのStable Diffusionと現在の6ビットパレット化
目次
- 新しいCore MLの最適化
- 量子化および最適化されたStable Diffusionモデルの使用
- カスタムモデルの変換と最適化
- 6ビット未満の使用
- 結論
新しいCore MLの最適化
Core MLは、Appleのデバイス内で効率的に機械学習モデルを実行するための成熟したフレームワークであり、CPU、GPU、およびMLタスクに特化したニューラルエンジンなど、Appleデバイスのすべてのコンピューティングハードウェアを活用します。デバイス上での実行は、Stable Diffusionや大規模な言語モデルの人気によって引き起こされた非常に興味深い時期を迎えています。多くの人々がこれらのモデルをさまざまな理由でハードウェア上で実行したいと考えており、利便性やプライバシー、APIのコスト削減などがその理由です。自然に、多くの開発者がデバイス上でこれらのモデルを効率的に実行する方法を探求し、新しいアプリやユースケースを作成しています。この目標を達成するためのCore MLの改善は、コミュニティにとって大きなニュースです!
Core MLの最適化の変更は、2つの異なる(しかし補完的な)ソフトウェアパッケージを含んでいます:
- Core MLフレームワーク自体。これは、MLモデルをAppleのハードウェア上で実行するエンジンであり、オペレーティングシステムの一部です。モデルは、フレームワークでサポートされている特別な形式でエクスポートする必要があり、この形式は「Core ML」とも呼ばれます。
coremltools変換パッケージ。これは、PyTorchやTensorflowモデルをCore ML形式に変換するためのオープンソースのPythonモジュールです。
coremltoolsには、coremltools.optimizeという新しいサブモジュールが含まれており、圧縮および最適化ツールがすべて備わっています。このパッケージの詳細については、このWWDCセッションをご覧ください。Stable Diffusionの場合、16ビット浮動小数点表現からパラメータごとにわずか6ビットの量子化を行う6ビットパレット化を使用します。この「パレット化」という名前は、コンピュータグラフィックスで使用される技術と似ています。限られた色のセットで作業するためのもので、カラーテーブル(または「パレット」)には固定数の色が含まれ、画像の色はパレットで利用可能な最も近い色のインデックスで置き換えられます。これにより、ストレージサイズが大幅に削減され、ダウンロード時間とデバイスのディスク使用量が削減されるという利点がすぐに得られます。
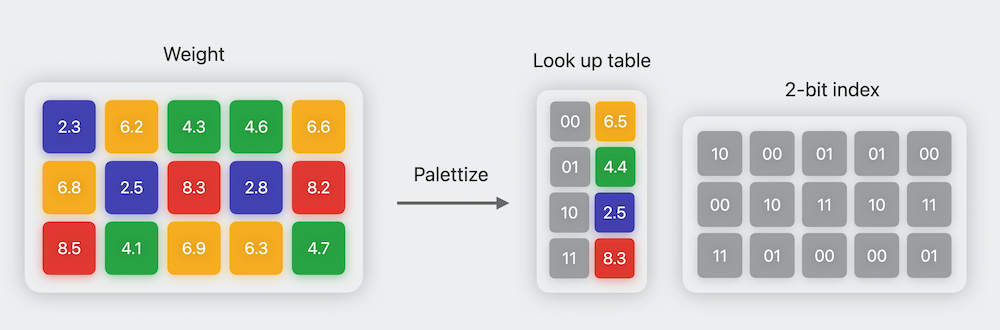 2ビットのパレット化のイラスト。画像クレジット: Apple WWDC’23 Session Use Core ML Tools for machine learning model compression .
2ビットのパレット化のイラスト。画像クレジット: Apple WWDC’23 Session Use Core ML Tools for machine learning model compression .
圧縮された6ビットの重みは計算に使用できません。なぜなら、それらは単にテーブル内のインデックスであり、元の重みの大きさを表さなくなっているからです。したがって、Core MLは使用する前にパレット化された重みを展開する必要があります。以前のCore MLのバージョンでは、モデルが最初にディスクから読み込まれるときに展開が行われたため、使用されるメモリ量は展開されたモデルのサイズと同じでした。新しい改善により、重みは6ビットのまま保持され、推論が層ごとに進行するにつれてリアルタイムに変換されます。これは遅く感じるかもしれませんが、推論ランは展開操作が多く必要ですが、通常は16ビットモードで重みを準備するよりも効率的です!その理由は、メモリ転送が実行のクリティカルパスにあるため、展開されていないデータを転送するよりもメモリを少なく転送する方が速いからです。
量子化および最適化されたStable Diffusionモデルの使用
昨年12月、Appleはml-stable-diffusionというオープンソースのリポジトリを紹介しました。これは、Stable DiffusionモデルをCore MLに簡単に変換するためのもので、利用可能なデバイスでニューラルエンジン上で推論を高速化するトランスフォーマーのアテンションレイヤーに最適化も適用します。WWDC後、ml-stable-diffusionは以下のような更新が行われました:
- 変換中に
--quantize-nbitsを使用して量子化をサポートしています。8ビット、6ビット、4ビット、または2ビットに量子化できます!最良の結果を得るためには、6ビットの量子化を使用することをおすすめします。精度の損失は小さく、高速な推論と大幅なメモリの節約が実現できます。それ以下の値を使用したい場合は、詳細なテクニックについてはこのセクションをご覧ください。 - Neural Engineでさらなるパフォーマンス向上を実現するためのアテンションレイヤーの追加の最適化!トリックは、クエリシーケンスを512のチャンクに分割して、大きな中間テンソルの作成を回避することです。このメソッドはコードでは
SPLIT_EINSUM_V2と呼ばれ、パフォーマンスを10%から30%向上させることができます。
これらの改善をすべての人が簡単に利用できるようにするために、4つの公式のStable Diffusionモデルを変換し、Hubにプッシュしました。以下がすべてのバリアントです。
各バリアントはCore ML形式とzipアーカイブでも利用できます。zipファイルは、オープンソースのデモアプリや他のサードパーティツールなどのネイティブアプリに最適です。モデルを独自のハードウェアで実行する場合は、デモアプリを使用してテストしたい量子化モデルを選択するのが最も簡単な方法です。アプリはXcodeを使用してコンパイルする必要がありますが、App Storeでのダウンロード用のアップデートが近日中に利用可能になります。詳細については、以前の投稿をご覧ください。
 デモアプリで6ビットのstable-diffusion-2-1-baseモデルを実行中
デモアプリで6ビットのstable-diffusion-2-1-baseモデルを実行中
Xcodeプロジェクトに統合するために特定のCore MLパッケージをダウンロードしたい場合は、リポジトリをクローンするか、次のようなコードを使用して興味のあるバージョンをダウンロードできます。
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-2-1-base-palettized"
variant = "original/packages"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"モデルは{model_path}にダウンロードされました")カスタムモデルの変換と最適化
パーソナライズされたStable Diffusionモデルを使用したい場合(たとえば、ファインチューニングしたり、独自のモデルをドリームブーストしたりする場合)、Appleのml-stable-diffusionリポジトリを使用して自分で変換することができます。以下はその手順の要約ですが、詳細なドキュメントをお読みいただくことをおすすめします。
- 変換したいモデルを選択します。独自のモデルをトレーニングするか、Hugging Face Diffusers Models Galleryから1つを選択できます。例えば、
prompthero/openjourney-v4を変換します。 apple/ml-stable-diffusionをインストールし、次のようにORIGINALのアテンション実装を使用して最初の変換を実行します:
python -m python_coreml_stable_diffusion.torch2coreml \
--model-version prompthero/openjourney-v4 \
--convert-unet \
--convert-text-encoder \
--convert-vae-decoder \
--convert-vae-encoder \
--convert-safety-checker \
--quantize-nbits 6 \
--attention-implementation ORIGINAL \
--compute-unit CPU_AND_GPU \
--bundle-resources-for-swift-cli \
--check-output-correctness \
-o models/original/openjourney-6-bitSPLIT_EINSUM_V2のアテンション実装に対しても変換を繰り返します:
python -m python_coreml_stable_diffusion.torch2coreml \
--model-version prompthero/openjourney-v4 \
--convert-unet \
--convert-text-encoder \
--convert-vae-decoder \
--convert-safety-checker \
--quantize-nbits 6 \
--attention-implementation SPLIT_EINSUM_V2 \
--compute-unit ALL \
--bundle-resources-for-swift-cli \
--check-output-correctness \
-o models/split_einsum_v2/openjourney-6-bit-
所望のハードウェア上で変換されたモデルをテストしてください。一般的な目安として、macOSでは通常、
ORIGINALバージョンの方が良い結果が出ますが、iOSではSPLIT_EINSUM_V2の方が通常は速いです。詳細や追加のデータポイントについては、以前のStable Diffusion for Core MLのバージョンでコミュニティから提供されたこれらのテストを参照してください。 -
希望のモデルを独自のアプリに統合するには:
- アプリ内でモデルを配布する場合は、
.mlpackageファイルを使用してください。ただし、これによりアプリのバイナリサイズが増加します。 - それ以外の場合は、アプリの起動時にダイナミックにダウンロードするためにコンパイルされた
Resourcesを使用できます。
- アプリ内でモデルを配布する場合は、
6ビット未満の使用
6ビットの量子化は、モデルの品質、モデルのサイズ、利便性の間のベストなバランスです – 事前学習済みモデルを量子化できるように変換オプションを提供するだけで済みます。これは事後トレーニング圧縮の例です。
先週リリースされたcoremltoolsのベータ版には、トレーニング時の圧縮方法も含まれています。ここでは、事前学習済みのStable Diffusionモデルを微調整し、微調整が行われている間に重みの圧縮を行うことができます。これにより、品質の低下を最小限に抑えながら4ビットまたは2ビットの圧縮を使用することができます。これが機能する理由は、重みクラスタリングが微分可能なアルゴリズムを使用して行われるため、通常のトレーニング最適化手法を適用して量子化テーブルを見つけることができるからです。
この方法の評価を近々行う予定ですが、4ビット最適化モデルがどのように機能し、どれくらい速く実行されるかを楽しみにしています。もし先に成功された場合は、ぜひご一報ください 🙂
結論
量子化手法を使用することで、Stable Diffusionモデルのサイズを削減し、デバイス上での実行を高速化し、リソースの消費を減らすことができます。Core MLとcoremltoolsの最新バージョンでは、6ビットのパレット化などのテクニックを簡単に適用でき、品質への影響を最小限に抑えることができます。Hubには6ビットのパレット化モデルも追加されており、iOSとmacOSの両方で実行するのに十分小さいです。また、自分自身で微調整したモデルを変換する方法も示しました。これらのツールとテクニックをどのように使用するかを楽しみにしています!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






