「最も適応能力の高い生存者 コンパクトな生成型AIモデルは、コスト効率の高い大規模AIの未来です」
高い生存能力を持つコンパクトなAIモデルは、大規模なAIの未来において費用効率の高い選択肢です

スケール展開される生成型AIアプリケーションのための素早く、ターゲット指向の検索ベースモデルが最適な解決策である理由
人工知能(AI)モデルの複雑さと計算の急速な成長の10年後、2023年は効率と生成型AI(GenAI)の広範な適用に焦点を当てる転換点となりました。その結果、150億パラメータ以下の、ニンブルなAIと呼ばれるモデルは、特に特定の領域にターゲットを絞った場合には、1000億パラメータ以上のChatGPTスタイルの巨大モデルとほぼ同等の機能を提供することができます。GenAIは既にさまざまな業界で幅広いビジネス用途に展開されていますが、コンパクトでありながら高度な知能を持つモデルの使用が増えています。近い将来、大型モデルは少数となり、無数の応用プログラムに組み込まれた小型でよりニンブルなAIモデルが存在すると予想されます。
大型モデルについては大きな進展がありましたが、トレーニングや環境のコストに関しては、大きいほど良いわけではありません。TrendForceによると、GPT-4のChatGPTのトレーニングだけでも1億ドル以上かかり、ニンブルモデルの事前トレーニングコストは桁違いに低い(例えば、MosaicMLのMPT-7Bの場合は約20万ドルと報告されています)。コンピューティングコストのほとんどは連続的な推論実行中に発生しますが、これは高価な計算を含む大型モデルにも同様の課題です。さらに、サードパーティの環境にホストされた巨大モデルは、セキュリティとプライバシーの問題を引き起こします。ニンブルモデルは運用コストが大幅に削減され、適応性、ハードウェアの柔軟性、大規模アプリケーション内での統合性、セキュリティとプライバシー、説明可能性など、さまざまな追加の利点を提供します(図1を参照)。また、小型モデルが大型モデルほど優れたパフォーマンスを提供しないという認識も変わってきています。小型でターゲット指向のモデルは同等または優れたビジネス、消費者、科学の領域でのパフォーマンスを提供することができ、価値を高める一方で時間とコストの投資を減らすことができます。
これらのニンブルモデルの数は、ChatGPT-3.5の巨大モデルのパフォーマンスにほぼ匹敵し、性能と範囲の向上が急速に進んでいます。そして、ニンブルモデルがクエリに基づいてキュレーションされたドメイン固有のプライベートデータとウェブコンテンツのリアルタイム検索を備えると、幅広いデータセットを記憶する巨大モデルよりも正確性とコスト効率が高くなります。

ニンブルなオープンソースのGenAIモデルが進化の速いフィールドを牽引する中で、この「iPhoneの瞬間」、つまり革新的な技術が主流になる時期に、研究者や開発者の強力なコミュニティがお互いのオープンソースの成果を基にしてますます能力の高いニンブルモデルを作り出すという「Android革命」が挑戦しています。
- 「17/7から23/7までのトップコンピュータビジョン論文」
- 「大規模言語モデルのための任意のPDFおよび画像からテキストを抽出する方法」
- LangChain 101 パート1. シンプルなQ&Aアプリの構築
考える、行動する、知る:ターゲット指向のドメインを持つニンブルモデルは巨大モデルと同等の性能を発揮できる
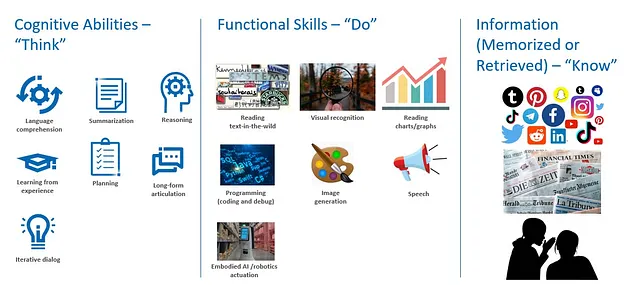
生成型AIにおいて、小型モデルがどのように競争力のある結果を提供できるかをより理解するためには、ニンブルモデルと巨大なGenAIモデルの両方が次の3つの能力クラスを必要とすることに注目することが重要です:
- 思考するための認知能力:言語理解、要約、推論、計画、経験からの学習、長文の表現、対話など。
- 実行するための機能スキル:例えば、自然言語処理、チャート/グラフの読み取り、視覚認識、プログラミング(コーディングとデバッグ)、画像生成、音声など。
- 知るための情報(記憶または検索):ソーシャルメディア、ニュース、研究などの一般的なウェブコンテンツ、および医療、金融、企業データなどの特定のドメインのカリキュレーションされたコンテンツ。
思考するための認知能力。認知能力に基づいて、モデルは「思考」し、理解し、要約し、統合し、推論し、言語やその他の象徴的な表現を作成することができます。俊敏なモデルと巨大なモデルの両方がこれらの認知的なタスクで優れたパフォーマンスを発揮することができ、これらの中核的な能力が巨大なモデルサイズを必要とするかどうかは明確ではありません。たとえば、Microsoft ResearchのOrcaのような俊敏なモデルは、複数のベンチマークでChatGPTを上回る理解力、論理力、推論力を示しています。さらに、Orcaは大きなモデルを教師として使用して推論力を抽出できることも示しています。ただし、モデルの認知能力を評価するために現在使用されているベンチマークはまだ初歩的なものです。俊敏なモデルが巨大なモデルの「思考」力と完全に一致するためには、さらなる研究とベンチマークが必要です。
実行するための機能的なスキル。一般的な焦点を持つオールインワンモデルとして、大きなモデルはおそらくより多くの機能的なスキルと情報を持っています。ただし、ほとんどのビジネス用途では、展開されるアプリケーションに必要な特定の範囲の機能的なスキルがあります。ビジネスアプリケーションで使用されるモデルは、成長と使用の変動のための柔軟性と余地を持つ必要がありますが、無制限の機能的なスキルセットはほとんど必要ありません。GPT-4は複数の言語でテキスト、コード、画像を生成できますが、数百の言語を話すことは、これらの巨大なモデルが本質的により多くの基礎となる認知能力を持っていることを意味するわけではありません。それは主にモデルに追加の機能的なスキルを与えるものです。さらに、機能的に特化したエンジンはGenAIモデルにリンクされ、その機能が必要な場合に使用されます。たとえば、数学的な「Wolfram superpowers」をChatGPTにモジュールとして追加することで、最高の機能を提供できます。例えば、GPT-4はアドオン機能に小さなモデルを使用するプラグインを展開しています。また、GPT-4モデル自体が、GPT-3.5のような一つのモノリシックな密集モデルではなく、異なるデータとタスク分布でトレーニングされた複数の巨大な(100Bパラメータ未満)「専門家の混合」モデルのコレクションであるという噂もあります。能力とモデルの効率性の最適な組み合わせを得るためには、将来のマルチファンクションモデルは、それぞれが15Bパラメータ未満のより小さな、より焦点を絞った専門家の混合モデルを採用する可能性が高いです。
知識(記憶または検索)を知るための情報。巨大なモデルは、パラメトリックメモリ内の膨大なデータを記憶することで、より多くの知識を「知って」いますが、それは必ずしも彼らをより賢くするわけではありません。彼らは単により一般的に知識が豊富です。巨大なモデルは、ターゲットを絞る必要がない場合や、Orcaのような俊敏なモデルを抽出して微調整する教師モデルとしての高い価値を持ちます。しかし、ターゲットを絞った俊敏なモデルは特定のドメインに対してトレーニングおよび/または微調整されることにより、必要な能力に対してより鋭いスキルを提供することができます。
たとえば、プログラミングを対象としたモデルは、医療AIシステムとは異なる能力の範囲に焦点を当てることができます。さらに、内部および外部のデータのキュレーションされたセットを通じて検索を使用することで、モデルの精度とタイムリネスを大幅に向上させることができます。最近の研究では、PopQAベンチマークでは、検索を使用した1.3Bパラメータ程度の小さなモデルが、175Bパラメータのモデルよりも100倍以上のサイズのモデルと同等のパフォーマンスを発揮することが示されています(図4を参照)。この意味では、ターゲットシステムの関連する知識は、オールインワンの汎用システムよりもはるかに広範である可能性があります。これは、ユースケースやアプリケーション固有のデータが必要な企業のほとんどのアプリケーションにとってより重要かもしれません。さらに、広範な一般知識ではなく、ローカルな知識が必要です。これが俊敏なモデルの価値が将来的に実現される場所です。
俊敏なモデルの爆発的な成長に寄与する3つの側面
俊敏なモデルの利点と価値を評価する際に考慮すべき3つの側面があります:
- 控えめなモデルサイズでの高効率性。
- オープンソースまたはプロプライエタリとしてのライセンス。
- 汎用または特定の目的を持つモデルの特化、リトリーバルを含む。
サイズの観点では、MetaのLLaMA-7Bおよび-13BやTechnology Innovation InstituteのFalcon 7Bのオープンソースモデル、MosaicMLのMPT-7B、Microsoft ResearchのOrca-13B、Saleforce AI ResearchのXGen-7Bなどのプロプライエタリモデルなど、俊敏な汎用モデルが急速に改善されています(図6を参照)。高性能で小型のモデルを選択できることは、運用コストやコンピューティング環境の選択に重要な影響を与えます。ChatGPTの175Bパラメーターモデルや推定1.8兆パラメーターのGPT-4は、トレーニングと微調整の作業を処理するために十分な計算能力を持つGPUなどのアクセラレータの大規模なインストールを必要とします。一方、俊敏なモデルは一般的に任意のハードウェア上で推論を実行できます。単一のソケットCPUからエントリーレベルのGPU、最大のアクセラレーションラックまで、あらゆる選択肢があります。現在、俊敏なAIの定義は、13Bパラメーター以下のモデルの優れた結果に基づいて経験的に15Bパラメーターに設定されています。全体的に、俊敏なモデルは新しいユースケースを処理するためのより費用効果の高いスケーラブルなアプローチを提供します(俊敏なモデルの利点と欠点のセクションを参照してください)。
2つ目の側面であるオープンソースライセンスにより、大学や企業はお互いのモデルを改良し合い、創造的なイノベーションのブームを生み出すことができます。オープンソースモデルによって、図5で示されているように、小さなモデルの能力が驚くほど進歩しています。
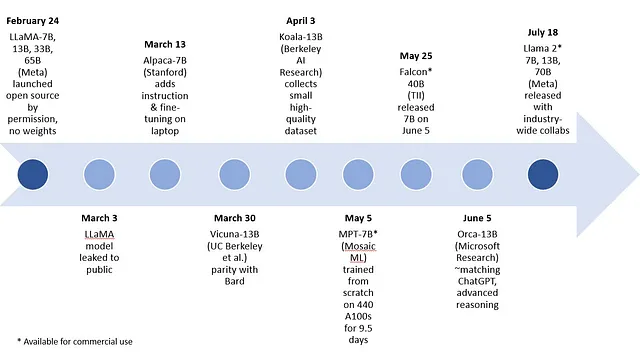
2023年初頭の一般的な俊敏な生成AIモデルの複数の例があります。MetaのLLaMAをベースモデルとして、7B、13B、33B、65Bパラメーターを持つモデルが存在します。次のモデルは、LLaMAのファインチューニングによって作成された7Bパラメーターと13Bパラメーターの範囲に含まれます:スタンフォード大学のAlpaca、バークレイAI研究のKoala、UCバークレー、カーネギーメロン大学、スタンフォード大学、UCサンディエゴ、MBZUAIの研究者によって作成されたVicuna。最近、Microsoft Researchは、特定のドメインへのターゲティングやファインチューニングなしで、巨大モデルの推論プロセスを模倣する13BパラメーターのLLaMAベースモデルであるOrcaについての論文を発表しました。
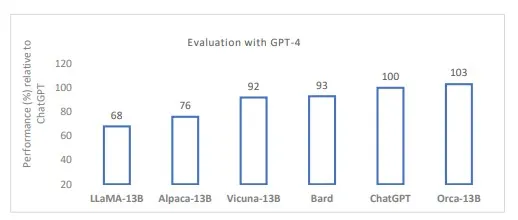
Vicunaは、ChatGPTなどの既存のモデルのトレーニングとアーキテクチャの詳細の不足に対処するために開発された、ベースモデルであるLLaMAから派生した最近のオープンソースの俊敏なモデルの良い代理となるかもしれません。Vicuna-13Bは、ShareGPTからのユーザー共有の会話をファインチューニングした後、GPT-4を判断基準として使用した場合、ChatGPTやGoogle Bardと比べて応答品質が90%以上です。ただし、これらの初期のオープンソースモデルは商業利用できません。MosaicMLのMPT-7BおよびTechnology Innovation InstituteのFalcon 7Bは商業利用可能なオープンソースモデルであり、LLaMA-7Bと同等の品質を備えていると報告されています。
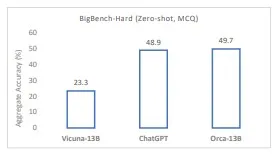
オルカ「ビクーニャ-13Bなどの従来の教示調整モデルを超え、Big-Bench Hard(BBH)などの複雑なゼロショット推論ベンチマークで100%以上の性能を発揮します。BBHベンチマークではChatGPT-3.5と同等のパフォーマンスを達成します」と、研究者は述べています。オルカ-13Bは他の一般的なモデルに比べて優れたパフォーマンスを発揮し、巨大モデルの大きさは単なる力任せの初期モデルから生じる可能性があるという概念を強化しています。巨大な基礎モデルのスケールは、オルカ-13Bのような小さなモデルが知識と手法を抽出するために重要な役割を果たすことができますが、推論にはサイズが必ずしも必要ではありません – 一般的な場合でもそうです。注意が必要な点は、モデルの認知能力、機能的スキル、および知識の記憶の完全な評価は、広く展開され、実行されるときにのみ可能になるということです。
このブログの執筆時点では、Metaは7B、13B、70Bのパラメータを持つLlama 2モデルをリリースしました。第一世代からわずか4か月後に登場し、モデルは意味のある改善を提供します。比較チャートでは、素早いLlama 2 13Bは、前のLLaMA世代のより大きなモデルとMPT-30B、Falcon 40Bと同様の結果を達成します。Llama 2はオープンソースであり、研究および商業利用に無料です。それはMicrosoftとの緊密なパートナーシップを通じて紹介されました。また、Intelを含む他のいくつかのパートナーとも協力しています。Metaのオープンソースモデルへの取り組みと幅広い協力は、このようなモデルの急速な業界/学術改善サイクルにさらなる推進力を与えることでしょう。
素早いモデルの3番目の側面は、特殊化に関するものです。新たに導入された多くの素早いモデルは、LLaMA、ビクーニャ、オルカなどの一般的な目的のモデルです。一般的な素早いモデルは、パラメトリックメモリだけを頼りにし、推論時間中にキュレーションされたコーパスから関連する知識をオンザフライで引っ張ってきて低コストのアップデートを行います。リトリーバルオーグメントソリューションは、LangChainやHaystackなどのGenAIフレームワークを使用して確立され、継続的に向上されています。これらのフレームワークは、インデックスの容易な柔軟な統合と、意味ベースのリトリーバルのための大規模なコーパスへの効果的なアクセスを可能にします。
多くのビジネスユーザーは、特定の関心領域に調整されたターゲットモデルを好みます。これらのターゲットモデルは、通常、すべての重要な情報資産を活用するためにリトリーバルベースであります。例えば、医療ユーザーは患者とのコミュニケーションを自動化したいと考えるかもしれません。
ターゲットモデルは2つの方法を使用します:
- タスクとターゲットの使用例に必要なデータのモデル自体への特殊化。これは、特定のドメインの知識を事前にトレーニングすること(例えば、phi-1がウェブからのテキストブック品質のデータで事前トレーニングする方法)、同じサイズの一般的なベースモデルを微調整すること(例えば、Clinical CamelがLLaMA-13Bを微調整する方法)、または巨大モデルから学び、学生の素早いモデルに知識や方法を抽出すること(例えば、OrcaがGPT-4の推論プロセス、説明トレース、ステップバイステップの思考プロセス、その他の複雑な指示を模倣する方法)が含まれます。
- オンザフライのリトリーバルのための関連データのキュレーションとインデックス付け。これは大量のデータである場合もありますが、ターゲットの使用例の範囲/スペース内に収まります。モデルは、公共のウェブや消費者または企業のプライベートコンテンツをリトリーブできます。これらのソースのインデックスを決定するのはユーザーであり、ウェブからの高品質なリソースや個人のプライベートデータや企業のエンタープライズデータなど、より完全なリソースを選ぶことができます。リトリーバルは、巨大なモデルと素早いシステムの両方に統合されているため、モデルのパフォーマンスに必要なすべての情報を提供する上で重要な役割を果たします。また、ビジネスが自社のコンピュート環境内で実行される素早いモデルにすべてのプライベートおよびローカル情報を利用できるようにします。
素早い生成型AIモデルの利点と欠点
将来、コンパクトなモデルのサイズは20Bまたは25Bのパラメータに上昇するかもしれませんが、依然として100Bのパラメータの範囲を大幅に下回るでしょう。また、MPT-30B、Falcon 40B、およびLlama 2 70Bなどの中間サイズのモデルのバラエティも存在します。これらのモデルは、ゼロショットではより小さなモデルよりも優れたパフォーマンスを発揮することが予想されますが、特定の機能セットに対して素早い、ターゲット型、リトリーバルベースのモデルよりも実質的に優れたパフォーマンスを発揮することは期待できません。
巨大モデルと比較して、素早いモデルには多くの利点があり、モデルがターゲット化されてリトリーバルベースになるとさらに強化されます。これらの利点には、次のようなものがあります:
- 持続可能で低コストなモデル: トレーニングおよび推論の計算コストが格段に低いモデル。推論の実行時の計算コストは、
いくつかの敏捷なモデルの課題はまだ言及する価値があります:
- タスクの範囲の縮小: 汎用の巨大なモデルは優れた汎用性を持ち、特に考慮されていなかったゼロショットの新しい用途で優れたパフォーマンスを発揮します。敏捷なシステムで達成できる幅と範囲はまだ評価中ですが、最近のモデルの改善が見られます。ターゲットモデルは、タスクの範囲が事前トレーニングおよび/またはファインチューニングの間に既知で定義されていると仮定していますので、範囲の縮小は関連する機能に影響を与えるべきではありません。ターゲットモデルは単一のタスクではなく、関連する機能のファミリーです。これにより、タスクまたはビジネス固有の敏捷なモデルによる断片化が引き起こされる可能性があります。
- フューショットのファインチューニングにより改善される場合があります: ターゲット空間に適したモデルは、常にファインチューニングが必要ではありませんが、アプリケーションに必要なタスクと情報にモデルを調整することで、AIの効果を高めることができます。近代的な技術は、少数の例と深いデータサイエンスの専門知識なしでこのプロセスを実行することを可能にします。
- リトリーバルモデルはすべてのソースデータのインデックス作成が必要です: モデルは、推論中に必要な情報をインデックスマッピングを介して取得しますが、情報ソースを見落とすリスクがあり、モデルでは利用できなくなる可能性があります。起源、説明可能性、およびその他の特性を確保するために、ターゲットのリトリーバルベースモデルは、パラメトリックメモリに格納された詳細情報に頼らず、必要な時に抽出できるインデックス情報に主に頼るべきです。
サマリー
生成AIの主要な進歩は、AIエージェントが自然言語で会話し、魅力的なテキストの要約と生成、画像の作成、前のイテレーションの文脈の利用など、新しい能力を実現しています。このブログでは、「敏捷AI」という用語を紹介し、なぜそれがGenAIの大規模展開において主要な手法になるのかを説明しています。単純に言えば、敏捷AIモデルは実行速度が速く、継続的なファインチューニングによるリフレッシュが迅速であり、オープンソースコミュニティの集合的なイノベーションによる急速な技術改善サイクルにも対応できます。
複数の例を通じて示されたように、最大のモデルの進化によって生まれた卓越したパフォーマンスは、敏捷なモデルには巨大なモデルと同じような大きな重みが必要ではないことを示して
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






