LangChainとLLMsのための非同期処理
非同期処理のためのLangChainとLLMs
LangChainチェーンを非同期呼び出しでLLMに対応させ、連続的な長いチェーンの実行時間を高速化する方法

この記事では、LangChainを使用してLLMの長いワークフローに非同期呼び出しを使用する方法について説明します。完全なコードの例とシーケンシャルな実行と非同期呼び出しの比較も行います。
以下はコンテンツの概要です。興味のあるセクションにジャンプすることもできます。
- 基本: LangChainとは何か
- LangChainを使用して同期的なチェーンを実行する方法
- LangChainを使用して単一の非同期チェーンを実行する方法
- 非同期チェーンでの長いワークフローのための実践的なヒント
さあ、始めましょう!
基本: LangChainとは何か
LangChainは、言語モデルを活用したアプリケーションの開発フレームワークです。それがLangChainの公式定義です。このフレームワークは最近作成され、既にLLMを活用したツールの業界標準として使用されています。
- Sklearnの交差検証の可視化:K-Fold、シャッフル&スプリット、および時系列スプリット
- 「PolarsによるEDA:集計と分析関数のステップバイステップガイド(パート2)」
- 「顔認識システムにおけるバイアスの解消 新しいアプローチ」
LangChainはオープンソースでメンテナンスが良く、非常に迅速なリリースで新機能が提供されています。
公式のドキュメンテーションはこちら、GitHubのリポジトリはこちらです。
このライブラリの欠点の一つは、機能が新しいためChat GPTを効果的に使用して新しいコードを構築できないことです。つまり、ドキュメンテーション、フォーラム、チュートリアルを読んで学習する「古代」の方法で作業する必要があるということです。
LangChainの公式ドキュメンテーションは非常に良いですが、特定の事例の具体的な例があまりありません。
私は長いチェーンの非同期処理についてこの問題に直面しました。
このフレームワークについてもっと学ぶために使用した主なリソースは次のとおりです。
- Deep Learning AIコース: LangChainデータとのチャット
- 公式ドキュメンテーション
- YouTubeチャンネル
(注: すべて無料です)
LangChainを使用して同期的なチェーンを実行する方法
まず、私が抱えた問題を設定しましょう: 多数の行を持つデータフレームがあり、それぞれの行に対して複数のプロンプト(チェーン)をLLMに実行し、その結果をデータフレームに返す必要があります。
たとえば、10,000行がある場合、それぞれの行に3つのプロンプトを実行し、それぞれの応答には(サーバーが過負荷でなければ)約3〜5秒かかると、ワークフローの完了まで数日待たなければなりません。
以下に、同期的なチェーンを構築して時間を計測するための主な手順とコードを示します。
この例では、データセット「Wine Reviews」のライセンスを使用します。ここでは、書かれたレビューからいくつかの情報を抽出することを目標とします。
レビューの要約、主な感情、および各ワインのトップ5の特徴を抽出したいと思います。
そのために、要約と感情のための1つのチェーンと、要約を入力として特徴を抽出するための別のチェーンを作成しました。
実行するコードはこちらです:
実行時間(10の例):
要約チェーン(シーケンシャル)の実行時間は22.59秒です。特徴チェーン(シーケンシャル)の実行時間は22.85秒です。
使用しているコンポーネントについて詳しく理解したい場合は、Deep Learning AIコースを強くお勧めします。
このコードの主なポイントは、チェーンの構築要素、シーケンシャルな方法での実行方法、およびループの終了にかかった時間です。10の例については約45秒かかりましたが、完全なデータセットには130,000行が含まれています。したがって、非同期実装は合理的な時間でこれを実行するための新たな希望です。
問題設定とベースラインの確立が完了したので、このコードをより高速化する方法を見ていきましょう。
LangChainを使用して単一の非同期チェーンを実行する方法
このために、非同期呼び出しと呼ばれるリソースを使用します。これを説明するために、まずコードが何をしていて、どこで時間がかかりすぎているかを簡単に説明します。
私たちの例では、データフレームの各行を処理し、行から情報を抽出し、それらをプロンプトに追加し、GPT APIを呼び出して応答を取得します。応答後、それを解析し、データフレームに追加します。

ここでの主なボトルネックは、GPT APIを呼び出すときです。なぜなら、私たちのコンピュータはそのAPIからの応答を待つ必要があるからです(約3秒)。他のステップは高速であり、最適化することもできますが、これはこの記事の焦点ではありません。
応答を待つ代わりに、すべての呼び出しを同時にAPIに送信したらどうでしょうか?このように、単一の応答を待つだけで、それからそれらを処理する必要があります。これはAPIへの非同期呼び出しと呼ばれます。
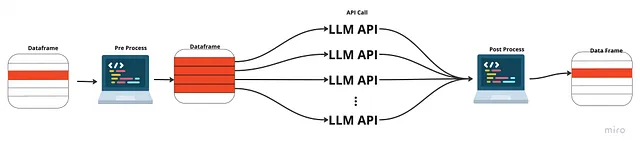
この方法では、前処理と後処理を順次実行しますが、APIへの呼び出しは前の応答が戻ってくるのを待つ必要はありません。
以下は非同期チェーンのコードです:
このコードでは、Pythonのasyncとawaitの構文を使用しています。LangChainはまた、チェーンを非同期で実行するためのarun()関数のコードを提供しています。したがって、最初に各行を順次処理し(最適化できます)、APIからの応答を並列で待機する複数の「タスク」を作成し、応答を最終的な目的の形式に順次処理します(これも最適化できます)。
実行時間(10の例):
非同期のサマリーチェーンは3.35秒で実行されました。非同期の特徴チェーンは2.49秒で実行されました。
順次実行と比較すると:
順次のサマリーチェーンは22.59秒で実行されました。順次の特徴チェーンは22.85秒で実行されました。
実行時間が約10倍改善されていることがわかります。したがって、大きなワークロードの場合は、この方法を強くお勧めします。また、パフォーマンスを向上させるためにさらに最適化できるforループのコードがたくさんあります。
このチュートリアルの完全なコードは、このGithubリポジトリで見つけることができます。
非同期チェーンを使用した長いワークフローのための実用的なヒント。
これを実行する際に、いくつかの制限と障害に遭遇しましたので、それを共有したいと思います。
ノートブックは非同期に対応していません
Jupyter Notebooksで非同期呼び出しを実行すると、いくつかの問題が発生する場合があります。ただし、Chat GPTに質問すれば、おそらくそれに対処するのに役立つでしょう。私が作成したコードは、大きなワークロードを.pyファイルで実行するためのものなので、ノートブックで実行するためにはいくつかの変更が必要かもしれません。
出力キーが多すぎる
最初の問題は、私のチェーンに複数のキーがあり、当時のarun()は出力として1つのキーしか受け付けなかったことです。したがって、私はチェーンを2つに分割する必要がありました。
すべてのチェーンを非同期にすることはできません
プロンプトでの例と比較のために、ベクトルデータベースを使用するロジックがあり、これにより例が順次比較され、データベースに追加される必要がありました。このため、このリンクのフルチェーンでは非同期の使用は不可能でした。
コンテンツの不足
この特定の問題に関しては、私が見つけた最良の情報は、非同期の公式ドキュメントであり、そこから自分のユースケースに合わせて構築しました。ですので、実行して新しいことを発見した場合は、世界と共有してください!
結論
LangChainは、LLMベースのアプリケーションを作成するための非常に強力なツールです。このフレームワークを学び、上記のコースを受講することを強くおすすめします。
チェーンの実行という具体的なトピックに関して、高いワークロードの場合、非同期呼び出しによる潜在的な改善を確認しました。そのため、コードの動作を理解し、ボイラープレートクラス(私のコードで提供されているものなど)を持っており、非同期で実行することをおすすめします!
小規模なワークロードやAPIへの単一の呼び出しが必要なアプリケーションの場合、非同期で行う必要はありませんが、ボイラープレートクラスがある場合は、同期関数を追加して、簡単にどちらかを使用できるようにしてください。
お読みいただきありがとうございます。
完全なコードはこちらで入手できます。
コンテンツが気に入った場合、サポートしていただける場合は、コーヒーを買っていただけると嬉しいです:
ガブリエルカシミロは、コミュニティに無料のコンテンツを提供しているデータサイエンティストです
こんにちは👋こちらでページを作成しました。今からコーヒーを買っていただけます!
www.buymeacoffee.com
以下は、興味があるかもしれない他の記事です:
Deep Reinforcement Learningを使用したUnity環境の解決
Deep Reinforcement Learning AgentのPyTorch実装のエンドツーエンドプロジェクトとコード
towardsdatascience.com
TensorflowモデルとOpenCVによるオブジェクト検出
トレーニング済みモデルを使用して、静止画像とライブビデオ上のオブジェクトを識別する方法
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






