適切なバランスを取る:機械学習モデルにおける過学習と過小適合の理解
適切なバランス:機械学習モデルの過学習と過小適合の理解
この記事では、機械学習とディープラーニングの観点から、オーバーフィッティングとアンダーフィッティングの基本的な概念を説明します。
アンダーフィッティングとオーバーフィッティングを問題として見る
機械学習の問題に取り組むすべての人は、自分のモデルが可能な限り最適に動作することを望んでいます。しかし、モデルが望むように最適に動作しない場合もあります。理想的な精度よりも悪い精度や優れた精度を持つ場合があります。機械学習では、これらのいずれも問題とされます。
いくつかの人々は、理想的な精度よりも低い精度を持つことが問題とされるのは分かるかもしれませんが、なぜ上記の理想的な精度も問題として考えているのでしょうか?
時には、モデルが無意味なもの、つまり不要な特徴量やデータのノイズの関係を見つけようとすることがあります。このような余分な精度は、モデルに追加されます。以下の例でこれを理解しましょう。
例えば、人の給与を予測するモデルを訓練しているとします。この問題に対して、私たちのデータには以下の4つの特徴量があります。それは、人の名前、教育、経験、スキルセットです。私たちの常識に基づいて、人の名前は給与に影響を与える要因ではないことを知っています。しかし、この事実にもかかわらず、人の名前をデータの特徴量の1つとして使用すると、モデルは名前と給与の関係を見つけようとするかもしれません。そして、このような関係がモデルに余分な精度を加える可能性があります。これにより、理想的な精度よりも高い精度が生じ、このような場合、モデルは誤って訓練されます。
基本的な用語
話を進める前に、アンダーフィッティングとオーバーフィッティングを理解するために必要な2つの異なる種類のエラーを理解しましょう。
- バイアスエラー:バイアスエラーは、訓練データと訓練されたモデルを使用して見つけるエラーです。つまり、ここでは、モデルの訓練に使用される同じデータを使用してエラーを見つけています。エラーは平均二乗誤差、平均絶対誤差など、任意の種類のエラーである可能性があります。
- 分散エラー:分散エラーは、テストデータと訓練されたモデルを使用して見つけるエラーです。ここでも、エラーは任意の種類のエラーである可能性があります。分散を見つけるために任意の種類のエラーを使用できるにも関わらず、バイアスと分散の値を比較するためにバイアスの見つけ方と同じエラーを使用します。
訓練されたモデルの理想的な状態は、低いバイアスと低い分散を持つことです。
一般生活におけるオーバーフィッティングとアンダーフィッティングとは何か?
例えば、外国を訪れてタクシー運転手に騙されたとします。その国のすべてのタクシー運転手が欲張りだと言いたくなるかもしれません。これを過度一般化と言います。
訓練された機械学習とディープラーニングモデルでも、過度一般化が起こることがあります。機械学習とディープラーニングの場合、過度一般化はモデルのオーバーフィッティングとして知られています。
同様に、過度に一般化されないことをアンダーゼネラリゼーションとして、モデルのアンダーフィッティングと呼びます。
機械学習の観点からオーバーフィッティングとは何ですか?
モデルが低いバイアスと高い分散を持つ場合、モデルはオーバーフィッティングに苦しんでいると言います。
オーバーフィッティングは、モデルが訓練データの量とノイズの多さに対して複雑すぎる場合に起こります。
オーバーフィッティングの問題への解決策
- 次のいずれかの方法でモデルを単純化する:
パラメータの少ない機械学習モデルを選択する
機械学習モデルの訓練に使用される特徴量または列を減らす
モデルを制約する(正則化手法の使用)
2. より多くの訓練データを収集する。
3. データのノイズを減らす。ノイズはデータのエラーや外れ値の存在などです。
4. アーリーストッピングを使用する
アンダーフィッティングとは何ですか?
アンダーフィッティングは、機械学習モデルが独立変数と従属変数の関係を捉えることができない状態です。つまり、アンダーフィッティングの場合、モデルは高いバイアスと高い分散を示します。これにはいくつかの理由が考えられます。
アンダーフィッティングの問題に対する可能な解決策
- 独立変数と従属変数の関係を捉えることができる複雑なモデルを使用します。
- モデルの制約を緩和します。つまり、正則化を減らします。
- より多くのトレーニングデータを取得しようとします。
- モデルのトレーニングの期間を延長しようとします。これは、モデルをより多くのエポックでトレーニングすることによって行うことができます。
- ノイズを減らすためにデータをクリーニングしようとします。
いくつかのプロットを使用してオーバーフィッティングとアンダーフィッティングの外観を見てみましょう
赤ワインの品質データセットを使用して、アンダーフィッティングとオーバーフィッティングの概念を理解しましょう。
アンダーフィッティング:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snssns.set_style('darkgrid')from sklearn.model_selection import train_test_splitimport tensorflow.keras.layers as tflfrom tensorflow.keras.models import Model## データの読み込みwine = pd.read_csv('wine.csv')## 独立変数と従属変数にデータを分割X = wine.drop('quality',axis=1)y = wine['quality']## データをトレーニングセットとテストセットに分割X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)## モデルの作成input = tfl.Input(shape=X.shape[1:])hidden1 = tfl.Dense(6,activation='relu')(input)output = tfl.Dense(10, activation='softmax')(hidden1)model = Model(inputs=[input], outputs=[output])## モデルのコンパイルmodel.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics=['accuracy'])## トレーニングセットとテストセットを使用してモデルをトレーニングhistory = model.fit(X_train, y_train, epochs=150, validation_data=(X_test, y_test))## トレーニングセットとテストセットの正答率を可視化plt.plot(history.history['accuracy'],color='red',label='トレーニングセットの正答率')plt.plot(history.history['val_accuracy'],color='blue',label='テストセットの正答率')plt.legend()plt.show()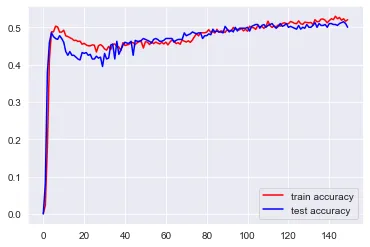
上記のプロットを観察してください。トレーニングデータとテストデータの正答率が55%未満であることがわかります。つまり、この場合、モデルはアンダーフィッティングの問題に苦しんでいます。これはモデルの単純さによるものです。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snssns.set_style('darkgrid')from sklearn.model_selection import train_test_splitimport tensorflow.keras.layers as tflfrom tensorflow.keras.models import Model## データの読み込みwine = pd.read_csv('wine.csv')## 独立変数と従属変数にデータを分割X = wine.drop('quality',axis=1)y = wine['quality']## データをトレーニングセットとテストセットに分割X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)## モデルの作成input = tfl.Input(shape=X.shape[1:])hidden1 = tfl.Dense(100,activation='relu')(input)hidden2 = tfl.Dense(100, activation='relu')(hidden1)hidden3 = tfl.Dense(100, activation='relu')(hidden2)hidden4 = tfl.Dense(100, activation='relu')(hidden3)output = tfl.Dense(10, activation='softmax')(hidden4)model = Model(inputs=[input], outputs=[output])## モデルのコンパイルmodel.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics=['accuracy'])## トレーニングセットとテストセットを使用してモデルをトレーニングhistory = model.fit(X_train, y_train, epochs=150, validation_data=(X_test, y_test))## トレーニングセットとテストセットの正答率を可視化plt.plot(history.history['accuracy'],color='red',label='トレーニングセットの正答率')plt.plot(history.history['val_accuracy'],color='blue',label='テストセットの正答率')plt.legend()plt.show()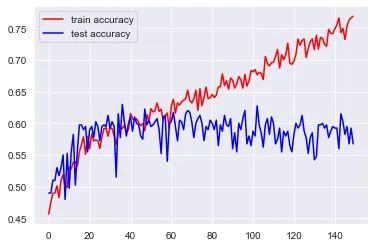
上記のプロットを観察すると、左側に向かうにつれて(つまり、エポックが増加するにつれて)、2つのグラフ間の間隔が増加していることが分かります。つまり、トレーニングが実行されるエポックを増やすと、トレーニング精度は増加し、テスト精度は増加しません。このような状況はオーバーフィッティングと考えられます。このようなモデルは、テストデータや新しいデータにおいてもうまく一般化できません。
モデルをトレーニングする際には、トレーニングデータとテストデータの両方で十分な精度を提供するようにする必要があります。このモデルはアンダーフィッティングとオーバーフィッティングの中間に位置するものとなります。
この記事がお気に召しましたら、ご意見をお聞かせください。建設的なフィードバックは大変ありがたいです。
LinkedInで私とつながってください。
メールは[email protected]までお願いします。
素晴らしい一日をお過ごしください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「2023年の最高のAI文法チェッカーツール」
- 高リスクの女性における前がん変化の予測 マンモグラフィに基づくディープラーニング手法の突破
- 光ベースのコンピューティング革命:強化された光ニューラルネットワークでChatGPTタイプの機械学習プログラムを動かす
- 「Advanced Reasoning Benchmark(ARB)に会いましょう:大規模な言語モデルを評価するための新しいベンチマーク」
- 「FACTOOLにご紹介いたします:大規模言語モデル(例:ChatGPT)によって生成されたテキストの事実エラーを検出するためのタスクとドメインに依存しないフレームワーク」
- LGBMClassifier 入門ガイド
- 「MLOpsの全機械学習ライフサイクルをカバーする:論文要約」




