農業におけるビジョン・トランスフォーマー | 革新的な収穫
農業のビジョン・トランスフォーマー | 革新的な収穫
はじめに
農業は常に人類文明の基盤であり、数十億人に生計と食料を提供してきました。技術の進歩により、農業の実践を向上させるための新たで革新的な方法が見つかっています。そのような進歩の一つが、Vision Transformers(ViTs)を使用して作物の葉の病気を分類することです。このブログでは、農業におけるビジョン・トランスフォーマーが、作物の病気の特定と軽減のための効率的かつ正確な解決策を提供することで、革命を起こしていることを探求します。
キャッサバ、またはマニオクまたはユカは、食事の主食から産業用途までさまざまな用途がある多目的な作物です。その耐久性と強靭さは、栽培条件の厳しい地域で不可欠な作物です。しかし、キャッサバの植物はさまざまな病気に対して脆弱であり、CMDとCBSDが最も破壊的なものの一部です。
CMDは、ホワイトフライによって伝播される複数のウイルスによって引き起こされ、キャッサバの葉に重度のモザイク症状を引き起こします。一方、CBSDは、2つの関連するウイルスによって引き起こされ、主に貯蔵根に影響を与え、食用に適さなくします。これらの病気を早期に特定することは、広範な作物被害を防ぐために重要であり、食料の安全保障を確保するために不可欠です。Vision Transformersは、自然言語処理(NLP)のために最初に設計されたトランスフォーマー・アーキテクチャの進化形であり、視覚データの処理に非常に効果的であることが証明されています。これらのモデルは、パッチのシーケンスとして画像を処理し、データ内の複雑なパターンと関係を捉えるために自己注意機構を使用します。キャッサバの葉の病気分類の文脈では、ViTsは感染したキャッサバの葉の画像を分析してCMDとCBSDを特定するために訓練されます。
学習成果
- ビジョン・トランスフォーマーとそれらが農業にどのように適用され、特に葉の病気の分類においてどのように使用されるかを理解する。
- トランスフォーマー・アーキテクチャの基本的な概念、自己注意機構などの理解し、これらが視覚データの処理にどのように適応されるかを学ぶ。
- キャッサバの葉の病気の早期検出のために農業におけるビジョン・トランスフォーマー(ViTs)の革新的な利用方法を理解する。
- スケーラビリティやグローバルなコンテキストなどのビジョン・トランスフォーマーの利点、および計算要件やデータ効率などの課題についての洞察を得る。
この記事は、Data Science Blogathonの一環として公開されました。
- 大規模言語モデル(LLM)の調査
- 「OpenAI、DALL·E 3を発表:テキストから画像生成における革命的な進展」
- 報告書:OpenAIがGPT-VisionというマルチモーダルLLMをリリースするための取り組みを加速中
ビジョン・トランスフォーマーの台頭
コンピュータビジョンは、畳み込みニューラルネットワーク(CNN)の開発により、近年大きな進歩を遂げています。CNNは、画像分類から物体検出まで、さまざまな画像関連のタスクのための定番アーキテクチャとなっています。しかし、ビジョン・トランスフォーマーは、視覚情報の処理に新しい手法を提供する強力な代替手段として台頭しています。Google Researchの研究者たちは、2020年に「画像は16×16の単語に値する:スケールでの画像認識のためのトランスフォーマー」という画期的な論文でビジョン・トランスフォーマーを紹介しました。彼らは、もともと自然言語処理(NLP)のために設計されたトランスフォーマー・アーキテクチャをコンピュータビジョンの領域に適応させました。この適応により、新たな可能性と課題が生まれました。
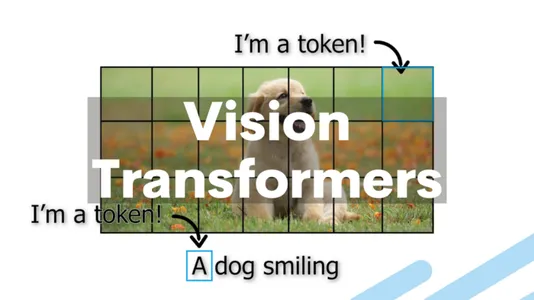
ViTsの使用は、従来の方法に比べていくつかの利点を提供しています。それには以下のものがあります:
- 高い精度:ViTsは高い精度であり、葉の病気の信頼性のある検出と区別が可能です。
- 効率性:訓練された後、ViTsは画像を素早く処理できるため、現場でのリアルタイム病気検出に適しています。
- スケーラビリティ:ViTsはさまざまなサイズのデータセットを処理できるため、さまざまな農業環境に適応できます。
- 汎化性:ViTsはさまざまなキャッサバの品種や病気のタイプに汎化することができ、各シナリオごとに特定のモデルが必要な必要性を減らします。
トランスフォーマー・アーキテクチャの概要
ビジョン・トランスフォーマーに入る前に、トランスフォーマー・アーキテクチャの核心的な概念を理解することが重要です。トランスフォーマーは、もともとNLPのために設計され、言語処理のタスクを革新しました。トランスフォーマーの主な特徴は、自己注意機構と並列化であり、より包括的な文脈理解とより高速なトレーニングを可能にします。
トランスフォーマーの中心にあるのは、自己注意機構です。この機構により、モデルは予測を行う際に異なる入力要素の重要性を評価することができます。この機構は、マルチヘッドの注意層と組み合わさることで、データ内の複雑な関係を捉えます。
では、ビジョン・トランスフォーマーは、コンピュータビジョンの領域においてこのトランスフォーマー・アーキテクチャをどのように適用しているのでしょうか?ビジョン・トランスフォーマーの基本的なアイデアは、画像をテキストのようなパッチのシーケンスとして扱うことです。その後、トランスフォーマー層は、画像内の各パッチをベクトルに埋め込むことで処理します。
ビジョン・トランスフォーマの主要な構成要素
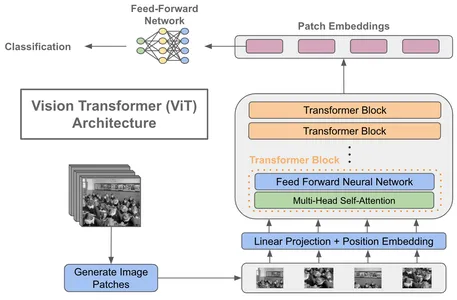
- パッチ埋め込み:画像を固定サイズの重ならないパッチに分割します。通常は16×16ピクセルです。各パッチは、低次元ベクトルに線形埋め込みされます。
- 位置符号化:パッチ埋め込みに位置符号化を追加して、パッチの空間的な配置を考慮します。これにより、モデルは画像内のパッチの相対的な位置を学習することができます。
- トランスフォーマエンコーダ:ビジョン・トランスフォーマは、NLPトランスフォーマのように、複数のトランスフォーマエンコーダ層で構成されています。各層は、パッチ埋め込みに対してセルフアテンションとフィードフォワード操作を行います。
- 分類ヘッド:トランスフォーマ層の最後に、画像分類などのタスクのための分類ヘッドが追加されます。出力埋め込みを受け取り、クラスの確率を生成します。
ビジョン・トランスフォーマの導入は、特徴抽出のために畳み込み層に依存するCNNとは大きく異なります。ビジョン・トランスフォーマは、画像をパッチのシーケンスとして扱うことで、画像分類、物体検出、さらにはビデオ解析など、さまざまなコンピュータビジョンのタスクで最先端の結果を達成しています。
実装
データセット
キャッサバの葉病データセットは、さまざまな段階と程度の病症を示すキャッサバの葉の高解像度画像約15,000枚から成ります。各画像は病気の存在を示すように細かくラベル付けされており、教師あり機械学習と画像分類のタスクに利用することができます。キャッサバの病気は独特の特徴を示しており、いくつかのカテゴリに分類されています。これらのカテゴリにはキャッサバ細菌性枯れ病(CBB)、キャッサバ茶色葉斑病(CBSD)、キャッサバ緑斑病(CGM)、キャッサバモザイク病(CMD)が含まれます。研究者やデータサイエンティストは、このデータセットを使用して、ビジョン・トランスフォーマ(ViT)などの深層ニューラルネットワークを含む機械学習モデルをトレーニングおよび評価します。
必要なライブラリのインポート
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow.keras.layers as L
import tensorflow_addons as tfa
import glob, random, os, warnings
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns csvデータセットの読み込み
image_size = 224
batch_size = 16
n_classes = 5
train_path = '/kaggle/input/cassava-leaf-disease-classification/train_images'
test_path = '/kaggle/input/cassava-leaf-disease-classification/test_images'
df_train = pd.read_csv('/kaggle/input/cassava-leaf-disease-classification/train.csv', dtype = 'str')
test_images = glob.glob(test_path + '/*.jpg')
df_test = pd.DataFrame(test_images, columns = ['image_path'])
classes = {0 : "キャッサバ細菌性枯れ病(CBB)",
1 : "キャッサバ茶色葉斑病(CBSD)",
2 : "キャッサバ緑斑病(CGM)",
3 : "キャッサバモザイク病(CMD)",
4 : "健康"}#import csvデータ拡張
def data_augment(image):
p_spatial = tf.random.uniform([], 0, 1.0, dtype = tf.float32)
p_rotate = tf.random.uniform([], 0, 1.0, dtype = tf.float32)
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
if p_spatial > .75:
image = tf.image.transpose(image)
# Rotates
if p_rotate > .75:
image = tf.image.rot90(image, k = 3) # rotate 270º
elif p_rotate > .5:
image = tf.image.rot90(image, k = 2) # rotate 180º
elif p_rotate > .25:
image = tf.image.rot90(image, k = 1) # rotate 90º
return image#import csvデータジェネレータ
datagen = tf.keras.preprocessing.image.ImageDataGenerator(samplewise_center = True,
samplewise_std_normalization = True,
validation_split = 0.2,
preprocessing_function = data_augment)
train_gen = datagen.flow_from_dataframe(dataframe = df_train,
directory = train_path,
x_col = 'image_id',
y_col = 'label',
subset = 'training',
batch_size = batch_size,
seed = 1,
color_mode = 'rgb',
shuffle = True,
class_mode = 'categorical',
target_size = (image_size, image_size))
valid_gen = datagen.flow_from_dataframe(dataframe = df_train,
directory = train_path,
x_col = 'image_id',
y_col = 'label',
subset = 'validation',
batch_size = batch_size,
seed = 1,
color_mode = 'rgb',
shuffle = False,
class_mode = 'categorical',
target_size = (image_size, image_size))
test_gen = datagen.flow_from_dataframe(dataframe = df_test,
x_col = 'image_path',
y_col = None,
batch_size = batch_size,
seed = 1,
color_mode = 'rgb',
shuffle = False,
class_mode = None,
target_size = (image_size, image_size))#import csv
images = [train_gen[0][0][i] for i in range(16)]
fig, axes = plt.subplots(3, 5, figsize = (10, 10))
axes = axes.flatten()
for img, ax in zip(images, axes):
ax.imshow(img.reshape(image_size, image_size, 3))
ax.axis('off')
plt.tight_layout()
plt.show()#import csv
モデルの構築
learning_rate = 0.001
weight_decay = 0.0001
num_epochs = 1
patch_size = 7 # 入力画像から抽出するパッチのサイズ
num_patches = (image_size // patch_size) ** 2
projection_dim = 64
num_heads = 4
transformer_units = [
projection_dim * 2,
projection_dim,
] # Transformer層のサイズ
transformer_layers = 8
mlp_head_units = [56, 28] # 最終分類器のDense層のサイズ
def mlp(x, hidden_units, dropout_rate):
for units in hidden_units:
x = L.Dense(units, activation = tf.nn.gelu)(x)
x = L.Dropout(dropout_rate)(x)
return xパッチの作成
キャッサバの葉病分類プロジェクトでは、画像パッチの抽出とエンコードを容易にするためにカスタムレイヤーを使用しています。これらの特殊なレイヤーは、Vision Transformerモデルでのデータの処理の準備に不可欠です。
class Patches(L.Layer):
def __init__(self, patch_size):
super(Patches, self).__init__()
self.patch_size = patch_size
def call(self, images):
batch_size = tf.shape(images)[0]
patches = tf.image.extract_patches(
images = images,
sizes = [1, self.patch_size, self.patch_size, 1],
strides = [1, self.patch_size, self.patch_size, 1],
rates = [1, 1, 1, 1],
padding = 'VALID',
)
patch_dims = patches.shape[-1]
patches = tf.reshape(patches, [batch_size, -1, patch_dims])
return patches
plt.figure(figsize=(4, 4))
x = train_gen.next()
image = x[0][0]
plt.imshow(image.astype('uint8'))
plt.axis('off')
resized_image = tf.image.resize(
tf.convert_to_tensor([image]), size = (image_size, image_size)
)
patches = Patches(patch_size)(resized_image)
print(f'画像サイズ: {image_size} X {image_size}')
print(f'パッチサイズ: {patch_size} X {patch_size}')
print(f'1枚の画像あたりのパッチ数: {patches.shape[1]}')
print(f'1つのパッチあたりの要素数: {patches.shape[-1]}')
n = int(np.sqrt(patches.shape[1]))
plt.figure(figsize=(4, 4))
for i, patch in enumerate(patches[0]):
ax = plt.subplot(n, n, i + 1)
patch_img = tf.reshape(patch, (patch_size, patch_size, 3))
plt.imshow(patch_img.numpy().astype('uint8'))
plt.axis('off')
class PatchEncoder(L.Layer):
def __init__(self, num_patches, projection_dim):
super(PatchEncoder, self).__init__()
self.num_patches = num_patches
self.projection = L.Dense(units = projection_dim)
self.position_embedding = L.Embedding(
input_dim = num_patches, output_dim = projection_dim
)
def call(self, patch):
positions = tf.range(start = 0, limit = self.num_patches, delta = 1)
encoded = self.projection(patch) + self.position_embedding(positions)
return encoded#import csvパッチレイヤー(クラス Patches(L.Layer)
Patchesレイヤーは、生の入力画像からパッチを抽出することでデータの前処理パイプラインを開始します。これらのパッチは、元の画像の小さな、重複しない領域を表します。このレイヤーは、画像のバッチに対して操作を行い、特定のサイズのパッチを抽出し、さらなる処理のために形状を変更します。このステップは、モデルが画像内の細かい詳細に焦点を当てることを可能にし、複雑なパターンを捉える能力に貢献します。
画像パッチの可視化
パッチの抽出後、抽出したパッチの影響を画像上に表示することで、その効果を視覚化します。これにより、画像がどのようにこれらのパッチに分割され、各画像から抽出されるパッチの数がハイライトされます。これにより、前処理の段階を理解し、後続の分析に向けた準備が整います。
パッチエンコーディングレイヤー(クラス PatchEncoder(L.Layer)
パッチが抽出されると、PatchEncoderレイヤーを通じてさらなる処理が行われます。このレイヤーは、各パッチに含まれる情報をエンコードするために重要な役割を果たしています。それは、パッチの特徴を強化する線形射影と、空間的なコンテキストを追加する位置埋め込みの2つの主要なコンポーネントで構成されています。結果として得られる豊かなパッチ表現は、Vision Transformerの分析と学習において重要であり、正確な病気の分類に寄与します。
カスタムレイヤーであるPatchesとPatchEncoderは、キャッサバの葉病分類のためのデータ前処理パイプラインにおいて重要な役割を果たしています。これらは、モデルが画像パッチに焦点を当て、正確な病気の分類に必要な重要なパターンと特徴を識別する能力を高めることができます。このプロセスにより、Vision Transformerモデルの全体的な性能が大幅に向上します。
def vision_transformer():
inputs = L.Input(shape = (image_size, image_size, 3))
# Create patches.
patches = Patches(patch_size)(inputs)
# Encode patches.
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization 1.
x1 = L.LayerNormalization(epsilon = 1e-6)(encoded_patches)
# Create a multi-head attention layer.
attention_output = L.MultiHeadAttention(
num_heads = num_heads, key_dim = projection_dim, dropout = 0.1
)(x1, x1)
# Skip connection 1.
x2 = L.Add()([attention_output, encoded_patches])
# Layer normalization 2.
x3 = L.LayerNormalization(epsilon = 1e-6)(x2)
# MLP.
x3 = mlp(x3, hidden_units = transformer_units, dropout_rate = 0.1)
# Skip connection 2.
encoded_patches = L.Add()([x3, x2])
# Create a [batch_size, projection_dim] tensor.
representation = L.LayerNormalization(epsilon = 1e-6)(encoded_patches)
representation = L.Flatten()(representation)
representation = L.Dropout(0.5)(representation)
# Add MLP.
features = mlp(representation, hidden_units = mlp_head_units, dropout_rate = 0.5)
# Classify outputs.
logits = L.Dense(n_classes)(features)
# Create the model.
model = tf.keras.Model(inputs = inputs, outputs = logits)
return model
decay_steps = train_gen.n // train_gen.batch_size
initial_learning_rate = learning_rate
lr_decayed_fn = tf.keras.experimental.CosineDecay(initial_learning_rate, decay_steps)
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lr_decayed_fn)
optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate)
model = vision_transformer()
model.compile(optimizer = optimizer,
loss = tf.keras.losses.CategoricalCrossentropy(label_smoothing = 0.1),
metrics = ['accuracy'])
STEP_SIZE_TRAIN = train_gen.n // train_gen.batch_size
STEP_SIZE_VALID = valid_gen.n // valid_gen.batch_size
earlystopping = tf.keras.callbacks.EarlyStopping(monitor = 'val_accuracy',
min_delta = 1e-4,
patience = 5,
mode = 'max',
restore_best_weights = True,
verbose = 1)
checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath = './model.hdf5',
monitor = 'val_accuracy',
verbose = 1,
save_best_only = True,
save_weights_only = True,
mode = 'max')
callbacks = [earlystopping, lr_scheduler, checkpointer]
model.fit(x = train_gen,
steps_per_epoch = STEP_SIZE_TRAIN,
validation_data = valid_gen,
validation_steps = STEP_SIZE_VALID,
epochs = num_epochs,
callbacks = callbacks)
#import csvコードの説明
このコードは、キャッサバの病気分類タスクに合わせたカスタムのVision Transformerモデルを定義しています。これには、マルチヘッドアテンションレイヤーやスキップ接続、多層パーセプトロン(MLP)を含む複数のトランスフォーマーブロックが組み込まれています。その結果、キャッサバの葉の画像の複雑なパターンを捉えることができる堅牢なモデルが生成されます。
まず、vision_transformer()関数が主要な役割を果たします。この関数は、Vision Transformerのアーキテクチャの設計図を定義します。この関数では、モデルがキャッサバの葉の画像をどのように処理し、学習するかが明確になり、病気を正確に分類することができます。
さらに、トレーニングプロセスを最適化するために、学習率スケジューラを実装しています。このスケジューラは、コサイン減衰戦略を採用しており、モデルが学習するにつれて学習率を動的に調整します。この動的な適応により、モデルの収束性が向上し、効率的に最高のパフォーマンスに達することができます。
モデルのアーキテクチャとトレーニング戦略が設定されたら、モデルのコンパイルを進めます。このフェーズでは、損失関数、オプティマイザ、評価メトリクスなどの重要なコンポーネントを指定します。これらの要素は慎重に選ばれ、モデルが学習プロセスを最適化し、正確な予測を行うことを保証します。
最後に、モデルのトレーニングの効果を確保するためにトレーニングコールバックを適用します。二つの重要なコールバックが活用されます:早期停止とモデルのチェックポイント。早期停止は検証データ上でモデルのパフォーマンスを監視し、改善が停滞した場合に介入し、過学習を防ぎます。同時に、モデルのチェックポイントは最も良いパフォーマンスを示したバージョンのモデルを記録し、将来の利用のためにその最適な状態を保持することができます。
これらの要素が組み合わさり、ビジョン・トランスフォーマー・モデルの開発、トレーニング、最適化のための総合的なフレームワークが作成されます。これは正確なキャッサバの葉病分類に向けた旅の重要なステップです。
農業におけるビジョン・トランスフォーマーの応用
キャッサバ栽培におけるビジョン・トランスフォーマーの応用は、単なる研究や新奇さを超えて、現実的な課題に対する実用的な解決策を提供します:
- 早期病気の検出:ビジョン・トランスフォーマーはCMDとCBSDの早期検出を可能にし、農家が病気の拡散を防ぎ、作物の損失を最小限に抑えるための迅速な対策を取ることができます。
- リソースの効率化:ビジョン・トランスフォーマーによる自動化された病気の検出により、時間や労力などのリソースの効率的な利用が可能となり、キャッサバの全ての植物の手動での検査の必要性が減少します。
- 精密農業:ビジョン・トランスフォーマーをドローンやIoTデバイスなどの他の技術と統合して、病気のホットスポットを正確に特定し治療する精密農業が実現できます。
- 食料安全保障の向上:ビジョン・トランスフォーマーによってキャッサバの収量への病気の影響を軽減することで、キャッサバが食事の中心となっている地域で食料安全保障が向上します。
ビジョン・トランスフォーマーの利点
ビジョン・トランスフォーマーは従来のCNNベースのアプローチに比べていくつかの利点を提供します:
- スケーラビリティ:ビジョン・トランスフォーマーは、モデルのアーキテクチャを変更することなく、異なる解像度の画像を処理することができます。これは、実世界のアプリケーションで画像のサイズが異なる場合に特に有用です。
- グローバルコンテキスト:ビジョン・トランスフォーマーの自己注意メカニズムにより、グローバルコンテキストを効果的に捉えることができます。これは、混雑したシーンでのオブジェクトの認識などのタスクにおいて重要です。
- 複雑なアーキテクチャ要素の削減:CNNとは異なり、ビジョン・トランスフォーマーはプーリング層や畳み込みフィルタなどの複雑なアーキテクチャ要素を必要としません。これにより、モデルの設計とメンテナンスが簡素化されます。
- 転移学習:ビジョン・トランスフォーマーは大規模なデータセットで事前訓練することができ、転移学習の優れた候補となります。事前訓練されたモデルは、比較的少量のタスク固有のデータで特定のタスクに適応させることができます。
課題と将来の方向性
ビジョン・トランスフォーマーは驚異的な進歩を遂げていますが、いくつかの課題に直面しています:
- 計算リソース:大規模なビジョン・トランスフォーマー・モデルのトレーニングには相当な計算リソースが必要であり、小規模な研究チームや組織にとっては障壁となる場合があります。
- データ効率:ビジョン・トランスフォーマーはデータに飢えており、限られたデータで堅牢なパフォーマンスを達成することは難しいです。よりデータ効率の良いトレーニング技術の開発は、喫緊の課題です。
- 解釈可能性:トランスフォーマーはそのブラックボックス性がしばしば批判されます。特に安全性の重要なアプリケーションにおいて、ビジョン・トランスフォーマーの解釈可能性を向上させる方法について研究が進められています。
- リアルタイム推論:大規模なビジョン・トランスフォーマー・モデルでリアルタイムの推論を実現することは、計算上の負荷が大きいです。より高速な推論のための最適化は、活発な研究領域です。
結論
ビジョン・トランスフォーマーは、キャッサバ栽培において葉病の分類に対して正確で効率的な解決策を提供することで、キャッサバ栽培を変革します。ビジュアルデータの処理能力とデータ収集およびモデルトレーニングの進歩により、キャッサバの作物を保護し、食料安全保障を確保するための非常に大きな潜在能力があります。課題は残っていますが、継続的な研究と実用的な応用によって、ビジョン・トランスフォーマーのキャッサバ栽培への採用が進んでいます。持続可能な農業慣行を推進し、破壊的な葉病による作物の損失を減らすため、ビジョン・トランスフォーマーは世界中のキャッサバ農家にとって貴重なツールに変革されるでしょう。
要点
- ビジョン・トランスフォーマー(ViTs)は、トランスフォーマーのアーキテクチャをコンピュータビジョンに適用し、画像をパッチのシーケンスとして処理します。
- ビジョン・トランスフォーマーは元々コンピュータビジョンのために設計されましたが、早期葉病の検出などの課題に対応するために農業にも応用されています。
- 計算リソースやデータ効率などの課題に取り組むことで、ビジョン・トランスフォーマーはコンピュータビジョンの未来において有望な技術となります。
よくある質問
この記事に表示されるメディアはAnalytics Vidhyaの所有物ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「画像の補完の進展:この新しいAI補完による2Dと3Dの操作のギャップを埋めるニューラル放射場」
- 「PyTorchモデルのパフォーマンス分析と最適化—パート6」
- 機械学習の革新により、コンピュータの電力使用量が削減されています
- StableSRをご紹介します:事前トレーニング済み拡散モデルの力を活用した新たなAIスーパーレゾリューション手法
- 「11/9から17/9までの週のトップ重要なコンピュータビジョンの論文」
- 無料でGoogle Colab上でQLoraを使用してLLAMAv2を微調整する
- 「ビデオセグメンテーションはよりコスト効果的になることができるのか?アノテーションを節約し、タスク間で一般化するための分離型ビデオセグメンテーションアプローチDEVAに会いましょう」






