軌跡予測のためのマップマッチング
軌跡予測のマップマッチング
どこに行くつもりですか?その方向で行くべきですか?
この記事では、ノイズのあるGPSセンサーからサンプリングされた過去のトリップデータベースを使用して、デジタル道路ネットワーク上での車両の軌跡を予測する方法を紹介します。将来の方向を予測するだけでなく、この方法は任意の位置の連続したシーケンスに確率を割り当てることもできます。
このアイデアの中心は、サンプリングされた位置情報を集約して個別の軌跡にマッチングし、デジタルマップに投影することです。このマッチングプロセスにより、連続したGPS空間が予め決められた位置とシーケンスに離散化されます。これらの位置を固有の地理空間トークンにエンコードした後、シーケンスをより簡単に予測し、現在の観測の確率を評価し、将来の方向を推定することができます。これがこの記事の要点です。
問題
ここで解決しようとしている問題は何ですか?車両の経路データを分析する必要がある場合、記事のサブタイトルにあるような質問に答える必要があるかもしれません。
どこに行くつもりですか?その方向で行くべきですか?
観察中の経路が頻繁に通行される方向に従っている確率をどのように評価しますか?これは重要な質問です。この質問に答えることで、観測された頻度に基づいてトリップを分類する自動システムをプログラムすることができます。スコアが低い新しい軌跡は懸念を引き起こし、すぐにフラグを立てることになるでしょう。
次に、車両が次にどのような操作を行うかを予測する方法はありますか?まっすぐ進むのか、次の交差点で右に曲がるのか、次の10分または10マイルの間にどこで車両を見ることを予想していますか?これらの質問に素早く答えることで、オンラインの追跡ソフトウェアソリューションはデリバリープランナーやオンラインルート最適化システム、さらには機会充電システムに回答と洞察を提供することができます。
解決策
ここで紹介する解決策では、個々の車両の動きによって生成される位置情報のタイムスタンプ付きの連続的なシーケンスである歴史的な軌跡のデータベースを使用します。各位置レコードには、時刻、位置情報、車両識別子への参照、および軌跡識別子が含まれている必要があります。車両には多くの軌跡があり、各軌跡には多くの位置レコードがあります。以下の図1は、入力データの一部のサンプルを示しています。
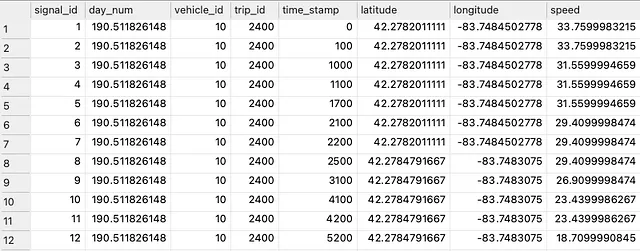
上記のデータはExtended Vehicle Energy Dataset(EVED) [1]の記事から引用しました。関連するデータベースは、私の以前の記事のコードに従って構築できます。
Quadkeysを使用した所要時間の推定
この記事では、Quadkeysでインデックス付けされた既知の速度ベクトルを使用して所要時間を推定する方法について説明します。
towardsdatascience.com
最初の作業は、これらの軌跡をサポートするデジタルマップにマッチングすることです。このステップの目的は、GPSデータのサンプリングエラーを除去するだけでなく、取得したトリップデータを既存の道路ネットワークに強制することです。ここでは、オープンソースのデータとソフトウェアを使用し、地図データはOpenStreetMap(Geofabrikによってコンパイル)、マップマッチングパッケージであるValhalla、およびジオスペーシャルトークナイザーとしてH3を使用します。
エッジ対ノードのマッチング
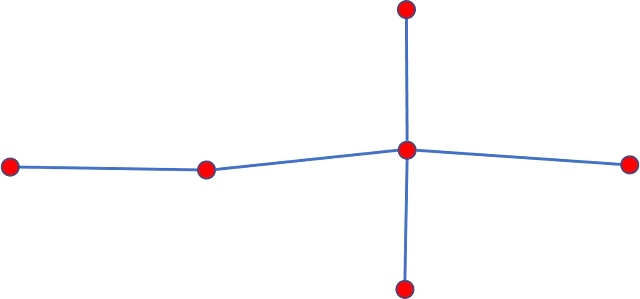
マップマッチングは初めに見るよりも複雑なものです。この概念を説明するために、以下の図2を見てみましょう。
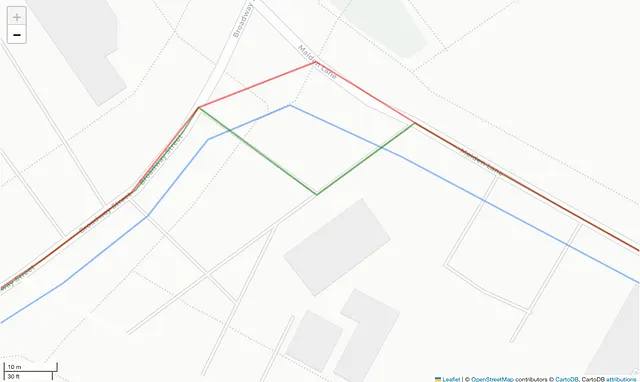
上記の図2からわかるように、オリジナルのGPSシーケンスから2つの軌跡を導出することができます。最初の軌跡は、元のGPS位置を最も近い(おそらく)道路ネットワークセグメントに投影することで得られます。結果として得られるポリラインは、道路に従うことがありますが、マップは基本的な形状を定義するためにグラフノードを使用しているため、常に道路に沿うわけではありません。元の位置をマップのエッジに投影することにより、直線で次の位置と接続されると、マップに属するがマップのジオメトリから外れる新しいポイントを得ることができます。
GPS軌跡をマップノードに投影することで、図2の緑の線で示されるように、マップと完全に一致する経路を得ることができます。この経路は初めにドライブされた軌跡をより正確に表現していますが、必ずしも元の位置と一対一の位置対応関係を持つわけではありません。幸いなことに、私たちは常にマップノードに対して任意の軌跡をマップマッチングするため、常に一貫したデータを得ることができます。ただし、Valhallaのマップマッチングコードは常に初期および最終軌跡ポイントをエッジに投影するため、それらはマップノードに対応しないため、システム的に破棄されます。
H3トークン化
残念ながら、Valhallaはユニークな道路ネットワークノード識別子を報告していないため、後でシーケンスの頻度計算に使用するためにノード座標を一意の整数トークンに変換する必要があります。ここでH3が登場し、ノード座標を64ビットの整数にユニークにエンコードすることができます。私たちはValhallaで生成されたポリラインを選び、初期と最終のポイント(これらのポイントはノードではなくエッジの投影です)を取り除き、残りの座標をレベル15のH3インデックスにマッピングします。
二重グラフ
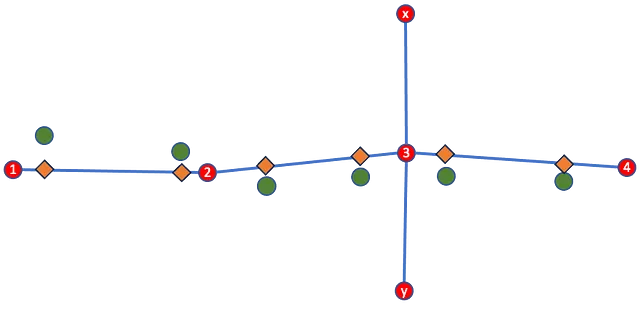
上記のプロセスを使用して、各過去の軌跡をH3トークンのシーケンスに変換します。次のステップは、各軌跡をトークンの三つ組のシーケンスに変換することです。シーケンス内の三つの値は、予測グラフの連続する2つのエッジを表し、これらの頻度を知ることが目的です。これらの頻度は予測と確率評価のための核となるデータとなります。図3はこのプロセスを視覚的に示しています。
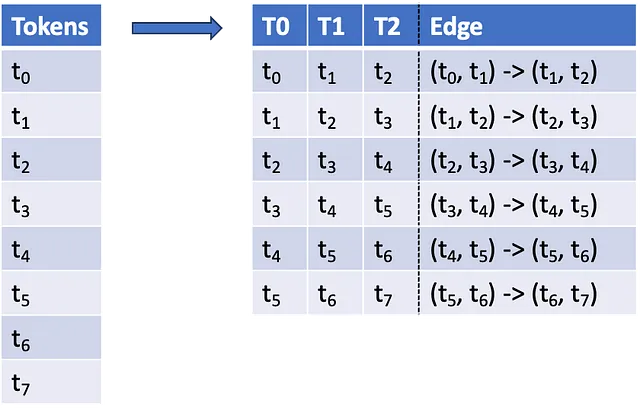
上記の変換は、元のノードとエッジの役割を逆転させて、道路グラフの双対を計算します。
これで、提案された質問に答えることができます。
その方向に進むべきですか?
この質問に答えるためには、与えられた瞬間までの車両の軌跡を知る必要があります。上記と同じプロセスで軌跡をマップマッチングし、トークン化し、既知の歴史的な頻度を使用して各軌跡トリプレットの頻度を計算します。最終結果は個々の頻度の積です。入力軌跡に不明なトリプレットがある場合、その頻度は最終的なパスの確率としてゼロになります。
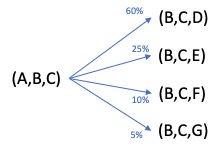
トリプレットの確率は、特定のシーケンス(A、B、C)のカウントを(A、B、*)トリプレットのカウントで割ったものです。以下の図4に示されています。
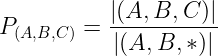
トリップの確率は、個々のトリップトリプレットの積です。以下の図5に示されています。

どこに行くのですか?
この質問に答えるためには、最後に知られているトリプレットから始めます。入力としてこのトリプレットを使用して、最も可能性の高いk個の後続トリプレットを列挙することで、トリプレットシーケンスの生成と評価を行います。以下の図6は、このプロセスを示しています。
上位k個の後続トリプレットを抽出し、最も可能性の高いトリップを予測するためにプロセスを繰り返すことができます。
実装
実装の詳細について説明します。まずは、マップマッチングと関連する概念から始めましょう。次に、PythonからValhallaツールセットを使用して、マッチングされたパスを抽出し、トークンシーケンスを生成する方法を見ていきます。データの前処理のステップは、結果をデータベースに保存することで完了します。
最後に、将来の手書き軌跡の確率を計算し、それをプロジェクトするためのシンプルなユーザーインターフェースをStreamlitを使用して示します。
マップマッチング
マップマッチングは、移動オブジェクトのパスからサンプリングされたGPS座標を既存の道路グラフに変換します。道路グラフは、ノードと接続エッジからなる基礎となる物理的な道路ネットワークの離散モデルです。各ノードは、道路上の既知の地理空間位置を表し、緯度、経度、高度のタプルとしてエンコードされます。各有向エッジは、基礎となる道路に沿って隣接するノードを接続し、ヘッディング、最大速度、道路の種類などの多くのプロパティを含んでいます。以下の図7は、簡単な例でこの概念を示しています。
成功した場合、マップマッチングプロセスはサンプルされた軌跡に関連性のある貴重な情報を生成します。一方で、プロセスはサンプルされたGPSポイントを最も可能性の高い道路グラフのエッジに沿って位置に投射します。マップマッチングプロセスは、観測されたスポットを推論された道路グラフのエッジ上に正確に配置することで、「修正」します。他方で、この方法はまた、サンプルされたGPS位置に対応する道路グラフを最も可能性の高いパスで再構築することにより、グラフノードの順序を再構成します。前述のように、これらの出力は異なります。最初の出力は最も可能性の高いパスのエッジ上の座標を含み、2番目の出力は再構築されたグラフノードのシーケンスで構成されています。以下の図8は、このプロセスを示しています。
マップマッチングプロセスの副産物は、共有の道路ネットワーク表現を使用して入力位置を標準化することです。特に、2番目の出力タイプである最も可能性の高いノードのシーケンスを考慮する場合に重要です。サンプルされたGPS軌跡をノードのシリーズに変換する際に、推論されたパスをノード識別子のシリーズに縮小することで、それらを比較可能にします。これらのノードのシーケンスは、既知の言語のフレーズと考えることができます。各推論されたノード識別子は単語であり、それらの配置は行動情報を伝えます。
これは、Extended Vehicle Energy Dataset¹ (EVED) [1] を探求する5番目の記事です。このデータセットは、以前の研究の改善とレビューであり、元のGPSサンプルされた位置のマップマッチングバージョン(図8のオレンジのダイヤモンド)を提供します。
残念ながら、EVEDには投影されたGPS位置しか含まれておらず、再構築された道路ネットワークのノードシーケンスが欠落しています。前の2つの記事では、マップマッチングを行わずに変換されたGPS位置から道路セグメントのシーケンスを再構築する問題に取り組みました。観測された欠陥のある再構築率(16%)よりも少ない結果となり、やや失望しました。以下の記事からこの議論を追うことができます。
三角形を使用した道路ネットワークのエッジマッチング
三角形は地理空間クエリにとって強力な特性を持つ
towardsdatascience.com
道路ネットワークマッチングのさらなる情報
道路ネットワークマッチングのいたずら
towardsdatascience.com
今度は、欠陥のある再構築を修正するために、ソースのマップマッチングツールを調べてみます。さあ、Valhallaを使って試してみましょう。以下に、ValhallaをDockerコンテナで実行するために使用した手順、参照、およびコードを示します。
Valhallaのセットアップ
ここでは、Sandeep Pandey氏[2]のブログで提供された手順に従います。
まず、マシンにDockerがインストールされていることを確認してください。Dockerエンジンをインストールするには、オンラインの手順に従ってください。Macを使用している場合、Colimaが優れた代替です。
インストール後、以下のコマンドをコマンドラインで実行して、GitHubからValhallaのイメージをプルする必要があります。以下の図9のシェルコードに示すように。
図9 — コマンドラインからValhallaのDockerイメージをプルする。 (画像の出典: 著者)
上記のコマンドを実行する際には、GitHubの資格情報を入力する必要があるかもしれません。また、この記事のGitHubリポジトリをクローンしておくことも、いくつかのファイルとフォルダ構造がそれに参照しているため必要です。
完了後、新しいターミナルウィンドウを開き、次のコマンドを実行してValhalla APIサーバーを起動する必要があります(MacOS、Linux、WSL):
図10 — 上記のコマンドは、Dockerコンテナ内で取得したValhallaイメージを実行します。初回の実行時には、コマンドが最新のGeofabrik Michiganデータファイルをダウンロードして準備するため、それらのステップも実行します。(画像の出典:著者)
上記のコマンドラインでは、GeofabrikサービスからダウンロードするOSMファイルを明示的に指定しています。この指定により、サーバーは初回実行時にファイルをダウンロードし、処理して最適化されたデータベースを生成します。以降の呼び出しでは、サーバーはこれらのステップを省略します。必要な場合は、ターゲットディレクトリの下にあるすべてを削除して、ダウンロードされたデータをリフレッシュし、再度Dockerを起動してください。
これで、特殊なクライアントを使用してValhalla APIを呼び出すことができます。
PyValhallaの使用
この派生プロジェクトは、素晴らしいValhallaプロジェクトへのPythonパッケージを提供します。
PyValhalla Pythonパッケージの使用は非常に簡単です。次のコマンドラインを使用して、きれいなインストール手順を開始します。
図11 — PIPを使用してPyValhallaをインストールできます。(画像の出典:著者)
Pythonコードでは、必要な参照をインポートし、処理されたGeoFabrikファイルから構成をインスタンス化し、最後にActorオブジェクトを作成する必要があります。これは、Valhalla APIへのゲートウェイです。
図12 — 上記のコードは、PythonアプリケーションまたはノートブックでPyValhallaを簡単にセットアップできる方法を示しています。(画像の出典:著者)
道路マッチングサービスを呼び出す前に、以下の図13にリストされた関数を使用して軌跡のGPS位置を取得する必要があります。
図13 — 上記の関数は、車両の軌跡の一意の位置をロードし、緯度、経度、およびタイムスタンプを持つPandas DataFrameを返します。(画像の出典:著者)
これで、マッチングルートを追跡するためにPyValhalla呼び出しに渡すパラメータディクショナリを設定できます。これらのパラメータの詳細については、Valhallaのドキュメントを参照してください。以下の関数は、Valhalla(Meili)のマップマッチング機能を呼び出し、緯度、経度、および時間のタプルとしてエンコードされた観測GPS位置を含むPandasデータフレームから推定されたルートを示しています。
図14 — 上記の関数は、PyValhalla Actorオブジェクトとソースパスを含むPandas DataFrameを受け入れ、マップマッチングされた文字列エンコードされたポリラインを返します。この文字列は、デジタルマップネットワークノードに対応するジオスペーシャルロケーションのリストに後でデコードされますが、端点はエッジ投影されます。(画像の出典:著者)
上記の関数は、マッチングされたパスを文字列エンコードされたポリラインとして返します。以下のデータ準備コードに示すように、PyValhallaライブラリの呼び出しを使用して返された文字列を簡単にデコードできます。なお、この関数は、ポリラインの最初と最後の位置がグラフノードではなくエッジに投影されることに注意してください。この記事の後半でコードによってこれらの端点が削除されるのを見ることができます。
次に、データの準備フェーズを見てみましょう。このフェーズでは、EVEDデータベースのすべての軌跡を既知のマップエッジシーケンスに変換し、そこからパターンの頻度を導出します。
データの準備
データの準備は、ノイズの多いGPSで取得した軌跡を既知のマップロケーションに対応するジオスペーシャルトークンのシーケンスに変換することを目的としています。メインのコードは既存のトリップを反復処理し、1つずつ処理します。
この記事では、すべてのデータ処理結果を保存するためにSQLiteデータベースを使用しています。まず、マッチングされた軌跡パスを埋めます。以下の図15の説明に従って、コードを使用できます。
図15 — 上記のコードには、前処理データのループが含まれています。このループは既知の軌跡を反復処理し、マップマッチングパス(ある場合)、ノードをトークン化し、それらをトリプレットに展開します。コードはすべての中間結果と最終結果をデータベースに保存します。(画像の出典:著者)
各軌跡に対して、Actorタイプのオブジェクトをインスタンス化します(9行目)。これは暗黙の要件です。マップマッチングサービスへの各呼び出しには新しいインスタンスが必要です。次に、車両のGPS受信機によって取得されたノイズが追加された軌跡ポイント(13行目)をロードします。14行目でValhallaにマップマッチングの呼び出しを行い、文字列エンコードされたマッチングパスを取得し、データベースに保存します。次に、文字列をジオスペーシャル座標のリストにデコードし(17行目)、端点を削除します(17行目)、そしてレベル15で計算されたH3インデックスのリストに変換します(19行目)。23行目では、変換されたH3インデックスと元の座標をデータベースに保存し、後で逆マッピングに使用します。最後に、25行から27行で、H3インデックスリストに基づいて3つ組のシーケンスを生成し、推論の計算のために保存します。
これらのステップを逐次説明していきます。
軌跡の読み込み
データベースから各軌跡をロードする方法については既に説明しました(図13を参照)。軌跡は、緯度と経度のペアとしてエンコードされたサンプリングされたGPS位置の時系列です。ここで、EVEDデータで提供されるマッチしたバージョンの位置ではなく、ノイズのあるオリジナルの座標を使用しています。これらの座標は、初期のVEDデータベースに存在したものです。
マップマッチング
マップマッチングサービスを呼び出すコードはすでに上記の図14で示されています。その中心的な問題は設定ですが、それ以外は非常に簡単な呼び出しです。エンコードされた文字列の保存も簡単です。
図16 — 上記のコードは、エンコードされたポリライン文字列を新しいデータベースに保存します。(画像の出所:著者)
メインループの17行目(図15)では、ジオメトリ文字列を緯度と経度のタプルのリストにデコードします。ここで、初期位置と最終位置を取り除くことに注意してください。次に、このリストを対応するH3トークンリストに変換します(19行目)。重複を避け、H3トークンとマップグラフのノードとの1対1の関係を確保するために、最大の詳細レベルを使用します。トークンをデータベースに挿入するには、次の2行を使用します。まず、トークンリスト全体を保存し、軌跡と関連付けます。
図17 — 上記の関数は、データベースに軌跡のH3トークンリストを挿入します。(画像の出所:著者)
次に、ノード座標とH3トークンのマッピングを挿入し、指定されたトークンリストからポリラインを描画できるようにします。この機能は、将来の旅行方向を推測する際に役立ちます。
図18 — H3トークンとノード座標のマッピングを挿入し、指定された推測トークンから軌跡を再構築します。(画像の出所:著者)
これで、対応するトークンのトリプルを生成して保存できます。以下の関数は、新たに生成されたH3トークンのリストを使用して、図3で詳細に説明されているように、別のトリプルのリストに展開します。展開コードは、以下の図19に示されています。
図19 — 上記のコードは、H3トークンのリストを対応するトリプルのリストに変換します。(画像の出所:著者)
トリプルの展開後、最終製品をデータベースに保存することができます。以下のコードは、図20に示されています。このテーブルのクエリを巧妙に使用することで、現在の旅行の確率と将来の最も可能性の高い軌跡を推論することができます。
図20 — 上記の関数は、H3トリプルをデータベースに保存します。これがデータ準備フェーズの最終ステップです。これで、収集した情報を探索することができます。(画像の出所:著者)
データ準備ループの1サイクルが完了しました。外部ループが完了すると、トークンシーケンスに変換されたすべての軌跡が含まれる新しいデータベースが得られます。
データ準備コード全体は、GitHubリポジトリで入手できます。
確率と予測
次に、既存の旅行の確率を推定し、将来の方向を予測する問題に取り組みます。まずは、「既存の旅行の確率」という言葉の定義から始めましょう。
旅行の確率
まず、道路ネットワークのノードに投影された任意のパスから始めます。したがって、マップ上のノードのシーケンスがあり、既知の旅行データベースを頻度の参照として、そのシーケンスがどれくらい確率的であるかを評価したいと考えています。この計算は、上記の図5の式を使用して行います。要するに、すべての個々のトークントリプルの確率の積を計算します。
この機能を説明するために、私は簡単なStreamlitアプリケーションを実装しました。このアプリケーションでは、ユーザーがカバーされているアンアーバーエリア上で任意のトリップを描画し、即座にその確率を計算できます。
ユーザーがトリップまたは仮想的なGPSサンプルを表す地図上のポイントを描画すると、コードはそれらをマップマッチングして基になるH3トークンを取得します。その後は、個々のトリプルの頻度を計算し、それらを掛け合わせて総確率を計算するだけです。図21の関数は、任意のトリップの確率を計算します。
図21 — 上記の関数は、三重周波数データベースから任意のパスの確率を計算します。 (画像出典: 著者)
このコードは、既存のH3トークンのペアの後続を取得する別の関数からサポートを受けます。以下の図22に示されている関数は、周波数データベースをクエリし、入力トークンペアのすべての後続のカウントを持つPythonのCounterオブジェクトを返します。クエリが後続を見つけない場合、関数はNone定数を返します。この関数は、データベースへのアクセス性能を向上させるためにキャッシュを使用していることに注意してください(コードはここには表示されていません)。
図22 — 上記の関数は、H3トークンの任意のペアの既知の後続を周波数データベースにクエリし、すべての後続のカウントを持つCounterオブジェクトを返します。 (画像出典: 著者)
私は両方の関数を設計しましたが、任意のノードに対して既知の後続が存在しない場合、計算される確率はゼロです。
次に、軌跡の最も確率の高い将来のパスを予測する方法を見てみましょう。
方向の予測
与えられた実行中のトリップから最も可能性の高い将来の方向を予測するには、最後の2つのトークンだけが必要です。アイデアは、そのトークンペアのすべての後続を展開し、最も頻度の高いものを選択することです。以下のコードは、方向予測サービスへのエントリーポイントとしての関数を示しています。
図23 — 上記の関数は、既存のユーザー提供のトリップの予測されるパスをFoliumのFeatureGroupオブジェクトに入れます。 (画像出典: 著者)
上記の関数では、ユーザーが描いた軌跡をマップマッチングされたH3トークンのリストとして取得し、最後のペアを抽出します。このトークンペアをシードと呼び、コードでさらに展開します。9行目では、シード展開関数を呼び出し、入力の展開条件であるイテレーションごとの最大の枝分かれと総イテレーション数に対応するポリラインのリストを返します。
以下の図24に示されているコードを追って、シード展開関数がどのように機能するか見てみましょう。
図24 — シード展開関数は、各イテレーションを管理するPredictedPathクラスを使用します。このクラスの詳細については、以下をご覧ください。 (画像出典: 著者)
初期パスから最も確率の高い後続パスを生成するパス展開関数を呼び出すことで、シード展開関数はパスを反復的に展開します。パスの展開は、パスを選択し、最も確率の高い展開を生成することによって行われます。以下の図25に示すように。
図25 — 上記のパス展開関数は、現在のパスの最も頻度の高い後続を反復処理します。各最頻後続に対して専用の関数を使用して新しいパスを作成します。 (画像出典: 著者)
コードは、後続ノードをソースパスに追加することで新しいパスを生成します。以下の図26に示すように。
図26 — 「子」パスを生成するには、既存のパスに後続ノードを追加するだけです。新しいノードを追加する前に、コードは元のパスのコピーを作成します。 (画像出典: 著者)
コードは、専用のクラスを使用して予測されるパスを実装しています。以下の図27に示されています。
図27 — 上記のクラスは、確率のソートのサポート、シードトークンペアからの作成、およびマップポリラインの生成を備えた予測パスを実装しています。 (画像出典: 著者)
アプリケーション
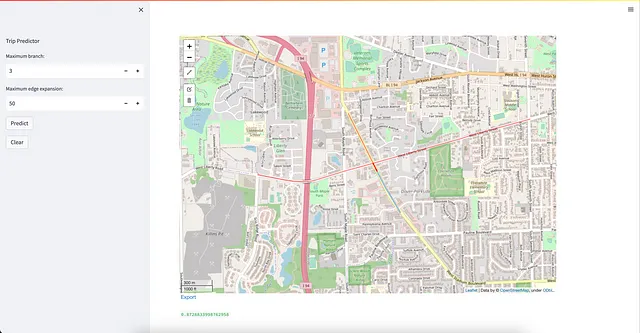
以下の図28に、結果として得られるStreamlitアプリケーションを示します。
結論
この記事では、デジタルマップ化された道路ネットワークを通過する車両の将来の軌跡を予測する手法を提案しました。過去の軌跡データベースを使用することで、この方法は任意の旅行に確率を割り当て、近い将来の最も可能性の高い方向を予測することもできます。したがって、この方法は、以前に見たことのない、ありえない軌跡を検出することができます。
興味のある地域からの車両の広範な軌跡データベースから始めます。各パスは、地理空間座標(緯度と経度)と速度などの関連する特性の時系列です。通常、これらの軌跡は車載GPS受信機から収集し、集中的にデータベースにまとめます。
GPSのサンプルは、信号測定中に発生する避けられないエラーによりノイズが発生します。都市の峡谷などの自然および人工の障害物により、信号の受信精度が著しく低下し、位置情報の誤差が増加することがあります。幸いなことに、この問題は確率的にGPSのサンプルをデジタルマップに一致させることで解決することができます。これがマップマッチングの目的です。
ノイズのあるGPSサンプルを既知のデジタルマップに一致させることで、各インスタンスをマップの最も可能性の高い道路セグメントに投影するだけでなく、車両がおそらく通過した既存のマップ定義された場所の離散的なシーケンスも取得します。この最後の結果は、軌跡予測において重要であり、ノイズのあるGPS座標のセットをデジタルマップ上のクリーンでよく知られているポイントの集合に変換します。これらのデジタルマーカーは固定されており、変更されることはなく、GPSサンプルのシーケンスをそれらに投影することで、後で予測に使用できるよく知られたトークンの文字列を得ることができます。
任意の軌跡とその将来の進化に対して既知のトークンシーケンスの頻度を使用してすべての確率を計算します。その結果、データの準備のためのPythonスクリプトと、Streamlitプラットフォームを使用したデータの入力と可視化のための別のPythonスクリプトが生成されます。
注釈
- 元の論文の著者は、データセットをApache 2.0ライセンスの下でライセンス供与しました(VEDおよびEVEDのGitHubリポジトリを参照してください)。これは派生作品にも適用されることに注意してください。
参考文献
[1] Zhang, S., Fatih, D., Abdulqadir, F., Schwarz, T., & Ma, X. (2022). Extended vehicle energy dataset (eVED): an enhanced large-scale dataset for deep learning on vehicle trip energy consumption. arXiv. https://doi.org/10.48550/arXiv.2203.08630
[2] Efficient and fast map matching with Valhalla — Sandeep Pandey (ikespand.github.io)
[3] Map Matching done right using Valhalla’s Meili | by Serge Zotov | Towards Data Science
João Paulo Figueira is a Data Scientist at tb.lx by Daimler Truck in Lisbon, Portugal.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
