チャーン予測とチャーンアップリフトを超えて
超える
因果データサイエンス
離脱の存在下での方針の最適な対象化方法

データサイエンスにおいて非常に一般的なタスクは離脱予測です。しかし、離脱予測はしばしば中間的なステップであり、最終目標ではありません。実際に私たちが本当に関心を持っているのは離脱の削減であり、これは別の目的であり、必ずしも関連しているわけではありません。実際には、例えば、長期の顧客は新規の顧客よりも離脱しにくいことを知っても、顧客の在籍期間を延長することはできないため、実行可能な洞察ではありません。代わりに、私たちが知りたいのは、1つ以上の処置が離脱にどのような影響を与えるかです。これはしばしば離脱の向上効果と呼ばれます。
この記事では、離脱予測や離脱の向上効果を超えて、離脱防止キャンペーンの究極の目標である収益の増加について考えてみます。まず、離脱を減らす方針は収益にも影響を与える可能性があるため、これを考慮する必要があります。しかし、さらに重要なことは、収益の増加は顧客が離脱しない場合にのみ関連があるということです。逆に、離脱の減少は高収益の顧客にとってより関連性があります。離脱と収益の相互作用は、どの処置キャンペーンの収益性を理解する上で重要であり、見落とすべきではありません。
ギフトと定期購読
この記事の残りの部分では、メインのアイデアを説明するためにおもちゃの例を使用します。私たちは顧客の離脱を減らし、最終的に収益を増やすことに関心がある会社であると仮定しましょう。新しいアイデアをテストすることに決めました:ユーザーに1ドルのギフトを送ること。この処置が機能するかどうかをテストするために、顧客ベースのサブサンプルにのみランダムに送りました。
cost = 1利用可能なデータを見てみましょう。データ生成プロセスdgp_gift()をsrc.dgpからインポートします。また、src.utilsからプロット関数とライブラリをインポートします。
from src.utils import *from src.dgp import dgp_giftdgp = dgp_gift(n=100_000)df = dgp.generate_data()df.head()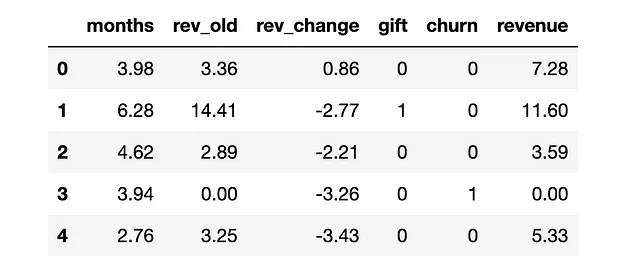
私たちは100_000人の顧客に関する情報を持っており、アクティブな顧客としての在籍期間のmonths、前月の生成収益(rev_old)、前月と前々月の収益の変化(rev_change)、ランダムに送られたgiftの有無、および興味のある2つのアウトカム:churn(つまり非アクティブな顧客かどうか)と現在の月のrevenueを観察します。アウトカムは字母Y、処置は字母W、その他の変数は字母Xで示します。
Y = ['churn', 'revenue']W = 'gift'X = ['months', 'rev_old', 'rev_change']注意:簡単のため、データの単一期間のスナップショットを考慮し、データのパネル構造をわずかな変数で要約しています。通常、より長い時系列がありますが、アウトカムに関してはより長い時間のホリゾンタルを持っています(例:顧客の生涯価値)。
以下の有向非循環グラフ(DAG)を使用して、基礎となるデータ生成プロセスを表現できます。ノードは変数を表し、矢印は潜在的な因果関係を表します。興味のある2つの関係、つまりgiftがchurnおよびrevenueに与える影響を緑色でハイライトしています。なお、離脱は定義上、収益をゼロにするため、収益と関連しています。
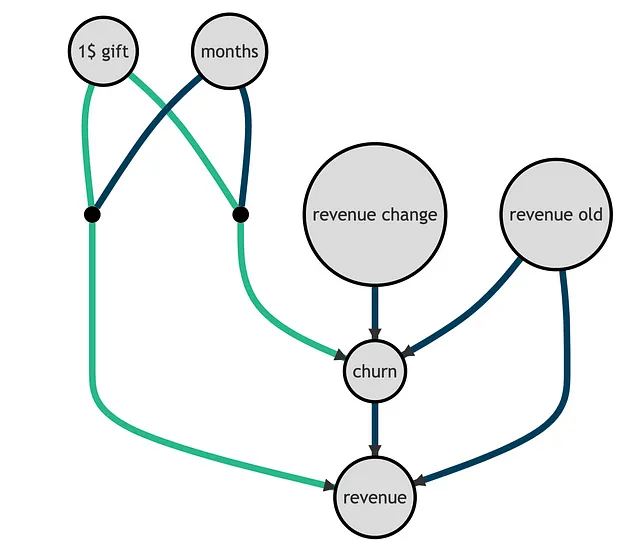
重要なことは、過去の収益と収益変化はchurnとrevenueの予測子であり、私たちの介入とは関係がありません。それに対して、介入は顧客の総アクティブmonthsに応じてchurnとrevenueに異なる影響を与えます。
このデータ生成プロセスは単純化されていますが、重要なinsightを捉えることを目指しています: churnまたはrevenueの良い予測子である変数は、必ずしもchurnまたはrevenueのliftを予測する変数ではありません。後で、これが私たちの分析にどのように影響を与えるかを見ていきます。
まずはデータの探索から始めましょう。
探索的データ分析
churnから始めましょう。会社は先月、いくつの顧客を失いましたか?
df.churn.mean()
0.19767会社は先月、顧客のほぼ20%を失いました! giftはchurnの防止に役立ちましたか?
私たちは、ギフトを受け取った顧客のchurn頻度とギフトを受け取っていない顧客のchurn頻度を比較したいと思います。ギフトはランダムに割り当てられたため、差分法で平均治療効果(ATE)を推定するためのバイアスのない推定量です。
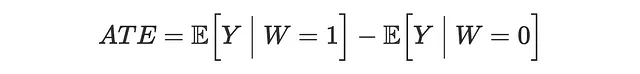
差分法の推定量を線形回帰で計算します。推定値の効率を向上させるために、他の共変量も含めます。
smf.ols("churn ~ " + W + " + " + " + ".join(X), data=df).fit().summary().tables[1]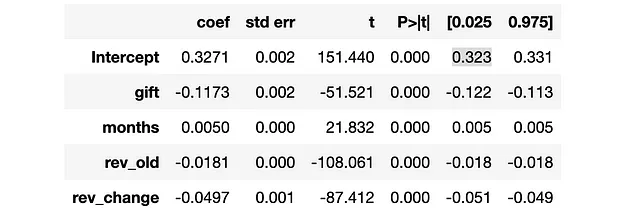
ギフトは、ベースラインの32%の約1/3に相当する11ポイント程度のchurnを減少させたようです! revenueにも影響を与えましたか?
churnと同様に、revenueをgift、つまり介入変数に回帰して平均治療効果を推定します。
smf.ols("revenue ~ " + W + " + " + " + ".join(X), data=df).fit().summary().tables[1]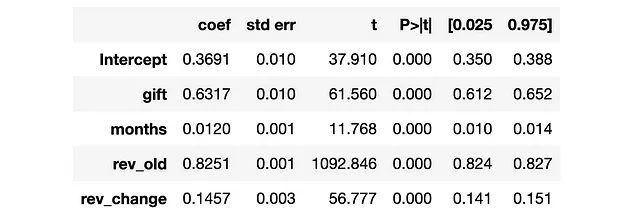
ギフトは平均して収益を0.63ドル増加させたようですが、これはprofitableではありませんでした。それはつまり、私たちは顧客にギフトを送るのをやめるべきですか?それは状況によります。実際、ギフトは特定の顧客セグメントに対して効果的かもしれません。ただ、それらを特定する必要があります。
ターゲティングポリシー
このセクションでは、収益を増やすことを目的として、データに基づいた効果的な方法でgiftを送る方法があるかどうかを理解しようとします。
このセクションでは、revenue、churn、またはgiftの受け取り確率を予測するために、いくつかのアルゴリズムが必要になります。私たちはlightgbmライブラリの勾配ブースティングツリーモデルを使用します。予測の精度によるパフォーマンスの違いを属性付けすることができないように、すべてのポリシーに同じモデルを使用します。
from lightgbm import LGBMClassifier, LGBMRegressor各方針τを評価するために、個々の人について、方針Π⁽¹⁾の収益と方針Π⁽⁰⁾の収益を、別の検証データセットで比較します。ただし、通常は不可能です。なぜなら、各顧客について、ギフトあり/なしの2つの可能な結果のうちの1つしか観測できないからです。しかし、私たちは合成データを扱っているため、オラクル評価が可能です。リアルデータでアップリフトモデルを評価する方法について詳しく知りたい場合は、私のイントロダクション記事をおすすめします。
アップリフトモデルの評価
業界での因果推論の最も普及した応用の1つは、アップリフトモデリング、別名推定…
2. ターゲット収益顧客
次に、異なる方針を試してみましょう。ギフトを高収益顧客にのみ送ることにします。例えば、収益によって上位10%の顧客にのみギフトを送ることが考えられます。この方針が本当に離脱率を減少させるのであれば、離脱率を減少させることがより利益につながる顧客です。
model_revenue = LGBMRegressor().fit(X=df[X], y=df['revenue'])policy_revenue = lambda df : (model_revenue.predict(df[X]) > np.quantile(df.revenue, 0.9))evaluate_policy(policy_revenue)
-4730.82この方針も再び利益を生み出さず、相当な損失につながります。以前と同様に、これはしきい値の選択の問題ではなく、以下のプロットからもわかります。最善の選択肢は、誰にも対応せず利益がゼロになるようにしきい値を非常に高く設定することです。
x = np.linspace(0, 100, 100)y = [evaluate_policy(lambda df : (model_revenue.predict(df[X]) > c)) for c in x]fig, ax = plt.subplots(figsize=(10, 3))sns.lineplot(x=x, y=y).set(xlabel='Revenue Policy Threshold', title='Aggregate Effect');ax.axhline(y=0, c='k', lw=3, ls='--');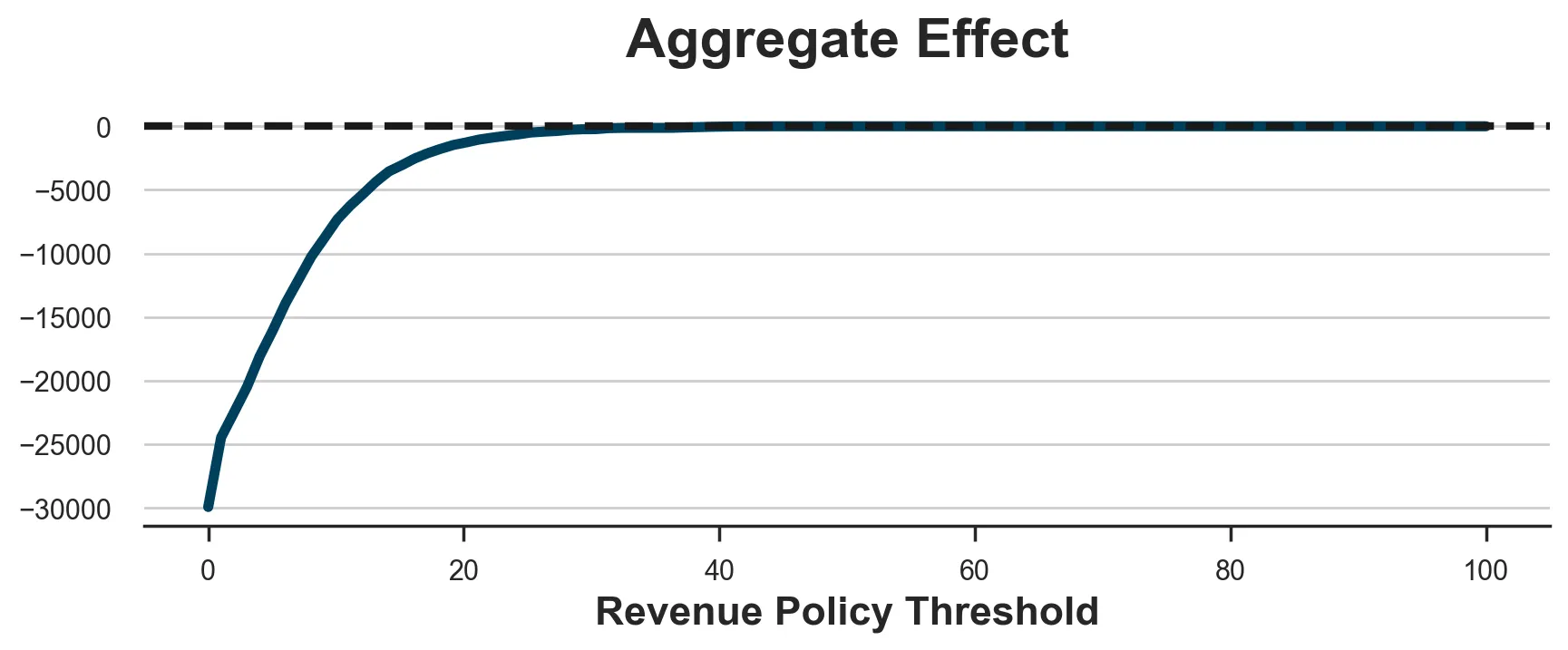
問題は、当社の設定では、高収益顧客の離脱確率が十分に減少しないため、giftが利益を生み出さないことです。これは、現実によく見られることですが、高収益顧客は離脱する可能性が最も低い顧客でもあります。
次に、より関連性のある一連の方針を検討しましょう。それは、upliftに基づく方針です。
3. ターゲット離脱アップリフト顧客
もっと合理的なアプローチは、1ドルのgiftを受け取ることで離脱確率が最も減少する顧客をターゲットにすることです。最も優れたアップリフトモデルの1つであるダブルロバスト推定器を使用して、離脱アップリフトを推定します。メタ学習に詳しくない場合は、まず私の入門記事から始めることをお勧めします。
メタ学習の理解
多くの設定では、因果効果を推定するだけでなく、この効果があるかどうかも興味があります…
towardsdatascience.com
私たちは、マイクロソフトのライブラリであるeconmlからダブルロバスト学習者をインポートします。
from econml.dr import DRLearnerDR_learner_churn = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())DR_learner_churn.fit(df['churn'], df[W], X=df[X]);離脱アップリフトを推定したので、単純に負のアップリフトが高い顧客にgiftを送ることに誘惑されるかもしれません(負のアップリフトなので、離脱を減少させたいです)。例えば、推定されたアップリフトが平均離脱よりも大きい顧客全員にgiftを送ることが考えられます。
policy_churn_lift = lambda df : DR_learner_churn.effect(df[X]) < - np.mean(df.churn)evaluate_policy(policy_churn_lift)
-3925.24この方針もまだ利益を生み出さず、ほぼ4000ドルの損失につながります。
問題は、方針のコストを考慮していないことです。実際、離脱確率を減少させることは高収益顧客に対してのみ利益を生み出すことです。極端な場合を考えてみましょう:収益を生み出さない顧客の離脱を回避することは、何の介入にも値しないのです。
したがって、ギフトのコストよりも収益によって重み付けられた離脱確率が減少する顧客にのみgiftを送ることにしましょう。
model_revenue_1 = LGBMRegressor().fit(X=df.loc[df[W] == 1, X], y=df.loc[df[W] == 1, 'revenue'])policy_churn_lift = lambda df : - DR_learner_churn.effect(df[X]) * model_revenue_1.predict(df[X]) > costevaluate_policy(policy_churn_lift)
318.03このポリシーは最終的に利益をもたらします!
ただし、まだ1つのチャネルを考慮していません:介入は既存顧客の収益にも影響を与える可能性があります。
4. ターゲット収益向上顧客
前のアプローチと対称的なアプローチは、収益への影響だけを考慮し、離脱への影響を無視することです。離脱しない顧客の収益向上を推定し、giftのコストよりも収益への増加効果が大きい顧客のみを扱うことができます。
DR_learner_netrevenue = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())DR_learner_netrevenue.fit(df.loc[df.churn==0, 'revenue'], df.loc[df.churn==0, W], X=df.loc[df.churn==0, X]);model_churn_1 = LGBMClassifier().fit(X=df.loc[df[W] == 1, X], y=df.loc[df[W] == 1, 'churn'])policy_netrevenue_lift = lambda df : DR_learner_netrevenue.effect(df[X]) * (1-model_churn_1.predict(df[X])) > costevaluate_policy(policy_netrevenue_lift)
50.80このポリシーも利益をもたらしますが、離脱への影響を無視しています。これを前のポリシーとどのように組み合わせるのでしょうか?
5. ターゲット収益向上顧客
離脱への影響と純収益への影響の両方を効果的に組み合わせる最良の方法は、単純に総収益向上を推定することです。最適なポリシーは、総収益向上がgiftのコストよりも大きい顧客を扱うことです。
DR_learner_revenue = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())DR_learner_revenue.fit(df['revenue'], df[W], X=df[X]);policy_revenue_lift = lambda df : (DR_learner_revenue.effect(df[X]) > cost)evaluate_policy(policy_revenue_lift)
2028.21これは非常に優れたポリシーであり、2000ドル以上の純利益を生み出しています!
すべての異なるポリシーを比較すると、結果は顕著です。
policies = [policy_churn, policy_revenue, policy_churn_lift, policy_netrevenue_lift, policy_revenue_lift] df_results = pd.DataFrame()df_results['policy'] = ['churn', 'revenue', 'churn_L', 'netrevenue_L', 'revenue_L']df_results['value'] = [evaluate_policy(policy) for policy in policies]fig, ax = plt.subplots()sns.barplot(df_results, x='policy', y='value').set(title='Overall Incremental Effect')plt.axhline(0, c='k');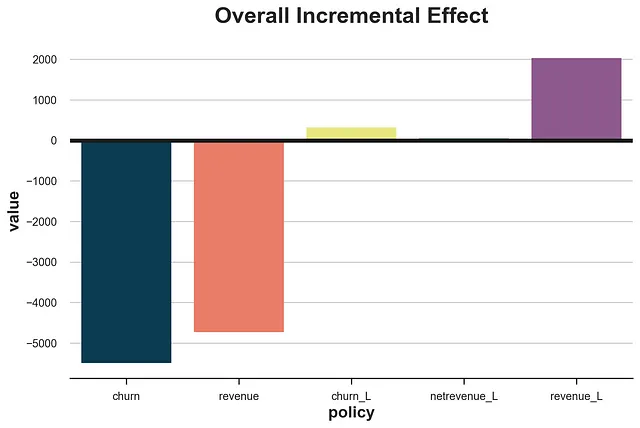
直感と分解
異なるポリシーを比較すると、高収益または高離脱確率の顧客を直接対象とすることが最悪の選択肢であることが明確です。これは必ずしも常に当てはまるわけではありませんが、私たちのシミュレートされたデータでは、次の2つの事実により発生しました。これらの事実は、多くの実際のシナリオでも一般的です:
- 収益と離脱確率は負の相関があります
giftのchurn(またはrevenue)への影響は、ベースラインの値と強く負の相関(またはrevenueの場合は正の相関)がありませんでした
これらの2つの事実のいずれか一つでも、収益または離脱を対象とすることは良い戦略ではありません。代わりに、高い増加効果を持つ顧客を対象にすることが最良です。そして、可能であれば、関心のある変数であるrevenueを直接使用することが最善です。
メカニズムをよりよく理解するために、ポリシーの利益への総合的な効果を3つのパートに分解することができます。

これにより、顧客に対する取り扱いが利益をもたらす3つのチャネルがあることが示唆されます。
- 高収益顧客であり、その取り扱いが離脱確率を減少させる場合
- 離脱しない顧客であり、その取り扱いが収益を増加させる場合
- その取り扱いが収益と離脱確率の両方に強い影響を与える場合
離脱アップリフトによるターゲティングは、最初のチャネルのみを利用し、正味収益アップリフトによるターゲティングは、2番目のチャネルのみを利用し、総収益アップリフトによるターゲティングは、3つのチャネルをすべて利用し、最も効果的な方法となります。
ボーナス:ウェイト付け
Lemmens, Gupta(2020)によって強調されているように、モデルのアップリフトを推定する際には、観測値にウェイトを付けることが価値がある場合があります。特に、処理方針のしきい値に近い観測値には、より高いウェイトを付ける価値があるかもしれません。
ウェイト付けは一般に推定器の効率を低下させる傾向があるという考え方があります。ただし、すべての観測値に対して正確な推定値を持つことに興味はありません。むしろ、方針のしきい値を正しく推定することに興味があります。実際に、純利益が1ドルでも1000ドルでも関係ありません。暗黙の方針は同じです:ギフトを送る。ただし、純利益が1ドルではなく-1ドルと推定されると、方針の意義が逆転します。したがって、しきい値からの正確性の低下が大きい場合には、しきい値での正確性のわずかな向上に見合う価値がある場合があります。
負の指数ウェイトを使用して、しきい値からの距離が減少するにつれてウェイトを減少させる方法を試してみましょう。
DR_learner_revenue_w = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())w = np.exp(1 + np.abs(DR_learner_revenue.effect(df[X]) - cost))DR_learner_revenue_w.fit(df['revenue'], df[W], X=df[X], sample_weight=w);policy_revenue_lift_w = lambda df : (DR_learner_revenue_w.effect(df[X]) > cost)evaluate_policy(policy_revenue_lift_w)
1398.19私たちの場合、ウェイト付けは価値がありません:暗黙の方針はまだ利益がありますが、ウェイトなしモデルよりも少ない、2028ドルです。
結論
この記事では、離脱予測や離脱アップリフトモデリングを超えて、利益の増加という最終的なビジネス目標に注力すべき理由と方法について説明しました。特に、予測からアップリフトに焦点を移し、離脱と収益を1つの結果に組み合わせる必要があります。
重要な注意点は、利用可能なデータの次元です。この記事では、問題を少なくとも2つの次元で大幅に単純化したおもちゃのデータセットを使用しました。まず、逆方向には通常、予測およびモデリングの目的に使用できるより長い時系列があります。さらに、前方には、離脱と顧客の長期的な収益見積もりである通常の顧客生涯価値を組み合わせる必要があります。
参考文献
- Kennedy(2022)、「Towards Optimal Doubly Robust Estimation of Heterogeneous Causal Effects」
- Bonvini、Kennedy、Keele(2021)、「Minimax Optimal Subgroup Identification」
- Lemmens、Gupta(2020)、「Managing Churn to Maximize Profits」
関連記事
- Upliftモデルの評価
- メタ学習の理解
- ダブルロバスト推定器であるAIPWの理解
コード
元のJupyter Notebookはこちらでご覧いただけます:
Blog-Posts/notebooks/beyond_churn.ipynb at main · matteocourthoud/Blog-Posts
コードおよびノートブックは、VoAGIブログ記事のためのものです。matteocourthoud/Blog-Postsの開発にご協力いただけます。
github.com
読んでいただきありがとうございます!
本当に感謝しています!🤗 もし記事が気に入ったらフォローしてください。私は因果推論やデータ分析に関連するトピックについて週に一度投稿しています。私の記事はシンプルで正確な情報を提供するよう心がけており、常にコード、例、シミュレーションを掲載しています。
また、免責事項もあります:私は学ぶために書いているため、ミスは普通ですが、最善を尽くしています。もしミスを見つけた場合は、教えていただけると幸いです。新しいトピックに関する提案も歓迎します!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
