3つの難易度レベルでベクトルデータベースを説明する
説明するベクトルデータベースの3つの難易度レベル
初心者からエキスパートへ:さまざまなバックグラウンドでのベクトルデータベースの解説
最近、ベクトルデータベースには多くの注目が集まっており、多くのベクトルデータベースのスタートアップが数百万ドルの資金を調達しています。
おそらく既に聞いたことがあるかもしれませんが、今までそれほど気にしていなかったかもしれません。少なくとも、それがなぜ今ここにいるのかを推測するところです…
もしも短い答えだけを求めてここに来たのであれば、さっそく始めましょう:
定義:ベクトルデータベースとは何ですか?
ベクトルデータベースは、テキスト、画像、音声などの非構造化データをベクトル埋め込み(高次元ベクトル)で保存・管理し、類似のオブジェクトを迅速に検索・取得することが容易になるようにするデータベースの一種です。
もしもその定義がますます混乱を招いた場合は、段階的に進めましょう。この記事はWIREDの「5 Levels」ビデオシリーズに触発され、以下の3つの難易度レベルでベクトルデータベースについて解説します:
- 5歳になったつもりで説明する
- デジタルネイティブやテック愛好家にベクトルデータベースを説明する
- エンジニアやデータプロフェッショナルにベクトルデータベースを説明する
ベクトルデータベース:5歳になったつもりで説明する(ELI5)
これは少し話が逸れますが、わたしが理解できないのは分かりますか?
人々が本棚を色で整理する理由です。— やっぱりなんだかなぁ!
本の表紙の色がわからないときに本を見つける方法はどうすればいいのでしょうか?
ベクトルデータベースの直感
特定の本を素早く見つけたい場合、ジャンルや著者ではなく、本棚をジャンルと著者で整理する方がはるかに合理的です。そのため、多くの図書館はこのような方法で整理されており、必要な本を素早く見つけるのに役立ちます。
しかし、ジャンルや著者ではなく、クエリに基づいて読むものを見つけるにはどうすればいいでしょうか?例えば、以下のような本を読みたい場合は:
- 「はらぺこあおむし」と似ている本、または
- 自分と同じくらい食べることが好きな主人公についての本?
本棚をブラウズする時間がない場合、最も速い方法は司書におすすめを聞くことです。なぜなら、彼らはたくさんの本を読んでいるので、クエリに最適な本を正確に知っているからです。
本の整理の例において、司書はベクトルデータベースのようなものと考えることができます。なぜなら、ベクトルデータベースはオブジェクト(本など)についての複雑な情報(例:プロット)を保存するために設計されているからです。そのため、ベクトルデータベースは、いくつかの事前定義された属性(例:著者)ではなく、特定のクエリ(例:「…についての本」)に基づいてオブジェクトを見つけるのに役立ちます。まるで司書のようです。
デジタルネイティブやテック愛好家にベクトルデータベースを説明する
さて、図書館の例にとどまり、少し技術的な話に入りましょう:もちろん、これらの日々、ジャンルや著者だけで本を検索するためのより高度な技術があります。
図書館を訪れると、通常はコーナーにコンピュータがあり、タイトル、ISBN、出版年などのより詳細な属性に基づいて本を検索するのに役立ちます。入力した値に基づいて、利用可能な本のデータベースがクエリされます。このデータベースは通常、伝統的な関係データベースです。

リレーショナルデータベースとベクトルデータベースの違いは何ですか?
リレーショナルデータベースとベクトルデータベースの主な違いは、それらが保持するデータの種類にあります。リレーショナルデータベースは、テーブルに収まる構造化データに適した設計となっており、一方でベクトルデータベースはテキストや画像などの非構造化データを扱うことを意図しています。
格納されるデータの種類はまた、データの検索方法にも影響を与えます。リレーショナルデータベースでは、クエリの結果は特定のキーワードに基づく一致によって得られます。一方、ベクトルデータベースでは、クエリの結果は類似性に基づいています。
伝統的なリレーショナルデータベースはスプレッドシートのようなものと考えることができます。これらは、本に関する基本情報(タイトル、著者、ISBNなど)などの構造化データを格納するのに適しています。なぜなら、この種の情報は列に格納され、フィルタリングやソートに適しているからです。
リレーショナルデータベースでは、例えば子供向けの本でタイトルに「caterpillar」というキーワードが含まれている本をすばやく取得することができます。
しかし、「The Very Hungry Caterpillar」が食べ物についての本だと知っていた場合、キーワード「食べ物」で検索してみるかもしれません。しかし、「食べ物」というキーワードが本の概要に言及されていない限り、「The Very Hungry Caterpillar」を見つけることはできません。代わりに、おそらく料理本がいくつか出てきて失望するでしょう。
これがリレーショナルデータベースの制限の一つです。特定のアイテムを見つけるために必要なすべての情報を追加する必要があります。しかし、どの情報が必要で、どのくらいの情報を追加するかをどのように知ることができるでしょうか?このような情報をすべて追加することは時間がかかり、完全性を保証するものではありません。
ここでベクトルデータベースが登場します!
しかし、まずは「ベクトル埋め込み」と呼ばれる概念の少しの説明から始めましょう。
現在の機械学習(ML)アルゴリズムは、与えられたオブジェクト(単語やテキストなど)を、そのオブジェクトの情報を保持する数値表現に変換することができます。例えば、MLモデルに単語(例:「食べ物」)を与えると、そのMLモデルが魔法をかけて長い数値のリストを返します。この長い数値のリストが単語の数値表現であり、ベクトル埋め込みと呼ばれます。
これらの埋め込みは、長い数値のリストなので、高次元と呼ばれます。以下に示すように、これらの埋め込みを3次元に限定して可視化すると、似たような単語(「hungry」、「thirsty」、「食べ物」、「飲み物」)が同じコーナーにグループ化され、他の単語(「自転車」、「車」)は近くにありますが別のコーナーにあります。
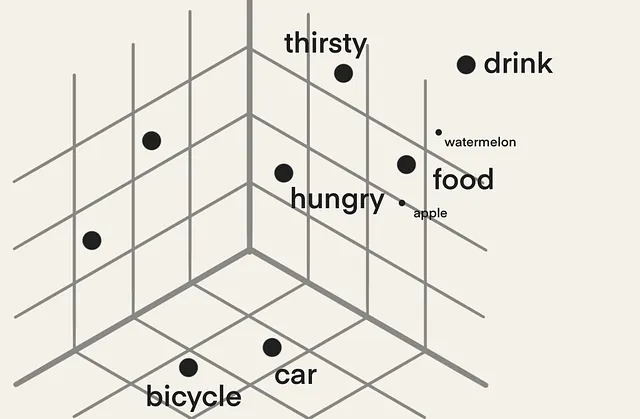
数値表現により、通常計算には適していない単語などのオブジェクトに数学的な計算を適用することができます。たとえば、次の計算は、単語を埋め込みに置き換えない限り機能しません:
drink - food + hungry = thirstyそして、埋め込まれたオブジェクトの間の距離を計算することもできます。埋め込まれたオブジェクト同士が近ければ近いほど、より類似しています。
ベクトル埋め込みは非常にクールですね。
さて、例に戻って、図書館のすべての本の内容を埋め込んで、これらの埋め込みをベクトルデータベースに格納するとします。それでは、「食べ物が好きな主人公の子供向けの本」を見つけたい場合、クエリも埋め込まれ、クエリに最も類似している本が返されます。例えば、「The Very Hungry Caterpillar」や「Goldilocks and the Three Bears」などです。
ベクトルデータベースの使用例は何ですか?
ベクトルデータベースは、大規模な言語モデル(LLM)のハイプが始まる前から存在していました。もともとは推薦システムで使用されていましたが、LLMに長期的なメモリを提供できるため、最近では質問応答アプリケーションでも使用されています。
エンジニアやデータ専門家へのベクトルデータベースの説明
もしもあなたがこの記事を開く前にベクトルデータベースはおそらくベクトル埋め込みを保存する方法であると予想していて、裏側でベクトル埋め込みとは何かを知りたいだけなら、細かいことについて話してアルゴリズムについて話しましょう。
ベクトルデータベースはどのように動作するのですか?
ベクトルデータベースは、既に事前に計算されているため、クエリと類似したオブジェクトを高速に取得することができます。その基本的な概念は、近似最近傍探索(ANN)と呼ばれ、インデックス化と類似度の計算に異なるアルゴリズムを使用します。
シンプルなk最近傍法(kNN)アルゴリズムを使用してクエリと持っているすべての埋め込みオブジェクト間の類似度を計算すると、数百万の埋め込みがある場合には時間がかかることが想像できます。ANNを使用することで、クエリに対してほぼ最も類似したオブジェクトを取得するために、一部の精度を犠牲にすることができます。
インデックス化 — これにより、ベクトルデータベースはベクトル埋め込みをインデックス化します。このステップでは、ベクトルをより高速な検索が可能なデータ構造にマッピングします。
インデックス化は、図書館の本を著者やジャンルなどの異なるカテゴリに分類することと考えることができます。ただし、埋め込みにはより複雑な情報を持たせることができるため、「主人公の性別」や「プロットの主な場所」といったさらなるカテゴリが存在するかもしれません。したがって、インデックス化は利用可能なベクトルの一部を取得するのに役立ち、検索を高速化することができます。
インデックス化アルゴリズムの技術的な詳細には触れませんが、興味がある場合は、Hierarchical Navigable Small World(HNSW)を調べることから始めてみてください。
類似度の測定 — インデックス化されたベクトルからクエリに対して最も近い隣接オブジェクトを見つけるために、ベクトルデータベースは類似度の測定を適用します。一般的な類似度の測定方法には、コサイン類似度、内積、ユークリッド距離、マンハッタン距離、ハミング距離などがあります。
ベクトルデータベースとNumPy配列にベクトル埋め込みを保存することの利点は何ですか?
私がよく聞かれる質問は「埋め込みを保存するために単にNumPy配列を使用できないのですか?—」です。もちろん、埋め込みが多くない場合や楽しい趣味のプロジェクトであれば、NumPy配列を使用することもできます。ただし、ベクトルデータベースは埋め込みが多い場合には明らかに高速であり、すべてをメモリに保持する必要もありません。
私はこれを短く説明しますが、Ethan Rosenthal氏がベクトルデータベースとNumPy配列の使用の違いを非常に上手に説明しているので、私が書くよりもはるかに良い仕事をしています。
実際にベクトルデータベースは必要ですか? | Ethan Rosenthal
ネタバレ:答えは「おそらく」です!ただし、「実際に」という言葉の含まれ方は私の偏見を裏切っています。ベクトルデータベースは…
www.ethanrosenthal.com
この記事が気に入りましたか?
新しい記事を公開すると通知を受け取るために無料で購読してください。
1か月に3つ以上の無料記事を読みたいですか? — 月額5ドルでVoAGIメンバーになることができます。サインアップ時に私の紹介リンクを使用していただければ、私には追加費用はかかりません。
私の紹介リンクでVoAGIに参加する — Leonie Monigatti
Leonie Monigatti(およびVoAGIの他の数千人の作家のすべてのストーリー)を読む。会費は直接…
VoAGI.com
LinkedIn、Twitter、Kaggleでも見つけてください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 今日、開発者の70%がAIを受け入れています:現在のテックの環境での大型言語モデル、LangChain、およびベクトルデータベースの台頭について探求する
- マイクロソフトの研究者たちは、ラベル付きトレーニングデータを使用せずにパレート最適な自己監督を用いたLLMキャリブレーションの新しいフレームワークを提案しています
- AI、デジタルツインが次世代の気候研究イノベーションを解き放つ
- HTMLの要約:IIoTデータのプライバシー保護のためのGANとDPのハイブリッドアプローチ
- インデータベース分析:SQLの解析関数の活用
- 深層学習を用いた強力なレコメンデーションシステムの構築
- ML プレゼンテーションに PowerPoint を使うのをやめて、代わりにこれを試してみてください
