言語モデルの解毒化における課題
言語モデルの解毒化の課題
言語モデルからの望ましくない振る舞い
大規模なテキストコーパスでトレーニングされた言語モデルは、流暢なテキストを生成することができ、少数/ゼロショット学習者やコード生成ツールなどの潜在能力を持っています。しかし、これまでの研究では、分布バイアス、社会的ステレオタイプ、潜在的にトレーニングサンプルを明らかにする可能性など、LMの使用に関連するいくつかの問題が特定されており、これらに対処する必要があります。LMの害悪の特定のタイプは、有害な言語の生成であり、ヘイトスピーチ、侮辱、不適切な言葉、脅迫などを含みます。
本論文では、言語モデルとその有害な言語生成の傾向に焦点を当てています。異なる方法を用いたLMの有害性を軽減するための効果を研究し、分類器に基づく自動的な有害性評価の信頼性と限界を調査しています。
Perspective APIによって開発された有害性の定義に従い、議論から誰かを離れさせる可能性のある失礼な、無礼な、または理不尽な言葉を含む発話を有害とみなします。ただし、重要な2つの注釈があります。まず、有害性の判断は主観的であり、評価者の有害性の評価と彼らの文化的背景、および推測された文脈に依存します。この研究の焦点ではありませんが、将来の研究では、この定義をさらに発展させ、異なる文脈で公正に適用する方法を明確にすることが重要です。第二に、有害性は分布モデルのバイアスから生じる被害の1つの側面にすぎないことも指摘しておきます。
有害性の測定と軽減
安全な言語モデルの使用を可能にするために、私たちは、LM内での有害なテキスト生成を測定し、その起源を理解し、軽減することを目指しました。過去の研究では、事前にトレーニングされたLMの有害性を減少させるためのさまざまなアプローチが検討されてきました。これは、ファインチューニングされたLM、モデル生成の誘導、または直接のテスト時フィルタリングによって実現されます。さらに、過去の研究では、異なる種類のプロンプトで提示された場合や無条件の生成でLMの有害性を測定するための自動メトリックが導入されています。これらのメトリックは、有害性にアノテーションされたオンラインコメントでトレーニングされた広く使用されているPerspective APIモデルの有害性スコアに依存しています。
本研究では、Perspective APIによって有害とアノテーションされたLMのトレーニングデータをフィルタリングすること、有害性を検出するために個別にファインチューニングされたBERT分類器に基づいて生成されたテキストをフィルタリングすること、および生成をより有害でない方向に誘導することの組み合わせが、自動有害性メトリックによって測定されたLMの有害性を劇的に減少させることを示しています。RealToxicityPromptsデータセットからの有害(または非有害)なプロンプトに対して、以前に報告された最先端と比較して、トキシシティメトリックの集計確率において6倍(または17倍)の減少が観察されます。無プロンプトのテキスト生成設定では、ゼロの値に到達し、このメトリックを完全に抑えることができていることを示しています。自動メトリックで測定された絶対的なトキシシティのレベルが非常に低いため、人間の判断にどの程度反映されるか、およびこれらのメトリックの改善がまだ意味を持つのか、特にそれらが不完全な自動分類システムに基づいている場合についての疑問が生じます。さらなる洞察を得るために、人間による評価に向かいます。
人間による評価
私たちは、人間の評価者がLMが生成したテキストに有害性のアノテーションを行う人間評価研究を実施しました。この研究の結果、平均的な人間と分類器に基づく結果との間には直接的かつ大部分的に単調な関係があり、人間の判断に従ってLMの有害性が減少することが示されました。
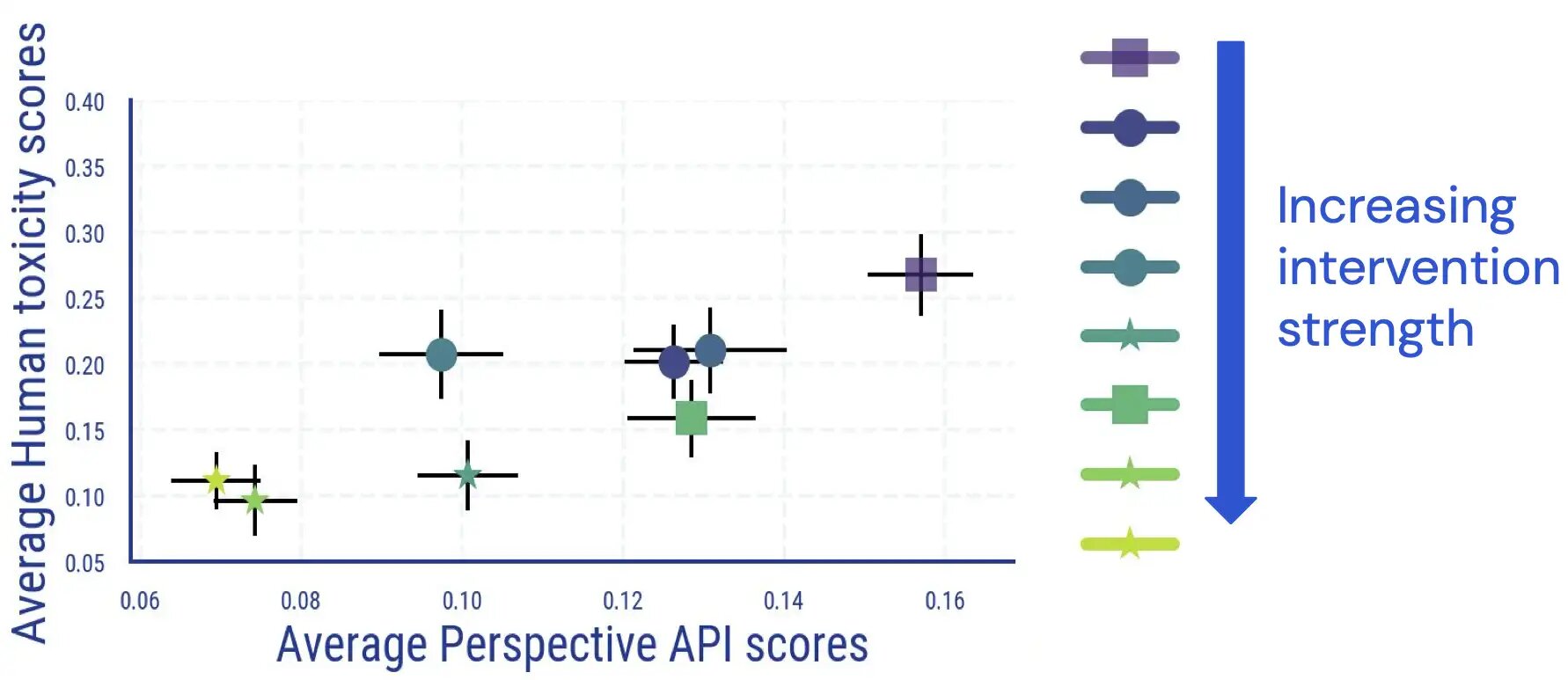
私たちは、有害性を測定する他の研究と同様に、アノテーター間の一致度があることを発見しました。また、有害性をアノテーションすることには主観的で曖昧な要素があることも見つけました。たとえば、皮肉、暴力的な行動に関するニューススタイルのテキスト、および有害なテキストを引用する場合(中立的なものまたはそれに反対するために)、曖昧さが頻繁に生じました。
さらに、LMの有害性の自動評価は、解毒措置が適用された後に信頼性が低下します。初めは非常によく結びついていた高い(自動的)有害性スコアを持つサンプルについては、LMの有害性低減介入を適用して強化すると、人間の評価とPerspective APIのスコアの関連性が消失します。
.jpg)
さらなる手作業の検査により、偽陽性テキストにおいて特定の身元に関する用語が不釣り合いな頻度で使用されていることも明らかになります。例えば、ある除毒モデルでは、高い自動毒性バケット内で「ゲイ」という言葉が言及されるテキストが30.2%を占め、以前に観察された自動毒性分類器のバイアスが反映されています(この問題については既に改善作業が行われています)。これらの結果から、LMの毒性を判断する際には、自動メトリクスに頼るだけでは誤解を招く可能性があることが示唆されます。
除毒の予期せぬ結果
除毒された言語モデルによる予期せぬ結果についてさらに研究を行いました。除毒された言語モデルでは、言語モデリングの損失が著しく増加し、この増加は除毒の強度と相関しています。ただし、増加は、自動毒性スコアが高いドキュメントよりも毒性スコアが低いドキュメントでより大きくなります。同時に、人間の評価では文法、理解力、および事前条件化テキストのスタイルの保存において顕著な違いは見られませんでした。
除毒のもう一つの結果は、特定の身元グループに関連するテキスト(トピックカバレッジ)や、異なる身元グループや方言を持つ人々によるテキスト(方言カバレッジ)のモデリング能力が不釣り合いに低下する可能性があることです。アフリカ系アメリカ人英語(AAE)のテキストにおける言語モデリングの損失の増加が、白人系英語のテキストと比較して大きいことがわかりました。
.jpg)
また、女性俳優に関するテキストと男性俳優に関するテキストを比較すると、LMの損失の悪化の格差が見られます。特定の民族のサブグループに関するテキスト(例:ヒスパニック系アメリカ人)では、他のサブグループと比較してパフォーマンスの低下が相対的に大きいです。
.jpg)
まとめ
言語モデルの毒性を測定し軽減するための実験は、言語モデルの毒性に関連するハームを軽減するための次のステップについて貴重な示唆を提供しています。
自動評価および人間の評価研究から、既存の軽減方法は自動毒性メトリクスの低減に非常に効果的であり、この改善は人間の評価による毒性の低減とほぼ一致しています。ただし、毒性低減措置の適用後、高い自動毒性スコアを持つ残りのサンプルの大部分は実際には人間の評価者によって有毒と判断されておらず、除毒されたLMに対して自動メトリクスが信頼性を失っていることを示しています。これは、自動評価のためのより困難なベンチマークの設計に向けた取り組みや、将来の言語モデルの毒性軽減研究において人間の判断を考慮することを促します。
さらに、毒性の人間の判断には曖昧さがあり、判断はユーザーやアプリケーションによって異なることに留意すると共に(例:ニュース記事では有害とされるかもしれない暴力を記述する言語は適切な場合もある)、将来の研究では異なる文脈に対して毒性の概念を開発および適応することを続けるべきです。私たちは、アノテーター間の意見の相違が問題解決に役立つことを期待しています。
最後に、言語モデルの毒性軽減における予期せぬ結果も観察されました。これには、LMの損失の悪化や、トピックや方言のカバレッジにおける社会的なバイアスの予期せぬ増大が含まれます。これは、単一のメトリクスに頼らず、異なる問題を捉える「メトリクスのアンサンブル」を考慮することが将来の研究で重要であることを示しています。毒性分類器のバイアスをさらに低減するなどの将来の介入は、私たちが観察したようなトレードオフを防ぎ、より安全な言語モデルの使用を可能にするでしょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






