ロボットスキル合成のための言語から報酬への変換
言語から報酬への変換
Googleの研究科学者、Wenhao YuとFei Xiaによる投稿
エンドユーザーがロボットに新しいタスクを教えるためのインタラクティブな機能を持つことは、実世界の応用において重要な能力です。例えば、ユーザーはロボット犬に新しいトリックを教えたり、マニピュレータロボットにユーザーの好みに基づいてランチボックスの整理方法を教えたりすることがあります。大量の言語モデルが、インターネット上の広範なデータで事前学習された最近の進歩は、この目標を達成するための有望な道を示しています。実際、研究者たちは、LLMをロボットに活用するためのさまざまな方法を探索しています。それは、ステップバイステップの計画や目標指向の対話からロボットコードの生成までです。
これらの方法は、新しい行動の構成的一般化の新しい方法を提供しますが、既存の制御原理のライブラリーから新しい行動をリンクするために言語を使用することに焦点を当てています。これらの制御原理は、手動で設計されるか、あらかじめ学習されるものです。ロボットの動きに関する内部知識を持っているにもかかわらず、LLMは関連するトレーニングデータが限られているため、低レベルのロボットコマンドを直接出力することが困難です。その結果、これらの方法の表現は、使用可能な基本要素の幅によって制約されます。これらの基本要素の設計は、広範な専門知識や大量のデータ収集を必要とすることがしばしばあります。
「Language to Rewards for Robotic Skill Synthesis」では、自然言語入力を介してユーザーがロボットに新しいアクションを教える手法を提案しています。これを行うために、言語と低レベルのロボットアクションの間のギャップを埋めるインターフェースとして報酬関数を活用しています。報酬関数は、その意味、モジュール性、解釈性の豊かさから、このようなタスクにとって理想的なインターフェースを提供します。また、報酬関数は、ブラックボックス最適化や強化学習(RL)を介した低レベルポリシーへの直接的な接続を提供します。我々は、LLMsを活用して自然言語のユーザー指示を報酬指定コードに翻訳し、それからMuJoCo MPCを適用して生成された報酬関数を最大化する最適な低レベルのロボットアクションを見つける言語から報酬へのシステムを開発しました。我々は、四足歩行ロボットと器用なマニピュレータロボットを使用して、シミュレーション上のさまざまなロボット制御タスクで我々の言語から報酬へのシステムを実証しました。さらに、物理的なロボットマニピュレータでも我々の手法を検証しました。
言語から報酬へのシステムは、2つの主要なコンポーネントで構成されています:(1)報酬トランスレータ、および(2)モーションコントローラ。報酬トランスレータは、ユーザーの自然言語の指示をPythonコードとして表される報酬関数にマッピングする役割を担っています。モーションコントローラは、与えられた報酬関数を最適化するために、リシーディングホライズン最適化を使用して、ロボットモーターごとに適用されるトルクの量などの最適な低レベルのロボットアクションを見つけます。
 |
| LLMsは、事前学習データセット内のデータが不足しているため、直接的に低レベルのロボットアクションを生成することができません。我々は報酬関数を使用して、言語と低レベルのロボットアクションのギャップを埋め、自然言語の指示から新しい複雑なロボットモーションを実現することを提案しています。 |
報酬トランスレータ:ユーザーの指示を報酬関数に翻訳する
報酬トランスレータモジュールは、自然言語のユーザー指示を報酬関数にマッピングすることを目指して構築されました。報酬の調整は、特定のハードウェアに対して専門知識が必要なため、一般的な言語データセットで訓練されたLLMsが特定の報酬関数を直接生成できないことは驚くべきことではありませんでした。これを解決するために、LLMsのインコンテキスト学習能力を適用しました。さらに、報酬トランスレータをモーションディスクリプタと報酬コーダーの2つのサブモジュールに分割しました。
モーションディスクリプタ
まず、モーションディスクリプタを設計し、ユーザーからの入力を解釈して、あらかじめ定義されたテンプレートに従ったロボットの動きの自然言語の説明に展開します。このモーションディスクリプタは、曖昧またはあいまいなユーザーの指示をより具体的で具体的なロボットの動きに変換し、報酬コーディングのタスクをより安定させます。さらに、ユーザーはモーションの説明フィールドを介してシステムと対話するため、これは報酬関数を直接表示するよりもユーザーにとってより解釈可能なインターフェースも提供します。
モーションディスクリプタを作成するために、ユーザーの入力をLLMで翻訳し、希望するロボットの動作の詳細な説明に変換します。 LLMが適切な詳細度と形式でモーションの説明を出力するようにガイドするプロンプトを設計します。 あいまいなユーザーの指示をより詳細な説明に翻訳することで、システムで報酬関数をより信頼性の高い方法で生成することができます。 このアイデアは、ロボットのタスクを超えて一般的に応用することも可能であり、Inner-Monologueとchain-of-thoughtのプロンプトに関連しています。
Reward Coder
第2ステージでは、モーションディスクリプタと同じLLMをリワードコーダーに使用し、生成されたモーションの説明をリワード関数に変換します。 リワード関数は、リワード、コーディング、およびコードの構造に関するLLMの知識を活用するためにPythonコードを使用して表現されます。
理想的には、LLMを使用してロボットの状態sと時間tをスカラーの報酬値にマッピングする報酬関数R(s、t)を直接生成したいと考えています。 ただし、正しい報酬関数をゼロから生成することは、LLMにとってまだ難しい問題であり、エラーを修正するにはユーザーが生成されたコードを理解し、正しいフィードバックを提供する必要があります。 そのため、興味のあるロボットで一般的に使用される一連の報酬項を事前に定義し、LLMが異なる報酬項を組み合わせて最終的な報酬関数を形成することを許可します。 これを実現するために、報酬項を指定し、タスクに適した正しい報酬関数を生成するようにLLMをガイドするプロンプトを設計します。
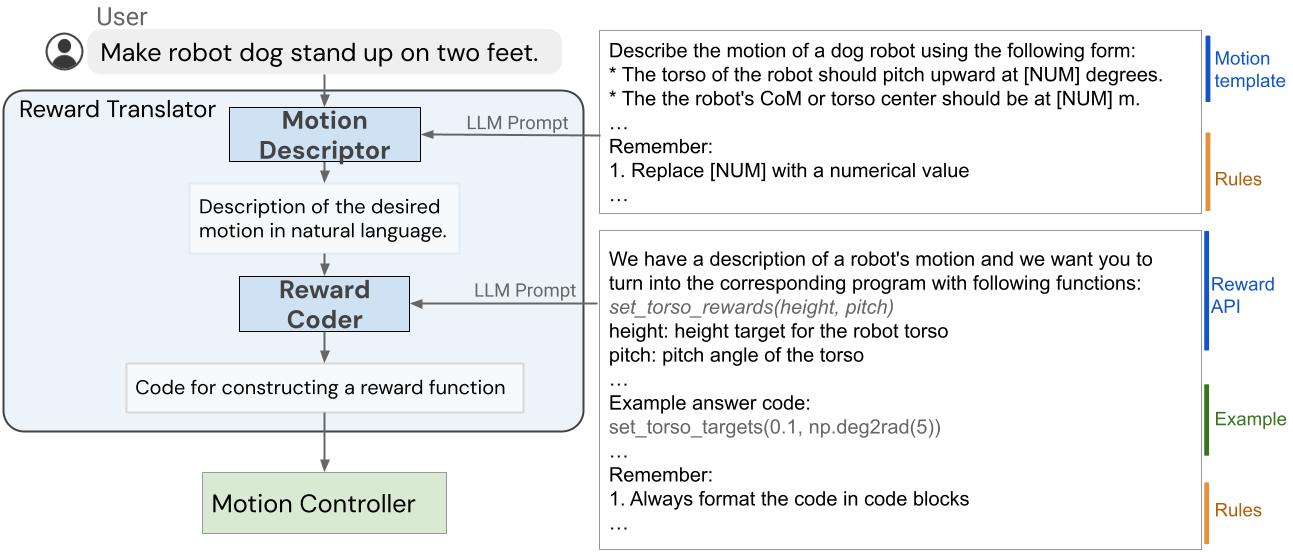 |
| ユーザーの入力をリワード関数にマッピングするリワードトランスレータの内部構造。 |
モーションコントローラー:報酬関数をロボットの動作に変換する
モーションコントローラーは、リワードトランスレータによって生成された報酬関数を受け取り、ロボットの観測値を低レベルのロボットの動作にマッピングします。 これを行うために、コントローラー合成問題をマルコフ決定過程(MDP)として定式化し、RL、オフライン軌道最適化、またはモデル予測制御(MPC)などの異なる戦略を使用して解決することができます。 具体的には、MuJoCo MPC(MJPC)に基づくオープンソースの実装を使用しています。
MJPCは、足の動作、掴む、指を使った動作など、さまざまな動作の対話的な作成を実証しており、繰り返し線形二次ガウス(iLQG)や予測サンプリングなど、さまざまな計画アルゴリズムをサポートしています。 さらに重要なのは、MJPCの頻繁な再計画がシステムの不確実性に対する堅牢性を向上させ、LLMと組み合わせることで対話的なモーション合成と修正システムを実現することです。
例
ロボット犬
最初の例では、言語からリワードシステムをシミュレートされた四足ロボットに適用し、さまざまなスキルを実行するように教えます。 各スキルについて、ユーザーはシステムに簡潔な指示を提供し、それが中間インタフェースとしてリワード関数を使用してロボットの動作を合成します。
巧みなマニピュレータ
次に、言語からリワードシステムを巧みなマニピュレータロボットに適用し、さまざまな操作タスクを実行します。 巧みなマニピュレータは27自由度を持ち、非常に制御が難しいです。 これらのタスクの多くは、グラスピングを超えた操作スキルを必要とし、事前に設計されたプリミティブが機能しづらいため、困難です。 ユーザーはロボットに対してリンゴを引き出しに入れるように指示する例も含まれています。
実際のロボットでの検証
また、実世界の操作ロボットを使用して、オブジェクトの取り上げや引き出しの開閉などのタスクを実行するために、言語からリワードメソッドの検証も行っています。 モーションコントローラーでの最適化を行うために、フィデューシャルマーカーシステムであるAprilTagと、オープンボキャブラリーのオブジェクト検出ツールであるF-VLMを使用して、テーブルと操作対象の位置を特定します。
結論
この論文では、低レベルモデル予測制御ツールであるMuJoCo MPCによって駆動される報酬関数を介してLLM(低水準モデル)とロボットのインターフェースを記述する新しいパラダイムを提案しています。インターフェースとして報酬関数を使用することで、LLMが強みを発揮する意味豊かな空間で作業できる一方、結果として得られるコントローラの表現力を確保します。さらに、システムの性能を向上させるために、LLMからロボットの動作に関する内部知識をより良く抽出するための構造化されたモーション記述テンプレートの使用を提案しています。我々は、シミュレートされた2つのロボットプラットフォームと実際のロボットによる両方の移動と操作のタスクで、提案されたシステムをデモンストレーションしています。
謝辞
このプロジェクトのさまざまな側面での支援と協力に感謝するため、共著者のNimrod Gileadi、Chuyuan Fu、Sean Kirmani、Kuang-Huei Lee、Montse Gonzalez Arenas、Hao-Tien Lewis Chiang、Tom Erez、Leonard Hasenclever、Brian Ichter、Ted Xiao、Peng Xu、Andy Zeng、Tingnan Zhang、Nicolas Heess、Dorsa Sadigh、Jie Tan、およびYuval Tassaに感謝します。また、Ken Caluwaerts、Kristian Hartikainen、Steven Bohez、Carolina Parada、Marc Toussaint、およびGoogle DeepMindのチームにもフィードバックと貢献を感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles