自然言語処理のタクソノミー
自然言語処理のタクソノミー' (Taxonomy of Natural Language Processing)
自然言語処理の異なる研究分野と最近の発展の概要

この記事は、私たちのRANLP 2023論文「自然言語処理研究の現状の探索」に基づいています。詳細はそちらで読むことができます。
はじめに
自然言語処理(NLP)の研究は、自然言語テキストを理解し、生成し、処理するための効率的な手法として、近年急速に広まり、広く採用されています。NLPの急速な発展により、この領域の概要を把握し続けることは困難です。このブログ記事は、NLPの異なる研究分野の概要を提供し、この領域の最近のトレンドを分析することを目的としています。
研究分野とは、通常、タスクや技術から構成される学問的な学問分野や概念です(限定されることはありません)。
この記事では、以下の質問を調査します:
- スタンフォード大学の研究は、PointOdysseyを紹介します:長期ポイント追跡のための大規模な合成データセット
- 「解答付きの無料データサイエンスプロジェクト5つ」
- 自己学習のためのデータサイエンスカリキュラム
- NLPで調査される異なる研究分野は何ですか?
- NLPの研究文献の特徴と時間の経過における発展はどのようなものですか?
- NLPの現在のトレンドと将来の研究の方向性は何ですか?
NLPのほとんどの研究分野はよく知られており、定義されていますが、一貫性のある理解可能な形式でこれらの研究分野を収集し構造化しようとする、一般的に使用されるタクソノミーや分類スキームは現在存在しません。したがって、NLP研究全体の概要を把握することは困難です。NLPのトピックのリストは、学会や教科書に存在しますが、かなり異なる傾向があり、広範かつ特化しすぎていることが多いです。そのため、私たちはNLPの広範な研究分野を包括するタクソノミーを開発しました。このタクソノミーにはすべての可能なNLPの概念が含まれているわけではありませんが、最も人気のある研究分野の幅広い範囲をカバーしており、欠けている研究分野は含まれている研究分野のサブトピックとして考えることができます。タクソノミーを開発する過程で、特定の下位レベルの研究分野を単一の上位レベルの研究分野に割り当てるのではなく、複数の上位レベルの研究分野に割り当てる必要があることがわかりました。そのため、NLPのタクソノミーには、同じ研究分野が複数回リストされていますが、異なる上位レベルの研究分野に割り当てられています。最終的なタクソノミーは、ドメインの専門家との反復的なプロセスで経験的に開発されました。
タクソノミーは、NLPの論文を含まれる研究分野の少なくとも1つに分類するための包括的な分類スキームとして機能し、それらが直接的に研究分野の1つを対象としていなくても、サブトピックに関するものである場合でも分類することができます。NLPの最近の展開を分析するために、弱教師ありモデルを訓練してNLPのタクソノミーに基づいてACL Anthologyの論文を分類しました。
分類モデルとNLPのタクソノミーの開発プロセスの詳細については、私たちの論文をご覧ください。
NLPの異なる研究分野 📖
以下のセクションでは、NLPのタクソノミーに含まれる研究分野の概要を短く説明します。
マルチモダリティ
「マルチモダリティは、異なるタイプやモダリティの入力を処理するシステムや方法の能力を指します」(Garg et al., 2022)。我々は、自然言語のテキストと視覚データ、音声とオーディオ、プログラミング言語、または表やグラフのような構造化データを処理できるシステムを区別しています。
自然言語インターフェース
「自然言語インターフェースは、自然言語クエリに基づいてデータを処理することができます」(Voigt et al., 2021)。通常は質問応答や対話型システムとして実装されます。
意味処理
この高レベルの研究分野は、自然言語から意味を抽出し、機械がテキストデータを意味的に解釈できるようにするためのあらゆる種類の概念を含みます。この分野で最も強力な研究分野の1つは、「単語のシーケンスの結合確率関数を学習しようとする言語モデル」です(Bengio et al., 2000)。言語モデルのトレーニングの最近の進展により、これらのモデルはさまざまな下流のNLPタスクを成功裏に実行することができるようになりました(Soni et al., 2022)。表現学習では、「意味的なテキスト表現は埋め込みの形式で学習されることが通常です」(Fu et al., 2022)、これらの埋め込みは「意味的な検索の設定でテキストの意味的な類似性を比較するために使用することができます」(Reimers and Gurevych, 2019)。さらに、「知識表現、例えば知識グラフの形式で、さまざまなNLPタスクの改善に組み込むことができます」(Schneider et al., 2022)。
感情分析
「感情分析は、テキストから主観的な情報を特定・抽出しようとする試みです」(Wankhade et al.、2022)。通常、研究ではテキストから意見、感情、または極性を抽出することに焦点を当てています。近年では、アスペクトベースの感情分析が一般的な感情分析よりも詳細な情報を提供する方法として登場しました。「これは、テキスト内の与えられたアスペクトまたはエンティティの感情極性を予測することを目指しています」(Xue and Li、2018)。
構文テキスト処理
この高度な研究分野は、「テキストの文法的な構文と語彙を分析する」ことを目指しています(Bessmertny et al.、2016)。この文脈での代表的なタスクには、文の単語の依存関係の構文解析、単語の品詞タグ付け、テキストの区切り、文法とスペルに関する間違ったテキストの修正などがあります。
言語学と認知NLP
「言語学と認知NLPは、言語能力が認知能力にしっかりと根ざしているという前提に基づいて自然言語に取り組み、意味は基本的に概念化であり、文法は使用法によって形成されるという仮定に基づいています」(Dabrowska and Divjak、2015)。一般的には、「言語習得は、すべての通常発達する人間に共通の普遍的な文法ルールによって支配される」と主張するさまざまな言語学的理論が存在しています(Wise and Sevcik、2017)。また、「心理言語学は、人間の脳が言語を習得し、生成し、処理し、理解し、フィードバックを提供する方法をモデル化しようとします」(Balamurugan、2018)。さらに、「認知モデリングは、さまざまな形式で人間の認知プロセスをモデル化し、シミュレーションすることに関心があります、特に計算的または数学的な形式で」(Sun、2020)。
責任ある信頼性の高いNLP
「責任ある信頼性の高いNLPは、公正さ、説明可能性、責任、および倫理的な側面に焦点を当てた方法の実装に関心を持っています」(Barredo Arrieta et al.、2020)。環境に配慮したNLPは主にテキスト処理の効率的なアプローチに焦点を当てていますが、低リソースNLPはデータが不足している場合にNLPタスクを実行することを目指しています。さらに、NLPの堅牢性は、バイアスに対して無感受性であり、データの摂動に対して抵抗力があり、分布外予測に信頼性のあるモデルを開発しようとします。
推論
推論によって、機械は利用可能な情報を基に論理的な結論を導き、新しい知識を得ることができます。推論と帰納法などの技術を使用して、「議論の抽出は、自然言語テキストで提示される推論と推論の構造を自動的に識別・抽出します」(Lawrence and Reed、2019)。テキストの推論は通常、帰結問題としてモデル化され、与えられた前提から自然言語の仮説が推論できるかどうかを自動的に判断します(MacCartney and Manning、2007)。また、「常識的な推論は、テキストに明示的に提供されていない世界の知識を使用して前提と仮説を結びつけます」(Ponti et al.、2020)、「数値的な推論は算術演算を実行します」(Al-Negheimish et al.、2021)。また、「機械読解は、与えられた文章に基づいて質問の正しい答えを機械に教えることを目指します」(Zhang et al.、2021)。
多言語対応
多言語対応は、1つ以上の自然言語を含むすべてのタイプのNLPタスクに取り組み、通常は機械翻訳で研究されています。さらに、「コードスイッチングは、1つの文または文の間で複数の言語を自由に交換します」(Diwan et al.、2021)、跨言語転送技術は、別の言語でNLPタスクを解決するために利用可能なデータとモデルを使用します。
情報検索
「情報検索は、大規模なコレクション内から情報ニーズに合致するテキストを見つけることに関心があります」(Manning et al.、2008)。通常、これにはドキュメントまたはパッセージの検索が含まれます。
情報抽出とテキストマイニング
この研究分野では、非構造化テキストから構造化された知識を抽出することに焦点を当てており、「データ内のパターンや相関関係を分析および特定することを可能にする」(Hassani et al.、2020)とされています。「テキスト分類は、テキストを事前に定義されたクラスに自動的に分類します」(Schopf et al.、2021)、一方、「トピックモデリングはドキュメントコレクション内の潜在的なトピックを発見することを目指します」(Grootendorst、2022)、しばしば テキストクラスタリング技術を使用して意味的に類似したテキストを同じクラスタにまとめます。「要約は、入力のキーポイントを含むテキストの要約を短いスペースに生成し、繰り返しを最小限に抑えます」(El-Kassas et al.、2021)。さらに、情報抽出とテキストマイニングの研究分野には、「固有表現認識(named entity recognition)は、固有名詞の識別と分類に関連します」(Leitner et al.、2020)、または「共参照解決(coreference resolution)は、談話内で同じエンティティへのすべての参照を特定することを目指します」(Yin et al.、2021)、または「用語抽出(term extraction)は、キーワードやキーフレーズなどの関連する用語を抽出することを目指します」(Rigouts Terryn et al.、2020)、そしてエンティティ間の関係を抽出することを目指した関係抽出、さらには「オープン情報抽出は、ドメインに依存しない関係のタプルの発見を容易にします」(Yates et al.、2007)。
テキスト生成
テキスト生成アプローチの目的は、人間に理解可能であり、人間が作成したテキストと区別できないテキストを生成することです。そのため、入力は通常、テキストなどのテキストで構成されます。「言い換えは、意味を保持しながらテキスト入力を異なる表面形式で表現します」(Niu et al.、2021)、または「質問生成は、パッセージと目標回答が与えられた場合に流暢で関連性のある質問を生成することを目指します」(Song et al.、2018)、または「対話応答生成は、プロンプトに関連する自然なテキストを生成することを目指します」(Zhang et al.、2020)。ただし、多くの場合、テキストは他のモダリティからの入力によって生成されます。たとえば、「データからテキスト生成は、テーブルやグラフなどの構造化データに基づいてテキストを生成します」(Kale and Rastogi、2020)、画像や動画のキャプション付け、または「音声認識は音声波形をテキストに変換します」(Baevski et al.、2022)。
自然言語処理の特徴と進展 📈
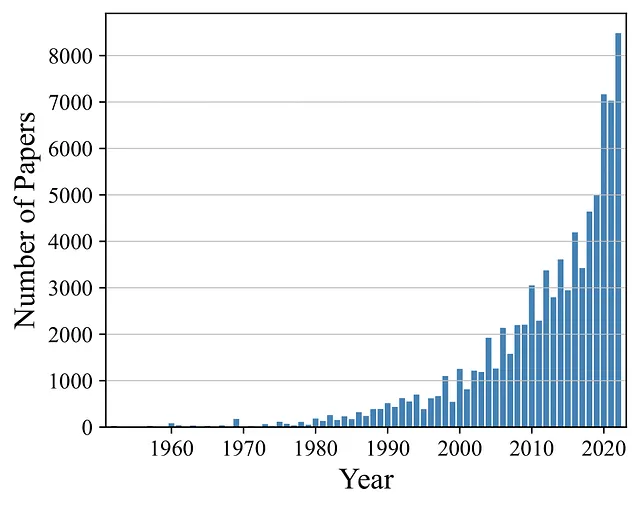
NLPに関する文献を考慮すると、研究の関心を示す指標として研究数から分析を開始します。上記の図には、50年間の観察期間にわたる出版物の分布が示されています。最初の出版物は1952年に現れましたが、年間の出版物数は2000年までゆっくりと増加しました。それに応じて、2000年から2017年の間に出版物の数はおおよそ4倍に増加し、その後の5年間で再び倍増しました。したがって、NLPの研究数はほぼ指数関数的に成長しており、研究コミュニティからの関心が高まっていることを示しています。

上記の図を見ると、NLP文献で最も人気のある研究分野とそれらの最近の発展が明らかになります。NLPの研究の大多数は機械翻訳や言語モデルに関連していますが、これらの研究分野の発展は異なっています。機械翻訳は長い間研究されてきた分野であり、過去20年間で控えめな成長率を経験しています。言語モデルも長い間研究されてきましたが、このトピックに関する論文の数は2018年以降急激に増加しています。他の人気のある研究分野を見ると、表現学習やテキスト分類は一般的に広く研究されていますが、成長が停滞しています。一方、対話システム&会話エージェントや特に低リソースのNLPは、研究の数において高い成長率を示し続けています。他の研究分野の平均的な研究数の発展を考慮すると、全体的にわずかな正の成長が見られます。ただし、最も人気のある研究分野よりも他の研究分野の方が著しく研究されていないことが大多数です。
NLPの最近のトレンド 🚀
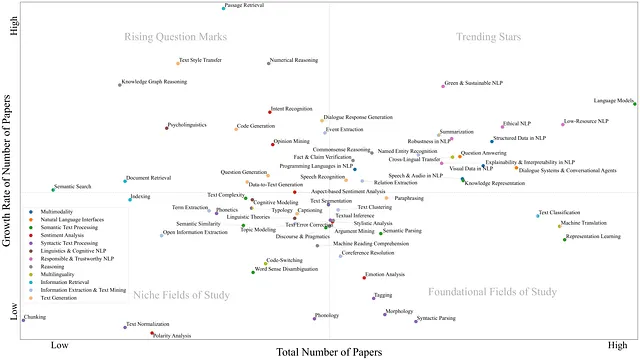
上記の図は、NLPの研究分野の成長シェア行列を示しています。この行列を使用して、2018年から2022年までの間にNLPのさまざまな研究分野に関連する論文の成長率と総数を分析することで、現在の研究トレンドと可能な将来の研究方向を検討します。行列の右上セクションには、成長率が高く、同時に総論文数も多い研究分野があります。このセクションの研究分野の人気の高まりを考慮して、それらをトレンドの星として分類します。行列の右下セクションには、非常に人気のある研究分野がありますが、成長率が低いです。通常、これらはNLPにとって重要な研究分野ですが、すでに比較的成熟しています。そのため、これらを基礎的な研究分野として分類します。行列の左上セクションには、成長率が高いが総論文数が非常に少ない研究分野があります。これらの研究分野の進展は非常に有望ですが、全体的な論文数が少ないため、さらなる発展を予測するのは困難です。そのため、これらを上昇中の疑問符として分類します。行列の左下にある研究分野は、総論文数が少なく成長率も低いため、ニッチな研究分野として分類されます。
図からは、現在、言語モデルに最も注目が集まっていることがわかります。この分野の最新の発展に基づいて、このトレンドは今後も続き、加速する可能性があります。テキスト分類、機械翻訳、表現学習は最も人気のある研究分野の一部ですが、成長はわずかです。長期的には、より成長が速い研究分野によって最も人気のある研究分野が置き換えられる可能性があります。
一般的に、構文的なテキスト処理に関連する研究分野はほとんど成長せず、人気も低いです。一方、緑のNLPや持続可能なNLP、低リソースのNLP、倫理的なNLPなど、責任ある信頼性のあるNLPに関連する研究分野は、高い成長率と人気を示す傾向があります。これは、NLPにおける構造化データ、視覚データ、音声データなど、多様性に関連する研究分野でも観察されます。さらに、対話システム&会話エージェントや質問応答を含む自然言語インターフェースは、研究コミュニティでますます重要になっています。言語モデルに加えて、責任ある信頼性のあるNLP、多様性、自然言語インターフェースが、近い将来のNLPの研究領域を特徴付けると結論付けられます。
推論に関する領域では、知識グラフ推論や数値推論に関して特筆すべき発展が見られます。これらの研究分野は現在は比較的小さな分野ですが、研究コミュニティからますます関心を集め、明確な成長傾向を示しています。
結論 💡
最近の動向をまとめ、NLPの現状を概観するために、研究分野のタクソノミーを定義し、最近の研究動向を分析しました。
私たちの調査結果によれば、多様な分野が研究されており、これにはマルチモーダリティ、責任ある信頼性のある自然言語処理(NLP)、自然言語インターフェースなどのトレンド分野も含まれています。この記事が現在のNLPの状況の有益な概要を提供し、さらに深く探求するための出発点となることを願っています。
参考文献
自然言語処理研究の探索
自然言語テキストの理解、生成、処理を効率的に行う手法として、自然言語処理の研究があります…
arxiv.org
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
