大規模な言語モデルを使用した自律型の視覚情報検索
自律的な視覚情報検索には大規模な言語モデルを使用する
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team
大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。
 |
| 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 |
「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。
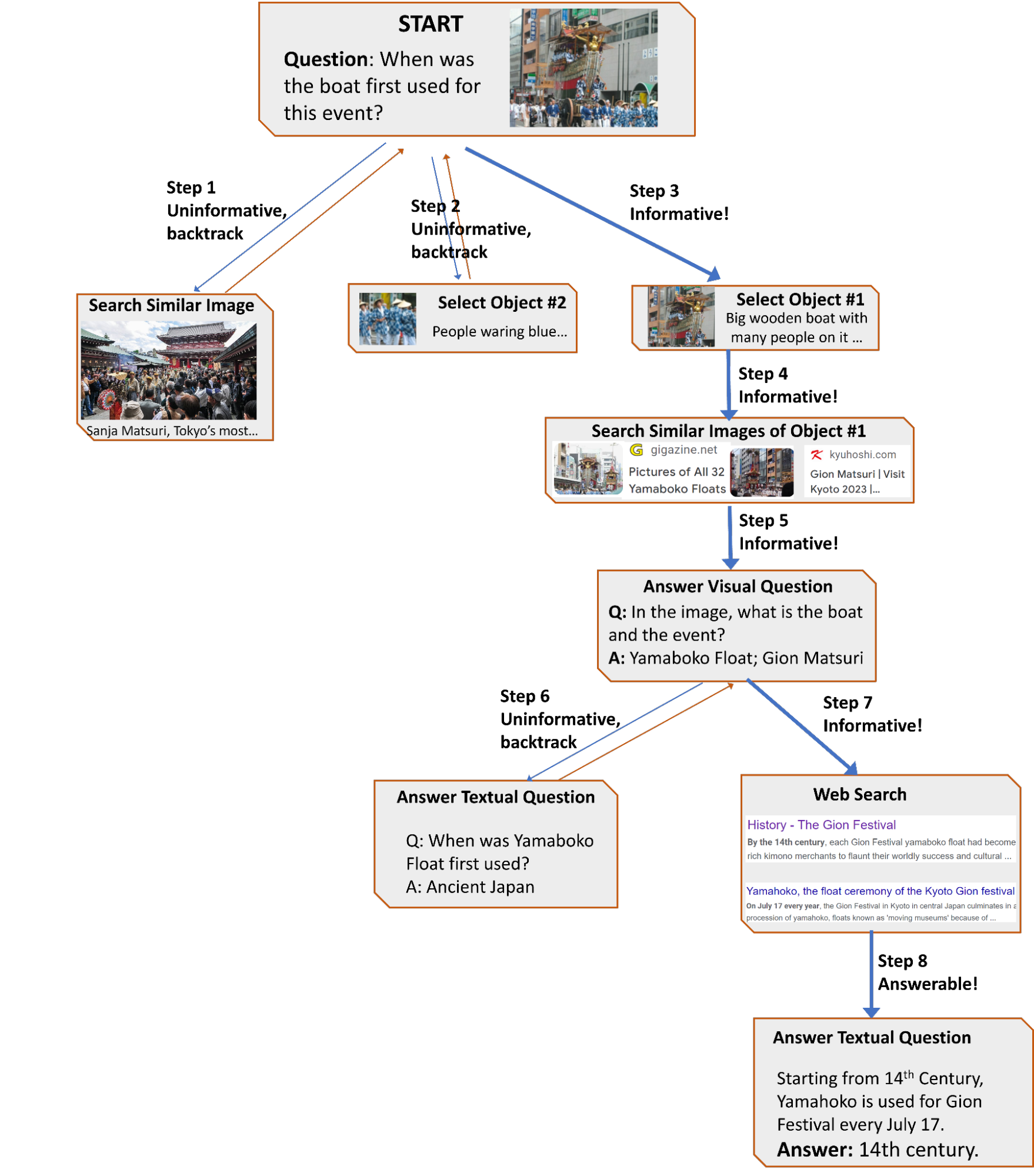 |
| 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 |
以前の研究との比較
最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。
- 「Lineが『japanese-large-lm』をオープンソース化:36億パラメータを持つ日本語言語モデル」
- この中国のAI論文では、「物理的なシーンの制約を持つ具体的な計画におけるタスクプランニングエージェント(TaPA)」が提案されています
- Google AIによるコンテキストの力を解き放つ:プレフィックスLMと因果LMの対決におけるインコンテキスト学習
また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。
ユーザースタディによるLLMの意思決定への情報提供
InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。
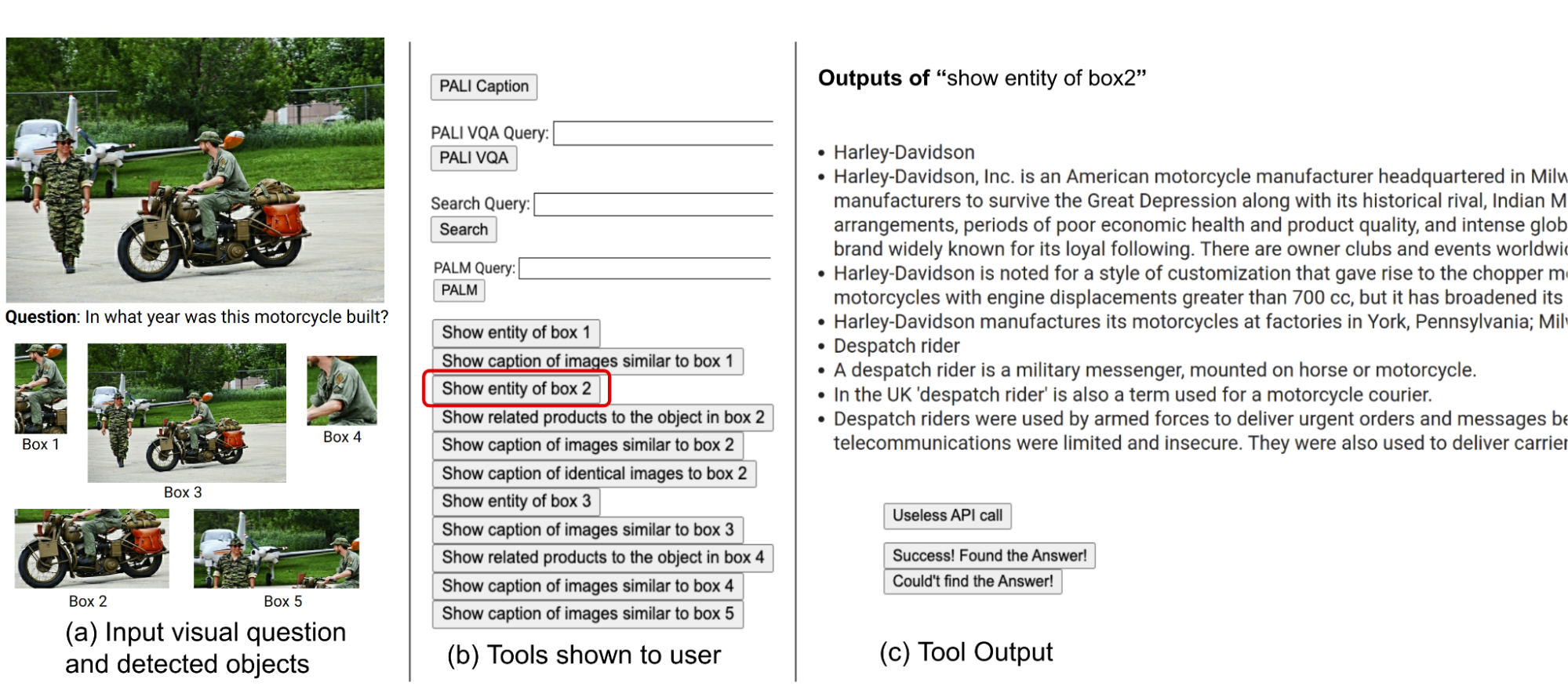 |
| 外部ツールを使用する際の人間の意思決定を理解するためのユーザースタディを実施しました。画像はOK-VQAデータセットから取得されています。 |
ユーザーは、PALI、PaLM、ウェブ検索を含む私たちの手法と同じセットのツールを装備しています。入力画像、質問、検出されたオブジェクトのクロップ、および画像検索結果にリンクされたボタンがユーザーに提供されます。これらのボタンには、知識グラフエンティティ、類似画像のキャプション、関連する商品タイトル、および同じ画像のキャプションなど、検出されたオブジェクトのクロップに関するさまざまな情報が含まれています。
私たちはユーザーのアクションと出力を記録し、システムのガイドとして2つのキーな方法で使用しています。まず、ユーザーが行った意思決定のシーケンスを分析して、遷移グラフ(以下に示す)を構築します。このグラフは異なる状態を定義し、各状態で利用可能なアクションのセットを制限します。たとえば、開始状態では、システムはPALIキャプション、PALI VQA、またはオブジェクト検出のいずれかのアクションを選択できます。次に、人間の意思決定の例を使用して、私たちのプランナーとリーズナーをガイドし、関連する文脈のインスタンスを使用してシステムのパフォーマンスと効果を向上させます。
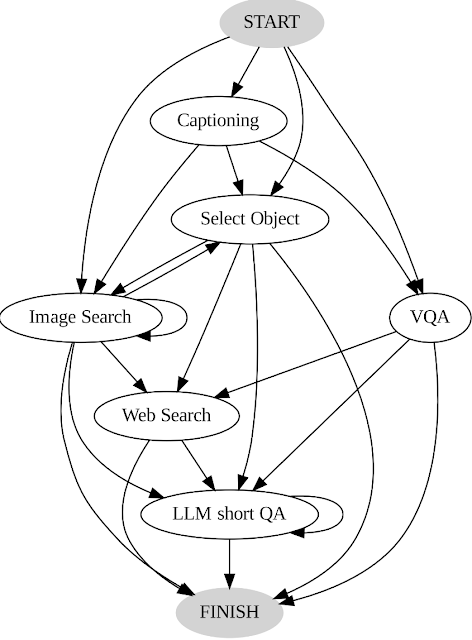 |
| AVIS遷移グラフ。 |
一般的なフレームワーク
私たちのアプローチは、視覚情報検索クエリに対応するように設計された動的意思決定戦略を採用しています。私たちのシステムには3つの主要なコンポーネントがあります。まず第一に、プランナーが次のアクションを決定し、それに必要なAPI呼び出しと処理するクエリを決定します。第二に、APIの実行結果に関する情報を保持するワーキングメモリがあります。最後に、リーズナーがAPI呼び出しの出力を処理します。これにより、得られた情報が最終的な応答を生成するのに十分かどうか、または追加のデータの取得が必要かどうかを決定します。
プランナーは、どのツールを使用し、どのクエリを送信するかに関して、意思決定が必要な場合に毎回一連のステップを実行します。現在の状態に基づいて、プランナーは潜在的な次のアクションの範囲を提供します。潜在的なアクションスペースは非常に大きいため、検索空間が扱いにくくなる場合があります。この問題に対処するため、プランナーは遷移グラフを参照して関係のないアクションを除外します。また、ワーキングメモリにすでに実行されたアクションを除外します。
次に、プランナーはユーザースタディ中に人間が以前に行った意思決定から抽出される関連するコンテキストの例を収集します。これらの例と、過去のツールの相互作用から収集されたデータを保持するワーキングメモリを使用して、プランナーはプロンプトを作成します。プロンプトはLLMに送信され、構造化された回答を返します。これにより、次にアクティブ化されるツールとそれに送信されるクエリが決定されます。この設計により、プランナーはプロセス全体で複数回呼び出されるため、入力クエリに回答するまで徐々に進行する動的な意思決定が容易になります。
私たちはリーズナーを使用して、ツールの実行結果を分析し、有用な情報を抽出し、ツールの出力が情報提供、非情報提供、または最終回答のどのカテゴリに該当するかを決定します。私たちの手法は、適切なプロンプトと関連するコンテキストの例を使用してLLMを活用して推論を行います。リーズナーが回答を提供する準備ができていると判断した場合、最終的な応答を出力し、タスクを終了します。ツールの出力が非情報提供であると判断された場合、プランナーに戻って現在の状態に基づいて別のアクションを選択します。ツールの出力が有用であると判断された場合、状態を変更し、制御をプランナーに戻して新しい状態で新しい意思決定を行います。
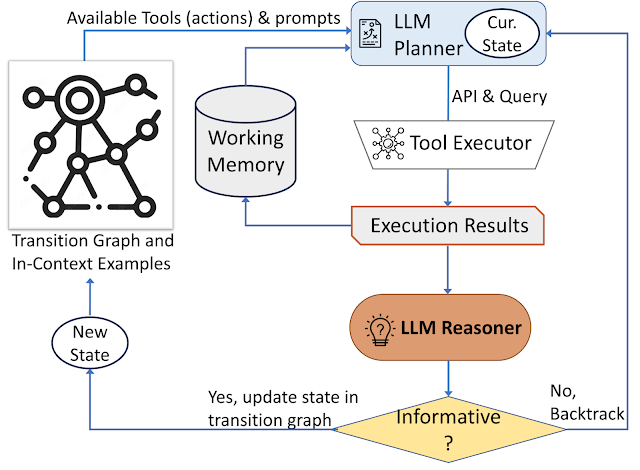 |
| AVISは、視覚情報検索クエリに対応するための動的な意思決定戦略を採用しています。 |
結果
InfoseekおよびOK-VQAデータセットでAVISを評価します。以下に示すように、OFAやPaLIなどの堅牢な視覚言語モデルでも、Infoseekで微調整しても高い精度が得られないことがあります。当社のアプローチ(AVIS)は、微調整せずにこのデータセットの未知のエンティティ分割で50.7%の精度を達成しています。
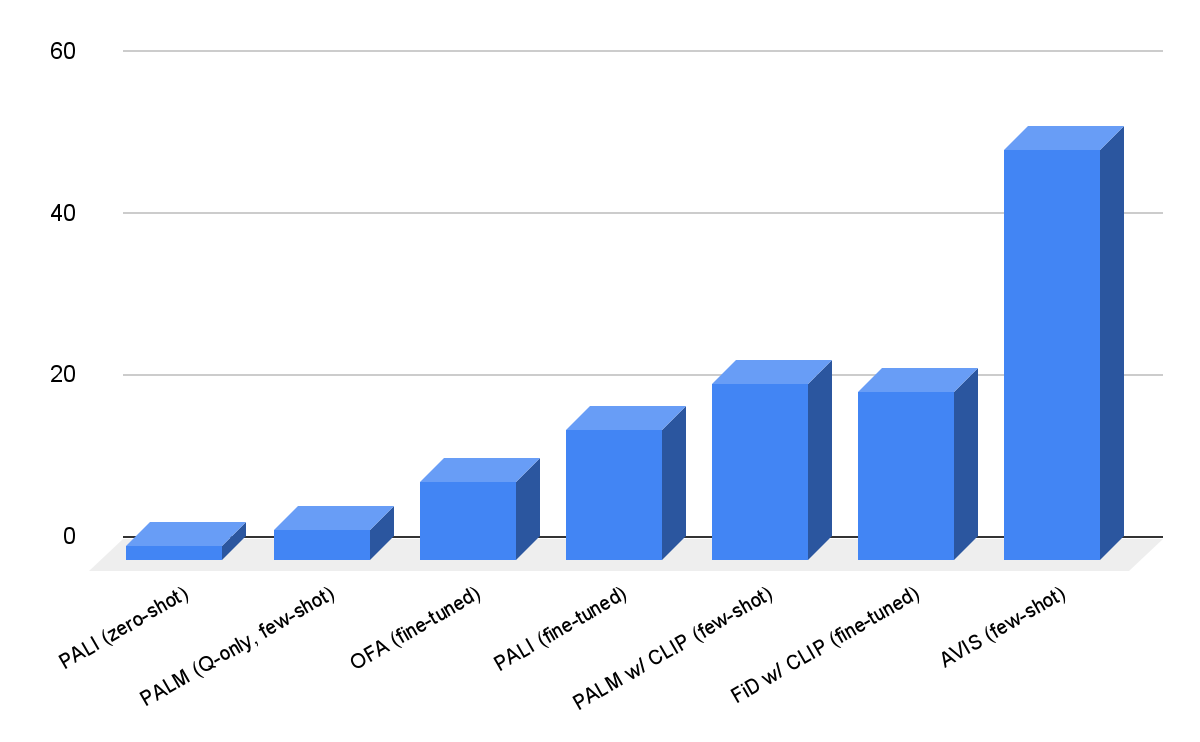 |
| InfoseekデータセットにおけるAVISの視覚質問応答の結果。AVISは、PaLI、PaLM、OFAに基づく以前のベースラインと比較して、より高い精度を達成しています。 |
OK-VQAデータセットの結果は以下の通りです。少数のコンテキスト例を使用したAVISは、60.2%の精度を達成し、以前の多くの研究よりも高い精度を実現しています。AVISは、OK-VQAで微調整されたPALIと比較して精度は低いですが、ほぼ同等です。これは、OK-VQAのほとんどの質問応答例が細かい知識ではなく常識的な知識に依存しているためです。したがって、PaLIはモデルパラメータに一般的な知識をエンコードすることができ、外部の知識は必要ありません。
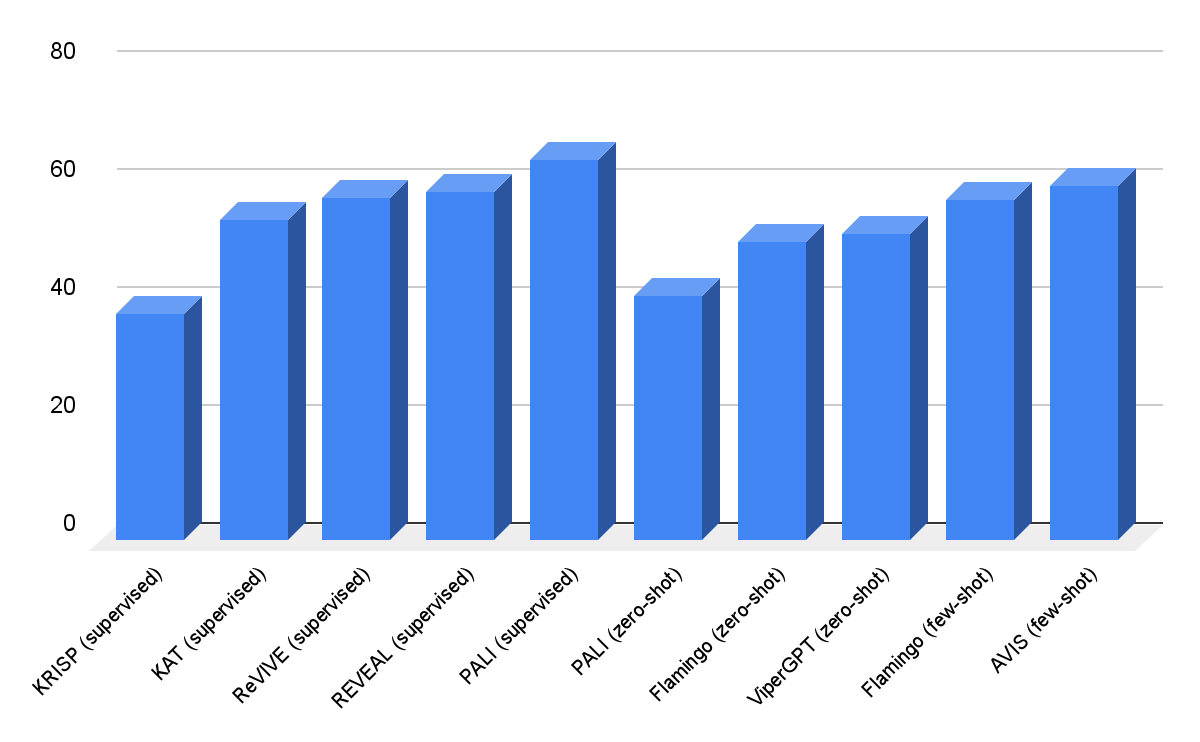 |
| A-OKVQAの視覚質問応答の結果。AVISは、Flamingo、PaLI、ViperGPTなど、少数またはゼロショット学習を使用する以前の研究と比較して、より高い精度を実現しています。AVISは、OK-VQAデータセットで微調整された以前の研究(REVEAL、ReVIVE、KAT、KRISPなど)よりも高い精度を実現し、微調整されたPaLIモデルに近い結果を実現しています。 |
結論
私たちは、知識集約型の視覚的な質問に対する様々なツールの使用能力を備えたLLM(Language and Vision Models)の新しいアプローチを提案します。ユーザースタディから収集された人間の意思決定データに基づく当社の手法は、LLMを動力とするプランナーを使用してツールの選択とクエリの形成を動的に決定する構造化されたフレームワークを採用しています。LLMを動力とする推論エンジンは、選択されたツールの出力から重要な情報を処理して抽出する役割を担っています。当社の手法は、必要な情報が質問に答えるために集められるまで、プランナーと推論エンジンを反復的に利用します。
謝辞
この研究は、Ziniu Hu、Ahmet Iscen、Chen Sun、Kai-Wei Chang、Yizhou Sun、David A. Ross、Cordelia Schmid、Alireza Fathiによって実施されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





