完全に自動化されたデータドリフト検出パイプラインの構築方法
自動化されたデータドリフト検出パイプラインの構築方法
データドリフトを検出し対処するための自動化ガイド

動機
データドリフトは、本番環境における入力特徴量の分布が学習データと異なる場合に発生し、精度の低下やモデルパフォーマンスの低下を引き起こすことがあります。
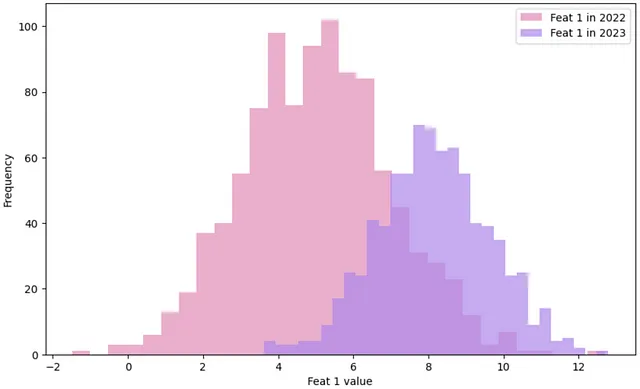
データドリフトの影響を軽減するために、ドリフトを検出し、データチームに通知し、モデルの再学習をトリガーするワークフローを設計することができます。
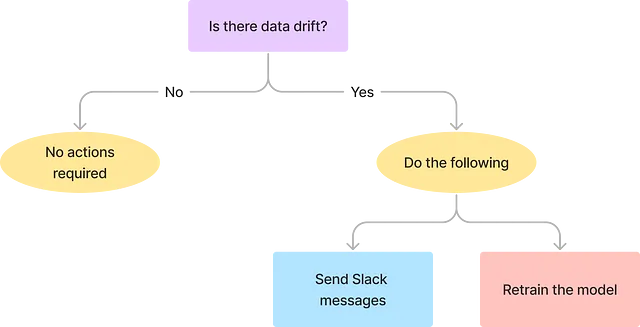
ワークフロー
このワークフローには、以下のタスクが含まれます:
- Postgresデータベースから参照データを取得する。
- ウェブから現在の本番データを取得する。
- 参照データと現在のデータを比較してデータドリフトを検出する。
- 現在のデータを既存のPostgresデータベースに追加する。
- データドリフトがある場合、以下のアクションを実行する:
- データチームにSlackメッセージを送信して通知する。
- モデルのパフォーマンスを更新するためにモデルを再学習する。
- 更新されたモデルをS3に保存する。
このワークフローは、毎週月曜日の午前11時など、特定の時間に実行されるようにスケジュールされています。
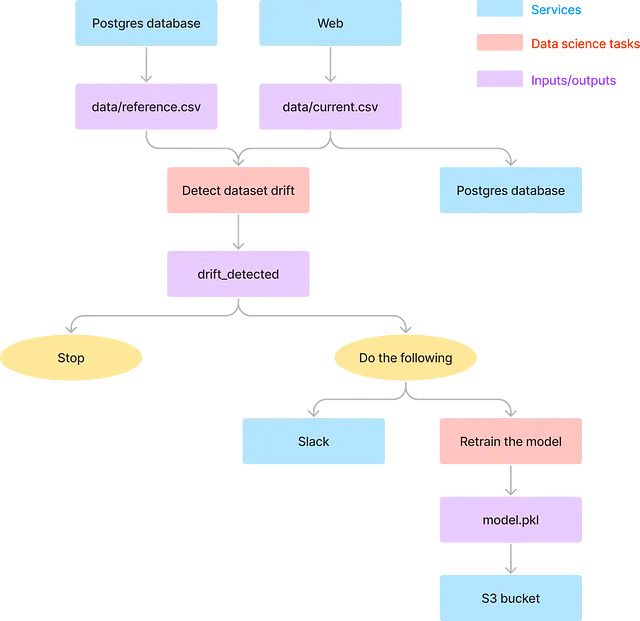
全体的に、このワークフローにはデータサイエンスタスクとデータエンジニアリングタスクの2つのタイプのタスクが含まれています。
データサイエンスタスクはピンクのボックスで表され、データサイエンティストによって実行され、データドリフトに関与します…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
