組合せ最適化によるニューラルネットワークの剪定
組合せ最適化によるニューラルネットワークの剪定
Posted by Hussein Hazimeh、Athenaチームの研究科学者、およびMITの大学院生であるRiade Benbakiによる投稿
近代的なニューラルネットワークは、言語、数学的推論、ビジョンなど、さまざまなアプリケーションで印象的なパフォーマンスを達成しています。しかし、これらのネットワークはしばしば大規模なアーキテクチャを使用し、多くの計算リソースを必要とします。これにより、特にウェアラブルやスマートフォンなどのリソース制約のある環境では、このようなモデルをユーザーに提供することが実用的ではありません。事前学習済みネットワークの推論コストを軽減するための広く使用されている手法は、いくつかの重みを削除することによる枝刈りですが、これはネットワークの有用性にほとんど影響を与えない方法で行われます。標準的なニューラルネットワークでは、各重みは2つのニューロン間の接続を定義します。したがって、重みが剪定された後、入力はより小さな一連の接続を介して伝播し、より少ない計算リソースを必要とします。
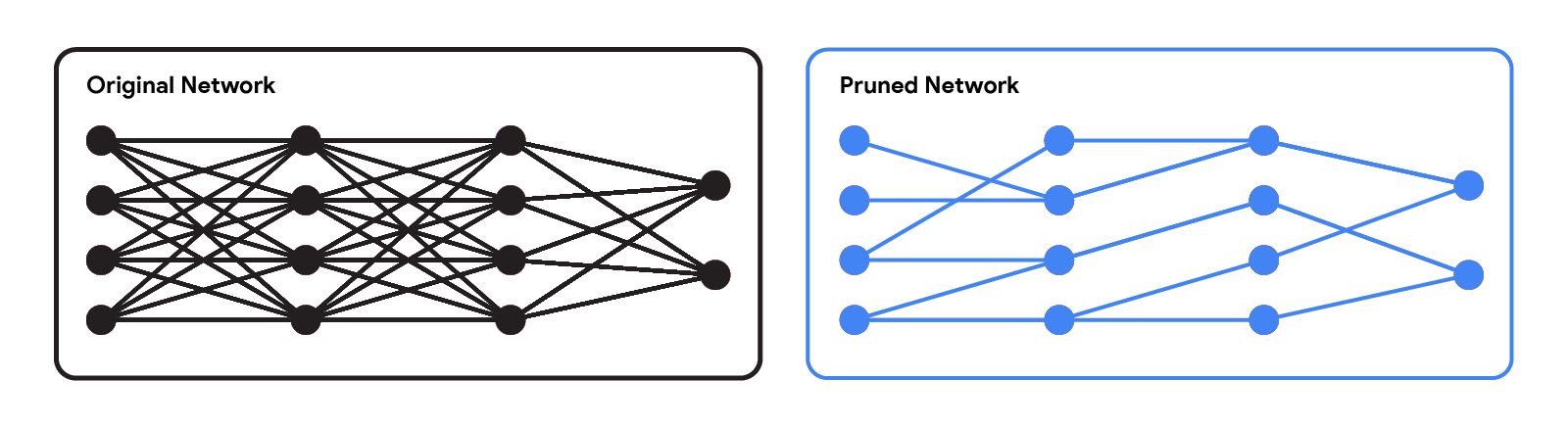 |
| 元のネットワークと剪定されたネットワークの比較。 |
枝刈り手法は、ネットワークのトレーニングプロセスのさまざまな段階で適用できます。トレーニング後、トレーニング中、またはトレーニング前(つまり、重みの初期化直後)に適用できます。この投稿では、トレーニング後の設定に焦点を当てています。つまり、事前学習済みネットワークが与えられた場合、どの重みを剪定すべきかをどのように決定できるかという問題です。最も一般的な手法の1つは、マグニチュード剪定です。この手法では、最も小さい絶対値を持つ重みを削除します。効率的ではありますが、この手法は重みの削除がネットワークのパフォーマンスに与える影響を直接考慮しません。もう1つの一般的な手法は、最小化された損失関数に対する重みの影響度に基づいて重みを削除する最適化ベースの剪定です。概念的には魅力的ですが、既存の最適化ベースの手法の多くは、パフォーマンスと計算要件の間に深刻なトレードオフがあるようです。粗い近似を行う手法(例:対角ヘッシアン行列を仮定する)はスケーラブル性が高く、パフォーマンスは比較的低いです。一方、より少ない近似を行う手法はパフォーマンスが向上する傾向がありますが、スケーラブル性ははるかに低いようです。
「Fast as CHITA: Neural Network Pruning with Combinatorial Optimization」は、ICML 2023で発表された論文で、事前学習済みニューラルネットワークの剪定において、スケーラビリティとパフォーマンスのトレードオフを考慮した最適化ベースのアプローチを開発した方法について説明しています。CHITA(「Combinatorial Hessian-free Iterative Thresholding Algorithm」の略)は、高次元統計、組合せ最適化、およびニューラルネットワークの剪定など、いくつかの分野の進歩を活用しています。たとえば、CHITAはResNetの剪定において最先端の手法よりも20倍から1000倍高速であり、多くの設定で精度を10%以上向上させることができます。
- 「ペンの向こう側:視覚的な原型からの手書きテキスト生成におけるAIの芸術性」
- 「トランスフォーマーの簡素化:理解できる単語を使った最先端の自然言語処理(NLP)-パート2- 入力」
- 「Declarai、FastAPI、およびStreamlitを使用してLLMチャットアプリケーションを展開する」
貢献の概要
CHITAには、人気のある手法に比べて2つの注目すべき技術的改善点があります:
- 2次情報の効率的な使用:2次情報(つまり、2次導関数に関連する情報)を使用する剪定手法は、多くの設定で最先端の結果を達成しています。文献では、この情報は通常、ヘッシアン行列またはその逆を計算することによって使用されますが、ヘッシアンのサイズは重みの数に対して二次的になるため、スケーリングが非常に困難です。CHITAは、ヘッシアン行列を明示的に計算または保存することなく、2次情報を使用するため、よりスケーラブルな処理が可能です。
- 組合せ最適化:人気のある最適化ベースの手法では、単独で重みを剪定する単純な最適化手法が使用されます。つまり、特定の重みを剪定する際に、他の重みが剪定されたかどうかを考慮しません。これにより、単独では重要でないと見なされる重みが、他の重みが剪定された場合に重要になる可能性があります。CHITAは、1つの重みを剪定することが他の重みにどのように影響するかを考慮するより高度な組合せ最適化アルゴリズムを使用することで、この問題を回避します。
以下のセクションでは、CHITAの剪定の定式化とアルゴリズムについて説明します。
計算に適した剪定の定式化
剪定候補は、元のネットワークから重みのサブセットのみを保持することで得られます。kをユーザー指定のパラメータとし、保持する重みの数を指定します。剪定は、最小の損失を持つ剪定候補(つまり、重みのサブセット)の中から、k個の重みのみを保持するものを選ぶ最適なサブセット選択(BSS)問題として自然に定式化されます。
 |
| 剪定をBSS問題として扱うと、重みの総数が同じである可能な剪定候補の中で、最小の損失を持つ候補が最適なものとされます。このイラストは4つの候補を示していますが、一般にこの数ははるかに大きくなります。 |
元の損失関数に対する剪定BSS問題の解決は、一般に計算的に困難です。そのため、OBDやOBSなどの以前の研究と同様に、2次テイラー展開を使用して二次関数で損失を近似し、ヘッシアンを経験フィッシャー情報行列で推定することで、問題を近似します。勾配は通常効率的に計算できますが、ヘッシアン行列の計算と保存は、そのサイズの巨大さゆえに非常に高価です。文献では、この課題に対処するために、ヘッシアン(例:対角行列)およびアルゴリズム(例:単独の重みの剪定)に制約を加えることが一般的です。
CHITAは、ヘッシアン行列を明示的に計算せずに、経験フィッシャー情報行列の低ランク構造を利用して、剪定問題(二次損失を使用したBSS)を効率的に再定式化します。この再定式化は、各回帰係数がニューラルネットワークの特定の重みに対応している、疎な線形回帰問題と見なすことができます。この回帰問題の解を得た後、ゼロに設定された係数は、剪定すべき重みに対応します。回帰データ行列は(n x p)であり、nはバッチ(サブサンプル)のサイズ、pは元のネットワークの重みの数です。通常、n << pであるため、このデータ行列の保存と操作は、(p x p)のヘッシアンを使用する一般的な剪定手法よりもはるかにスケーラブルです。
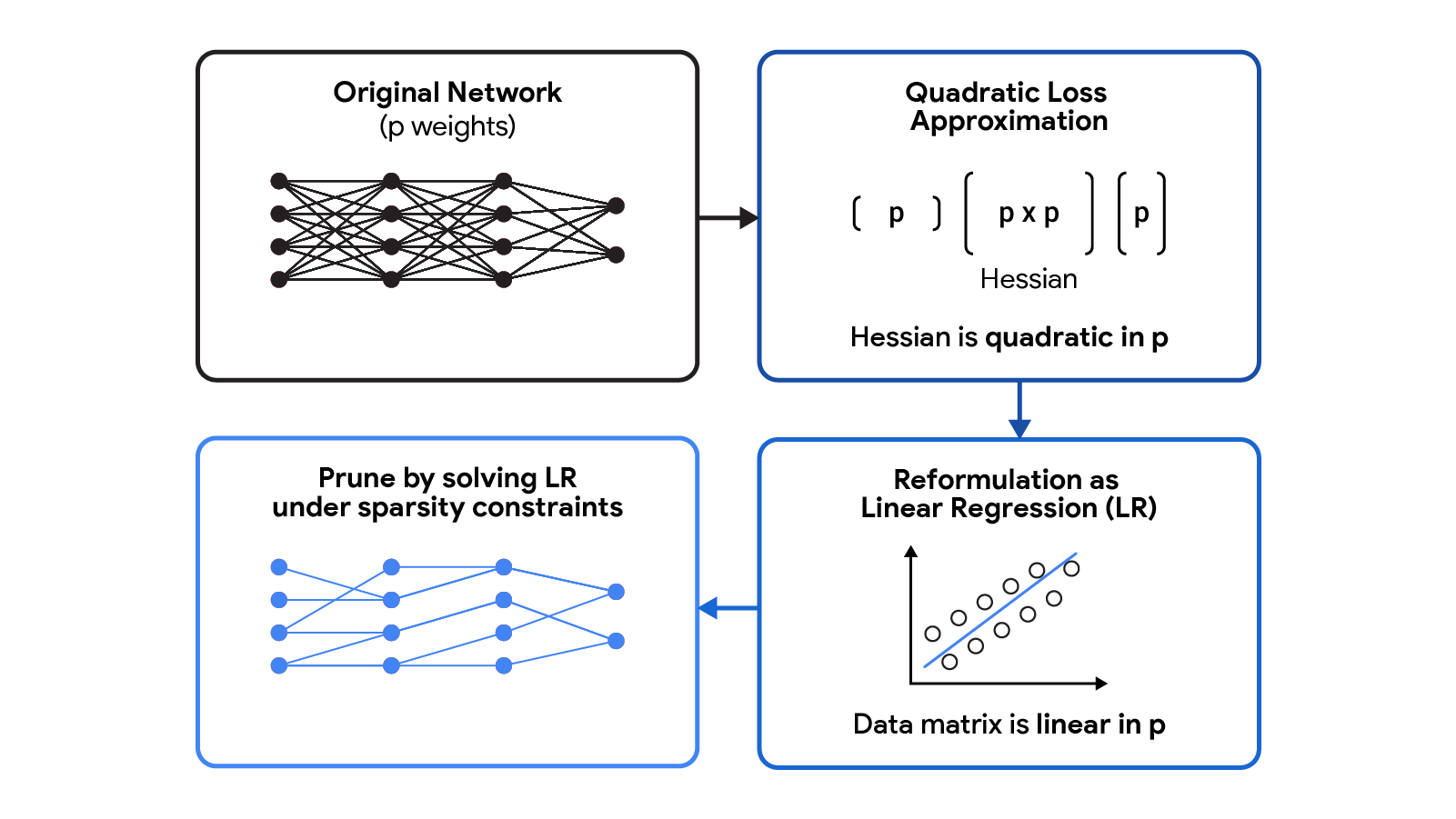 |
| CHITAは、高価なヘッシアン行列が必要な二次損失の近似を、線形回帰(LR)問題として再定式化します。LRのデータ行列はpに対して線形であり、元の二次近似よりもスケーラブルな再定式化が可能です。 |
スケーラブルな最適化アルゴリズム
CHITAは、次のスパース性制約の下で剪定を線形回帰問題に変換します:最大k個の回帰係数のみが非ゼロであることができます。この問題の解を得るために、よく知られた反復ハードスレッショルディング(IHT)アルゴリズムの変更を考えます。IHTは勾配降下法を実行し、各更新後に次の事後処理ステップを実行します:最大k個(つまり、絶対値が最も大きいk個の係数)以外のすべての回帰係数をゼロに設定します。IHTは通常、問題に対して良い解を提供し、異なる剪定候補を探索し、重みを共同で最適化することでそれを行います。
問題のスケールのため、定数の学習率を持つ標準のIHTは非常に収束が遅くなることがあります。より速い収束のために、私たちは問題の構造を利用して適切な学習率を見つけるための新しいラインサーチ手法を開発しました。つまり、損失の十分な減少をもたらす学習率を見つけることができる手法です。また、CHITAの効率性と2次近似の品質を向上させるために、いくつかの計算手法を採用し、改良版のCHITA++を開発しました。
実験
私たちは、ResNetやMobileNetを含む異なるアーキテクチャを使用して、いくつかの最新の剪定手法とCHITAの実行時間と精度を比較します。
実行時間: CHITAは、単独の最適化ではなく、結合最適化を行う同様の手法よりもはるかにスケーラブルです。例えば、ResNetの剪定時には、CHITAのスピードアップは1000倍以上になることがあります。
剪定後の精度: 以下では、70%のモデルの重みを剪定するためにCHITAとCHITA++のパフォーマンスを、マグニチュード剪定(MP)、Woodfisher(WF)、および組合せ脳外科医(CBS)と比較しています。全体的に、CHITAとCHITA++の改善が見られます。
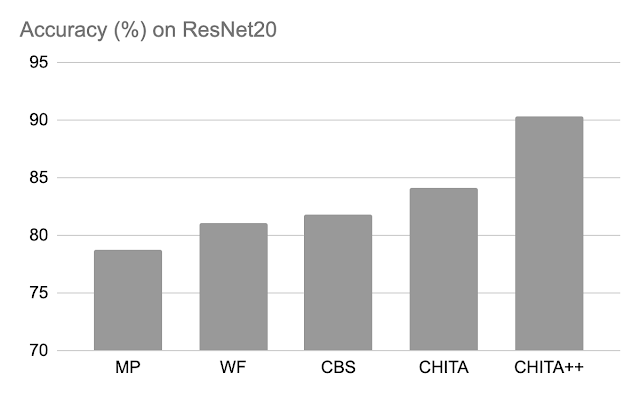 |
| ResNet20でのさまざまな手法の剪定後の精度。モデルの重みの70%を剪定した結果が報告されています。 |
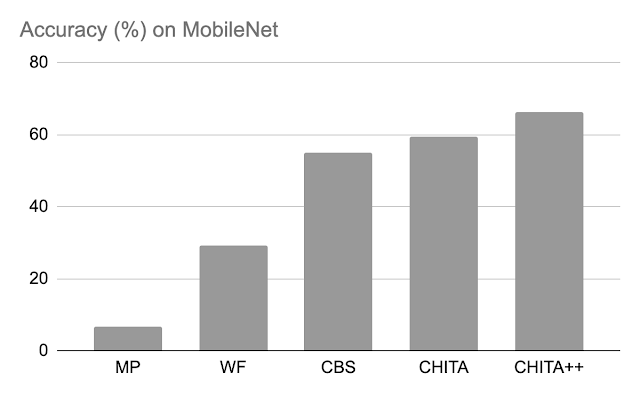 |
| MobileNetでのさまざまな手法の剪定後の精度。モデルの重みの70%を剪定した結果が報告されています。 |
次に、より大きなネットワークであるResNet50の剪定結果を報告します(これに関しては、ResNet20の図にリストされている一部の手法はスケールできませんでした)。ここではマグニチュード剪定とM-FACと比較しています。以下の図は、CHITAが幅広い疎なレベルでより優れたテスト精度を達成していることを示しています。
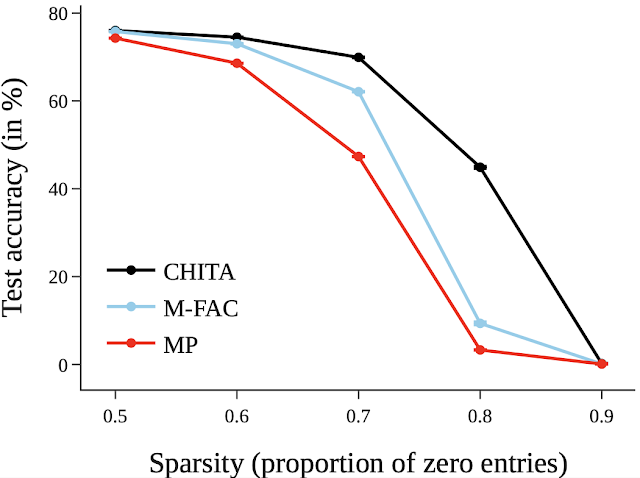 |
| さまざまな手法を使用した剪定ネットワークのテスト精度。 |
結論、制約、および今後の課題
私たちは、事前に学習されたニューラルネットワークを剪定するための最適化ベースのアプローチであるCHITAを提案しました。CHITAは、組合せ最適化と高次元統計学のアイデアを効果的に活用し、効率的に2次情報を使用することにより、スケーラビリティと競争力のあるパフォーマンスを提供します。
CHITAは、任意の重みを削除できる非構造化の剪定に対応するように設計されています。理論的には、非構造化の剪定は計算要件を大幅に削減することができます。しかし、これらの削減を実際に実現するには、スパースな計算をサポートする特殊なソフトウェア(および可能であればハードウェア)が必要です。一方、ニューロンのような構造全体を削除する構造化の剪定は、一般的なソフトウェアとハードウェア上で容易に達成できる改善を提供するかもしれません。CHITAを構造化の剪定に拡張することは興味深いでしょう。
謝辞
この研究は、GoogleとMITの共同研究の一環です。この記事と論文の準備において、Rahul Mazumder、Natalia Ponomareva、Wenyu Chen、Xiang Meng、Zhe Zhao、およびSergei Vassilvitskiiに感謝します。また、この記事のグラフィックを作成してくれたJohn Guilyardにも感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Google AIが教育環境でのオーディオブックに対するソーシャル意識を持つ時間的因果関係を考慮したレコメンダーシステム「STUDY」を紹介します
- スウィン・トランスフォーマー | モダンなコンピュータビジョンタスク
- 『強化学習における大規模な行動空間を処理する5つの方法』
- このNYUとGoogleの論文は、クロスモーダル表現におけるシーケンス長の不一致を克服するための共同音声テキストエンコーダの仕組みを説明しています
- 「機械に学習させ、そして彼らが私たちに再学習をさせる:AIの構築の再帰的性質」
- 『Photoshopを越えて:Inst-Inpaintが拡散モデルでオブジェクト除去を揺るがす』
- 「トランスフォーマーの単純化:あなたが理解する言葉を使った最先端の自然言語処理(NLP)— パート1 — イントロ」