「神秘的なニューラルマジックの解明:アクティベーション関数の探求」
神秘的なニューラルマジックの解明:アクティベーション関数の探求

なぜ活性化関数を使用するのか
ディープラーニングとニューラルネットワークは、データが各隠れ層を順次通過する相互接続されたノードで構成されています。しかし、線形関数の組み合わせは不可避的にまだ線形関数です。活性化関数は、データ内の複雑な非線形パターンを学習する必要がある場合に重要となります。
活性化関数を使用することの2つの主な利点は次のとおりです。
非線形性を導入する
現実世界のシナリオでは、線形関係は稀です。ほとんどの現実世界のシナリオは複雑で、さまざまな異なるトレンドに従います。このようなパターンを学習するには、線形回帰やロジスティック回帰などの線形アルゴリズムでは不可能です。活性化関数はモデルに非線形性を追加し、データ内の複雑なパターンや分散を学習することを可能にします。これにより、ディープラーニングモデルは画像や言語の領域を含む複雑なタスクを実行できます。
深いニューラル層を可能にする
前述のように、複数の線形関数を順次適用すると、出力は入力の線形結合のままです。各層の間に非線形関数を導入することで、異なる入力データの特徴を学習できるようになります。活性化関数がない場合、深く接続されたニューラルネットワークアーキテクチャを使用することは、基本的な線形回帰やロジスティック回帰アルゴリズムを使用するのと同じです。
活性化関数によって、ディープラーニングアーキテクチャは複雑なパターンを学習できるようになり、単純な機械学習アルゴリズムよりも強力になります。
ディープラーニングで使用される最も一般的な活性化関数のいくつかを見てみましょう。
シグモイド
バイナリ分類タスクでよく使用されるシグモイド関数は、実数値を0から1の範囲にマッピングします。
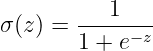
上記の方程式は以下のようになります:
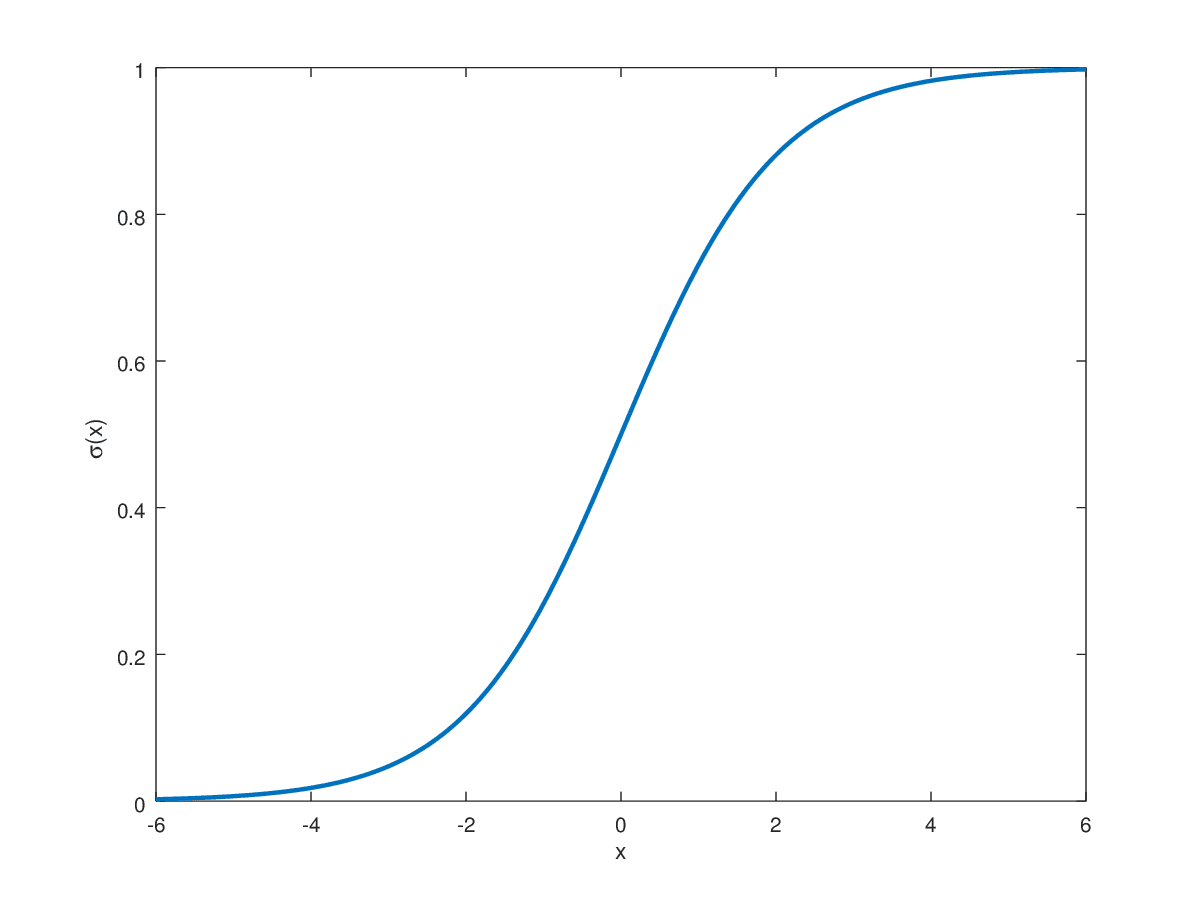
シグモイド関数は、ターゲットラベルが0または1のバイナリ分類タスクの出力層で主に使用されます。これにより、出力がこの範囲内に制限されるため、シグモイドはこのようなタスクに適しています。非常に正の値は1に近づくようにシグモイド関数がマッピングし、逆に、負の無限大に近づく値は0にマッピングされます。これらの間のすべての実数値は、S字のトレンドで範囲0から1にマッピングされます。
欠点
飽和点
シグモイド関数は、バックプロパゲーション中の勾配降下法にとって問題を引き起こします。S字曲線の中心に近い値以外では、勾配は非常にゼロに近くなり、トレーニングに問題を引き起こします。漸近線に近いと、小さい勾配は収束を著しく遅くすることができます。
ゼロ中心ではない
ゼロ中心の非線形関数を持つことが実証されており、平均活性化値が0に近くなることが保証されます。このような正規化された値を持つことにより、勾配降下法の収束がより速くなります。必須ではありませんが、ゼロ中心の活性化はより速いトレーニングを可能にします。シグモイド関数は、入力が0のときに0.5に中心化されます。これは、シグモイドを隠れ層で使用する際の欠点の1つです。
ハイパボリックタンジェント
双曲線正接関数は、シグモイド関数の改良版です。[0,1]の範囲ではなく、ハイパボリックタンジェント関数は実数値を-1から1の範囲にマッピングします。
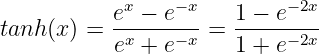
ハイパボリックタンジェント関数は以下のようになります:
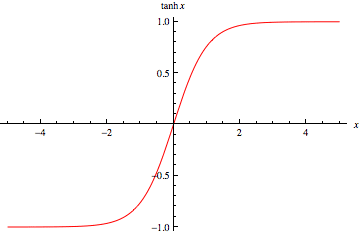
タンジェントハイパボリック関数(TanH関数)は、シグモイドと同じS字カーブを描きますが、ゼロ中心化されています。これにより、トレーニング中の収束が速くなり、シグモイド関数の欠点の一つを改善します。そのため、ニューラルネットワークアーキテクチャの隠れ層での使用に適しています。
欠点
飽和点
タンジェントハイパボリック関数(TanH関数)は、シグモイドと同じS字カーブを描きますが、ゼロ中心化されています。これにより、シグモイド関数よりも速い収束が可能になります。そのため、ニューラルネットワークアーキテクチャの隠れ層での使用に適しています。
計算コスト
現代では大きな問題ではありませんが、指数関数の計算は他の一般的な代替手段よりもコストが高いです。
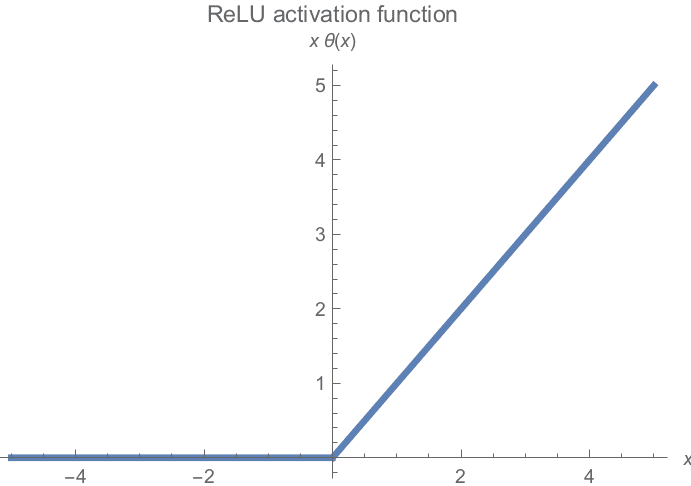
ReLU
実践で最も一般的に使用される活性化関数であるRectified Linear Unit Activation(ReLU)は、最も単純でありながらも最も効果的な非線形関数です。
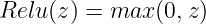
非負の値はそのまま保持し、負の値はすべて0にクランプされます。視覚化すると、ReLU関数は以下のようになります:
欠点
Dying ReLU
グラフの片側で勾配がフラットになります。負の値は勾配がゼロになるため、ニューロンの半分はトレーニングへの寄与が最小限になる可能性があります。
非制約の活性化
グラフの右側では、勾配に制限がありません。勾配の値があまりにも高い場合、勾配が爆発する問題が発生する可能性があります。この問題は、勾配クリッピングとウェイトの初期化技術によって通常修正されます。
ゼロ中心ではない
Sigmoidと同様に、ReLU活性化関数もゼロ中心ではありません。同様に、これは収束に問題を引き起こし、トレーニングを遅くする原因となります。
すべての欠点にもかかわらず、ReLUはニューラルネットワークアーキテクチャのすべての隠れ層のデフォルト選択肢であり、実証された効率性があります。
重要なポイント
最も一般的な活性化関数の3つについて知ったところで、シナリオに最適な選択肢はどのように判断すれば良いでしょうか?
データの分布や具体的な問題に依存する場合もありますが、実践では広く使用されているいくつかの基本的な出発点があります。
- シグモイドは、ターゲットラベルが0または1のバイナリ問題の出力活性化にのみ適しています。
- TanHは、ReLUや類似の関数に主に置き換えられましたが、RNNの隠れ層でまだ使用されています。
- その他のシナリオでは、ディープラーニングアーキテクチャの隠れ層のデフォルト選択肢はReLUです。
Muhammad Arhamは、コンピュータビジョンと自然言語処理の分野で活動するディープラーニングエンジニアです。彼はVyro.AIでグローバルトップチャートに到達したいくつかの生成型AIアプリケーションの展開と最適化に取り組んでいます。彼は知的システムのための機械学習モデルの構築と最適化に興味を持ち、継続的な改善を信じています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- メディアでの顔のぼかしの力を解き放つ:包括的な探索とモデルの比較
- 「教師付き学習の実践:線形回帰」
- 「トランスフォーマーとサポートベクターマシンの関係は何ですか? トランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする」
- 富士通とLinux Foundationは、富士通の自動機械学習とAIの公平性技術を発表:透明性、倫理、アクセシビリティの先駆者
- 「言語モデルは放射線科を革新することができるのか?Radiology-Llama2に会ってみてください:指示調整というプロセスを通じて特化した大規模な言語モデル」
- 「InstaFlowをご紹介します:オープンソースのStableDiffusion(SD)から派生した革新的なワンステップ生成型AIモデル」
- マルチAIの協力により、大規模な言語モデルの推論と事実の正確さが向上します






