推論エンドポイントを使用して、短時間でMusicGenを展開する
短時間でMusicGenを展開するために推論エンドポイントを使用する
MusicGenは、テキストのプロンプトとオプションのメロディを入力として、音楽を出力する強力な音楽生成モデルです。このブログポストでは、MusicGenを使用して音楽を生成する方法をInference Endpointsを使用して説明します。
Inference Endpointsを使用すると、カスタムハンドラと呼ばれるカスタム推論関数を記述することができます。これは、モデルがtransformersの高レベル抽象pipelineで直接サポートされていない場合に特に便利です。
transformersのパイプラインは、transformersベースのモデルを使用して推論を実行するための強力な抽象化を提供しています。Inference Endpointsは、わずか数回のクリックでモデルを簡単にデプロイするために、パイプラインAPIを活用しています。ただし、Inference Endpointsは、パイプラインを持たないモデルや、さらには非トランスフォーマーモデルをデプロイするためにも使用できます。これは、カスタムハンドラと呼ばれるカスタム推論関数を使用して実現されます。
これをMusicGenの例を使用してプロセスをデモンストレーションしましょう。MusicGenのカスタムハンドラ関数を実装してデプロイするためには、以下の手順が必要です:
- 提供したいMusicGenリポジトリを複製する。
handler.pyとrequirements.txtにカスタムハンドラとその依存関係を記述し、複製したリポジトリに追加する。- そのリポジトリにInference Endpointを作成する。
または、単に最終結果を使用してカスタムのMusicGenモデルリポジトリをデプロイすることもできます。その場合は、上記の手順に従うだけです 🙂
さあ、始めましょう!
まず、facebook/musicgen-largeリポジトリを自分のプロフィールに複製します。
次に、handler.pyとrequirements.txtを複製したリポジトリに追加します。まず、MusicGenでの推論の実行方法を見てみましょう。
from transformers import AutoProcessor, MusicgenForConditionalGeneration
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large")
inputs = processor(
text=["80sのポップトラックでベースのドラムとシンセサイザーがあります"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)どのような音が出るか聞いてみましょう。
お使いのブラウザは、オーディオ要素をサポートしていません。
オプションで、出力をオーディオスニペットで条件付けることもできます。つまり、生成されたテキストのオーディオを入力オーディオと組み合わせた補完スニペットを生成します。
from transformers import AutoProcessor, MusicgenForConditionalGeneration
from datasets import load_dataset
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large")
dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset))["audio"]
# オーディオサンプルの前半を取得する
sample["array"] = sample["array"][: len(sample["array"]) // 2]
inputs = processor(
audio=sample["array"],
sampling_rate=sample["sampling_rate"],
text=["80sのブルーストラックでグルーヴィーなサックスがあります"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)聞いてみましょう。
お使いのブラウザは、オーディオ要素をサポートしていません。
両方の場合、model.generateメソッドはオーディオを生成し、テキスト生成と同じ原則に従います。詳細については、私たちの生成方法のブログポストで詳しく説明しています。
よし!上記で概説した基本的な使用法を持つMusicGenをデプロイして楽しんで利益を得ましょう!
まず、handler.pyでカスタムハンドラを定義します。Inference Endpointsのテンプレートを使用して、__init__メソッドと__call__メソッドをオーバーライドして、カスタム推論コードを記述できます。__init__ではモデルとプロセッサを初期化し、__call__ではデータを受け取り、生成された音楽を返します。修正したEndpointHandlerクラスは以下の通りです。 👇
from typing import Dict, List, Any
from transformers import AutoProcessor, MusicgenForConditionalGeneration
import torch
class EndpointHandler:
def __init__(self, path=""):
# パスからモデルとプロセッサをロードする
self.processor = AutoProcessor.from_pretrained(path)
self.model = MusicgenForConditionalGeneration.from_pretrained(path, torch_dtype=torch.float16).to("cuda")
def __call__(self, data: Dict[str, Any]) -> Dict[str, str]:
"""
Args:
data (:dict:):
テキストプロンプトと生成パラメータを含むペイロード。
"""
# 入力を処理する
inputs = data.pop("inputs", data)
parameters = data.pop("parameters", None)
# 前処理
inputs = self.processor(
text=[inputs],
padding=True,
return_tensors="pt",).to("cuda")
# 入力をすべてのkwargsと共に渡す
if parameters is not None:
with torch.autocast("cuda"):
outputs = self.model.generate(**inputs, **parameters)
else:
with torch.autocast("cuda"):
outputs = self.model.generate(**inputs,)
# 予測を後処理する
prediction = outputs[0].cpu().numpy().tolist()
return [{"generated_audio": prediction}]シンプルにするため、この例ではテキストから音声の生成のみを行い、メロディとの組み合わせは行いません。次に、推論コードを実行するために必要なすべての依存関係を含むrequirements.txtファイルを作成します:
transformers==4.31.0
accelerate>=0.20.3これらの2つのファイルをリポジトリにアップロードするだけで、モデルを提供するのに十分です。
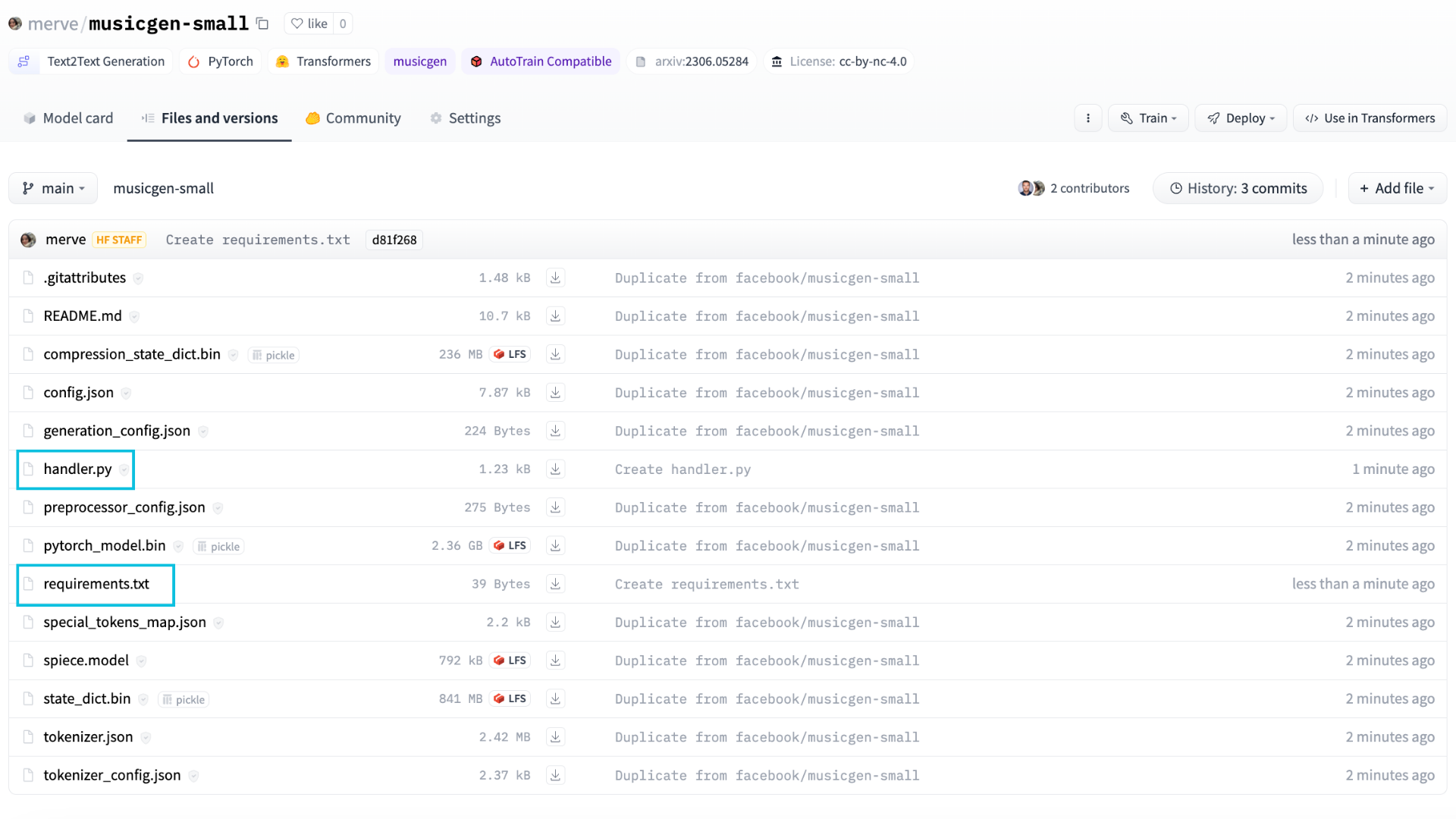
これで、推論エンドポイントを作成できます。推論エンドポイントページに移動し、最初のモデルをデプロイをクリックします。”モデルリポジトリ”フィールドに、複製したリポジトリの識別子を入力します。次に、希望するハードウェアを選択し、エンドポイントを作成します。musicgen-largeには、少なくとも16 GBのRAMを持つインスタンスが必要です。
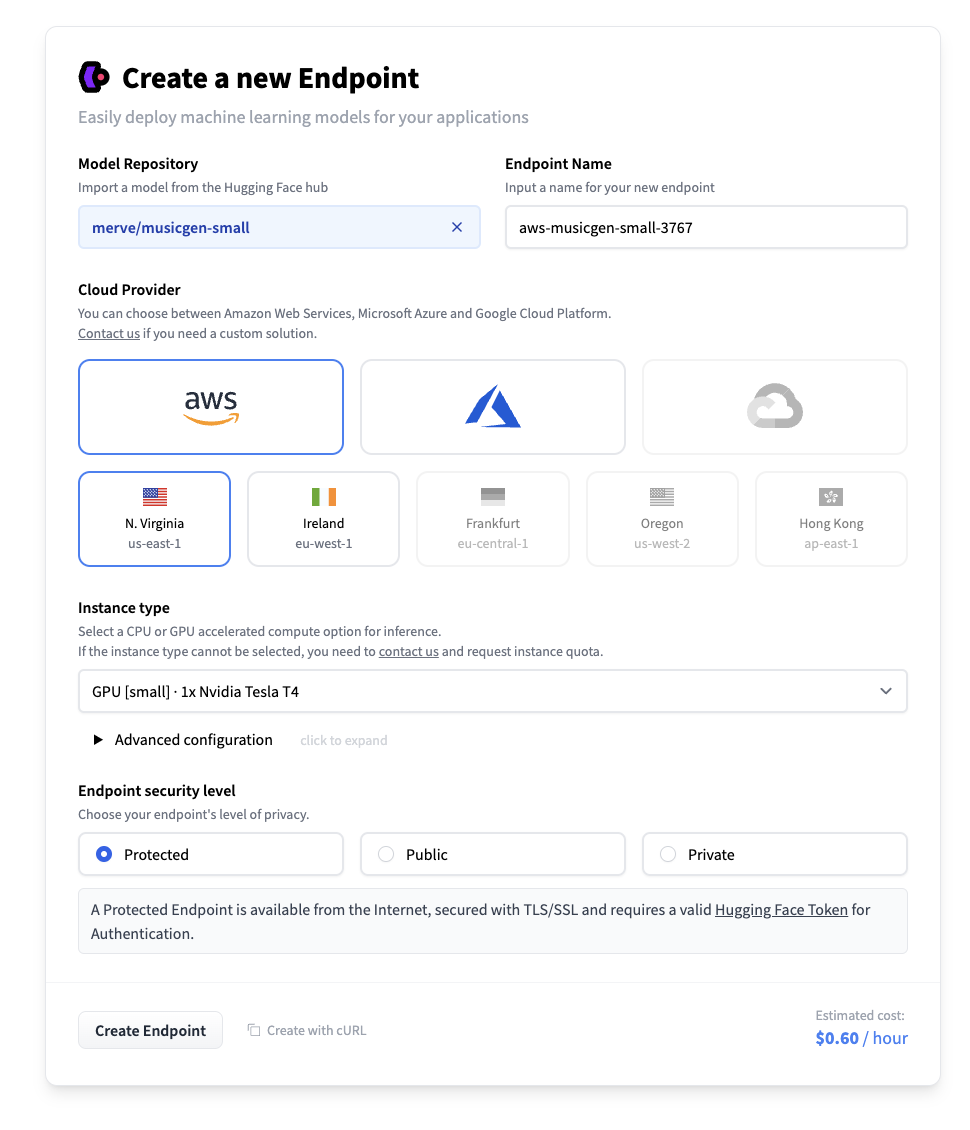
エンドポイントを作成した後、自動的に起動され、リクエストを受け付ける準備ができます。
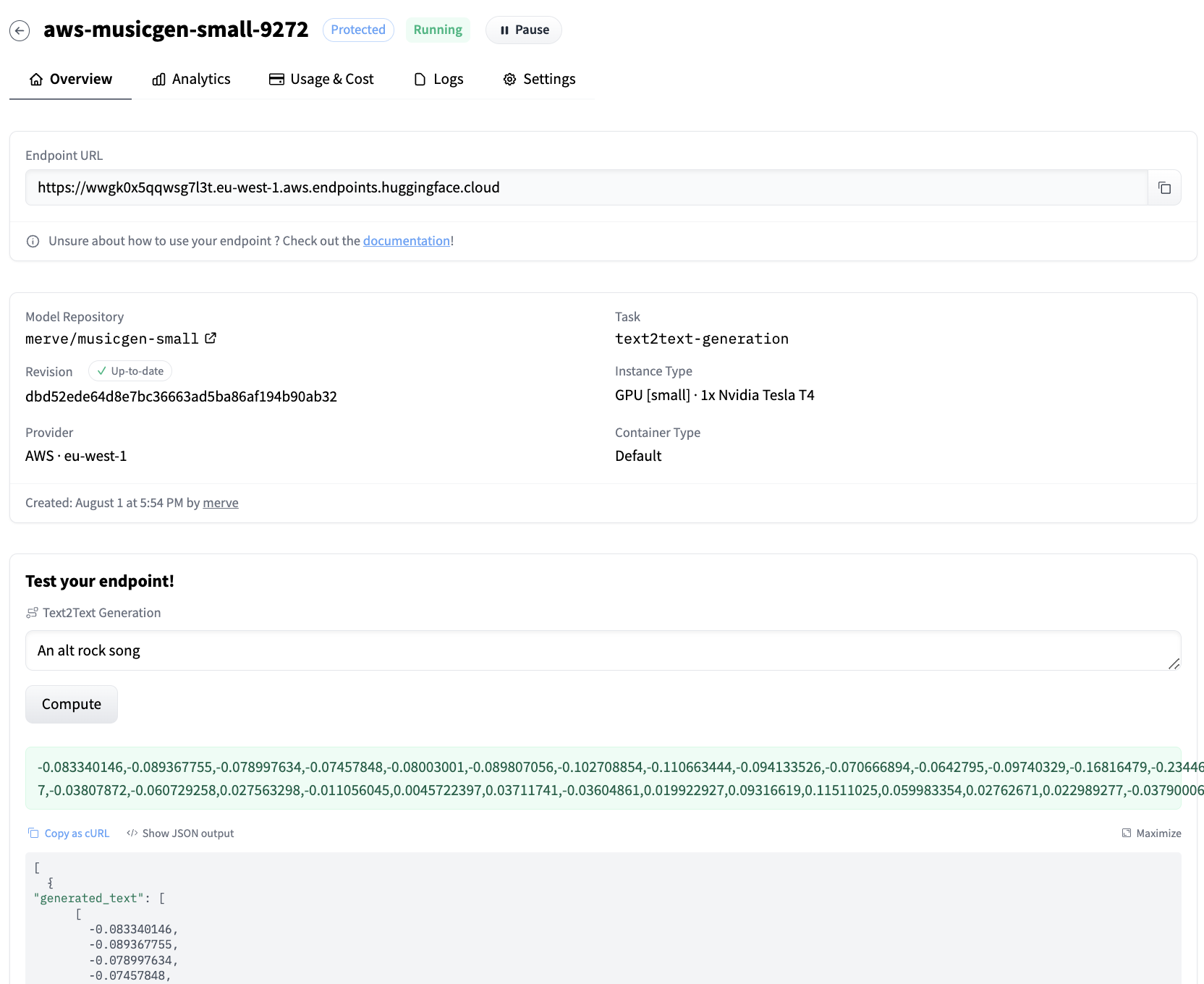
以下のスニペットでエンドポイントにクエリを送信できます。
curl URL_OF_ENDPOINT \
-X POST \
-d '{"inputs":"happy folk song, cheerful and lively"}' \
-H "Authorization: {YOUR_TOKEN_HERE}" \
-H "Content-Type: application/json"以下の波形シーケンスが出力として表示されます。
[{"generated_audio":[[-0.024490159,-0.03154691,-0.0079551935,-0.003828604, ...]]}]以下はその音です:
お使いのブラウザはオーディオ要素をサポートしていません。
huggingface-hubのPythonライブラリのInferenceClientクラスを使用して、エンドポイントにアクセスすることもできます。
from huggingface_hub import InferenceClient
client = InferenceClient(model = URL_OF_ENDPOINT)
response = client.post(json={"inputs":"an alt rock song"})
# response looks like this b'[{"generated_text":[[-0.182352,-0.17802449, ...]]}]
output = eval(response)[0]["generated_audio"]生成されたシーケンスを好きなようにオーディオに変換することができます。Pythonのscipyを使用して.wavファイルに書き込むことができます。
import scipy
import numpy as np
# output is [[-0.182352,-0.17802449, ...]]
scipy.io.wavfile.write("musicgen_out.wav", rate=32000, data=np.array(output[0]))以上です!
以下のデモを使ってエンドポイントを試してみてください。
結論
このブログ記事では、カスタム推論ハンドラを使用してMusicGenを推論エンドポイントをデプロイする方法を示しました。同じテクニックは、関連するパイプラインを持たないHubの他のモデルにも使用することができます。ただし、handler.pyのエンドポイントハンドラクラスをオーバーライドし、requirements.txtをプロジェクトの依存関係に合わせて追加する必要があります。
詳細はこちら
- カスタムハンドラに関する推論エンドポイントのドキュメント
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Gradient Checkpointing、LoRA、およびQuantizationを使用して、単一のGPUにLLMをフィットさせてください
- 「ソースフリーなドメイン適応の汎用的な方法を探求する」
- 「セマンティックウェブはどうなったのか?」
- なぜシリコンバレーは人工知能の拠点となっているのか
- 究極のGFNサーズデー:41の新しいゲームに加えて、8月には「Baldur’s Gate 3」の完全版リリースと初めてベセスダのタイトルがクラウドに参加します
- 『DeepHowのCEO兼共同創業者、サム・ジェン氏によるインタビューシリーズ』
- 「マルチスレッディングの探求:Pythonにおける並行性と並列実行」






