「機械学習分類問題のさまざまな性能評価指標を知る」
知るさまざまな機械学習性能評価指標
この記事では、機械学習の分類タスクで使用されるさまざまなパフォーマンス指標について学びます。また、これらのパフォーマンス指標の正しい使用方法もカバーします。
まず、パフォーマンス指標とは何を意味するのかについて考えてみましょう。
機械学習の文脈では、パフォーマンス指標は訓練済みモデルの性能を評価するための計測ツールと考えることができます。
通常、パフォーマンスの標準的な指標として「正解率」が考慮されます。しかし、分類問題の場合にはこのアプローチに欠点があります。具体例を使って説明しましょう。
バリデーションデータセットに100行のデータがあるとします。ターゲット列には「A」と「B」という2つのユニークな値があります(典型的な2値分類問題)。バリデーションデータセットのターゲット列には80個のAと20個のBがあるとします。ここで、入力特徴に関係なく常に「A」を出力する基本モデルを使用して、バリデーションデータセットの出力を予測してみましょう。このモデルは非常にシンプルであり、データに適合せず、新しいデータに対してはうまく一般化できない可能性が高いです。しかし、ここではバリデーションデータで80%の正解率を得ています。これは非常に誤解を招く結果です。
このようなクラスの出現頻度に偏りのあるデータセットは、不均衡または偏ったデータセットと呼ばれます。不均衡なデータセットでは、正解率の指標は誤解を招く結果を示します。そのため、モデルのパフォーマンスを測定するために他の手段が必要です。
偏ったデータセットには正解率のパフォーマンス指標の使用は推奨されません。
注:均衡したデータセットでは正解率の指標を使用することは問題ありません。
他のパフォーマンス指標について学びましょう。
- 混同行列
- 適合率
- 再現率
- F1スコア
- 受信者動作特性(ROC)曲線の下の面積
混同行列
混同行列の一般的なアイデアは、「A」と分類されたインスタンスが「B」と誤分類される回数と、その逆の回数を数えることです。
混同行列を計算するためには、実際のターゲット値と比較できる予測値が必要です。
混同行列の各行は実際のクラスを表し、各列は予測されたクラスを表します。
「A」と「B」というユニークなカテゴリを持つターゲット列の例を考えてみましょう。ここではBを非Aと呼びましょう。
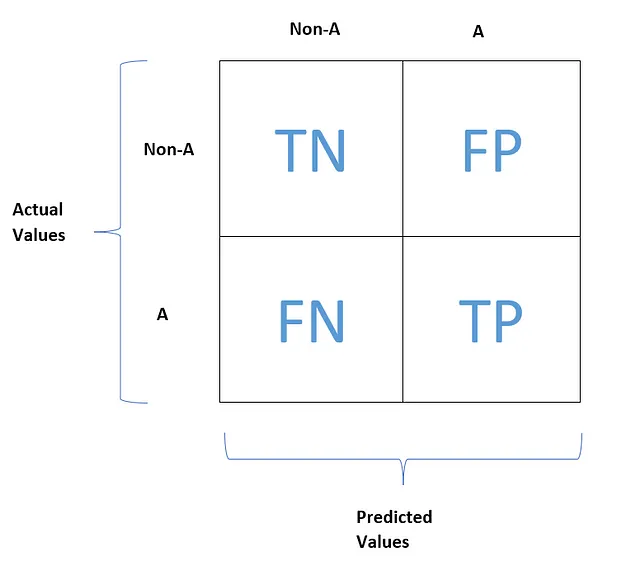
これが典型的な混同行列の見た目です。
TN、FP、FN、TPは、それぞれ真陰性、偽陽性、偽陰性、真陽性を表します。次に、これらの用語がどのような意味を持つのかを理解しましょう。
真陰性(TN)は、正しく負の特徴値(非A)と予測された負の特徴値の数を提供します。
偽陽性(FP)は、誤って正の特徴値(非A)と予測された負の特徴値の数を提供します。
偽陰性(FN)は、誤って負の特徴値(A)と予測された正の特徴値の数を提供します。
真陽性(TP)は、正しく正の特徴値(A)と予測された正の特徴値の数を提供します。
完璧な分類器とは以下の条件を満たすものと考えることができます:
- FP = FN = 0
- TP ≥ 0 かつ TN ≥ 0
言い換えると、完璧な分類器の混同行列は、主対角線上のみに非ゼロの値を持つことになります。
混同行列はモデルのパフォーマンスについて多くの情報を提供します。ただし、行列であるため、一目で把握するのは難しいです。そのため、より簡潔な指標を使用してモデルのパフォーマンスを測定したいと考えています。
適合率、再現率、およびF1スコア
適合率と再現率は、モデルの性能評価のための簡潔な指標を提供します。
適合率は、陽性の予測の正確さと考えることができます。混同行列を見ることで簡単に適合率を求めることができます。

また、再現率は、正しく予測された陽性観測値の数と陽性観測値の総数の比率で求めることができます。

再現率は、感度や真陽性率など他の名前でも呼ばれることもあります。
特に2つの分類器を比較する簡単な方法が必要な場合、適合率と再現率を組み合わせた単一の指標であるF1スコアを結合することがしばしば便利です。
適合率と再現率の調和平均をF1スコアと呼びます。

一般的に、調和平均はより低い値により重みを与えます。そのため、適合率と再現率が高い場合、分類器は高いF1スコアを得ることができます。
しかし、これは常に当てはまるわけではありません。いくつかの場合では、高い適合率と低い再現率が必要な場合もありますし、逆に低い適合率と高い再現率が必要な場合もあります。それは、手元のタスクに依存します。これを理解するために、2つの例を考えてみましょう。
例1:
子供向けの安全な動画を検出する分類器をトレーニングしたとします。この分類器では、安全な動画の一部が非安全と予測されても問題ありません。ただし、非安全な動画が安全と予測される回数はできるだけ少なくする必要があります。これは、高いFNと低いFPを持つ厳しい条件をこの分類器に設定することを意味します。
高いFNは低い再現率を示し、低いFPは高い適合率を示します。

例2:
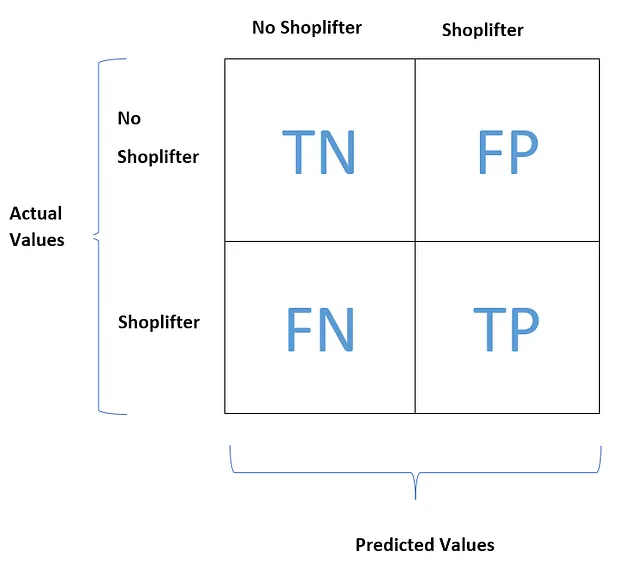
監視カメラでショップリフターを検出する分類器をトレーニングするとしましょう。この場合、無実の人物がショップリフターと予測されても問題ありません(道徳的には正しい方法ではありませんが、ここでは機械学習の文脈のみを考慮してください)。ただし、ショップリフターが無実の人物と予測される回数はできるだけ少なくする必要があります。これは、高いFNと低いFPを持つ厳しい条件をこの分類器に設定することを意味します。
低いFNは高い再現率を示し、高いFPは低い適合率を示します。
高い再現率と高い適合率の場合に戻りましょう。残念ながら、これは実際のシナリオでは不可能です。高い再現率と低い適合率、または低い再現率と高い適合率のいずれかを得ることになります。
この場合、適合率-再現率曲線を見て、課題に応じて適合率と再現率がどちらもかなり高い箇所を選択します。
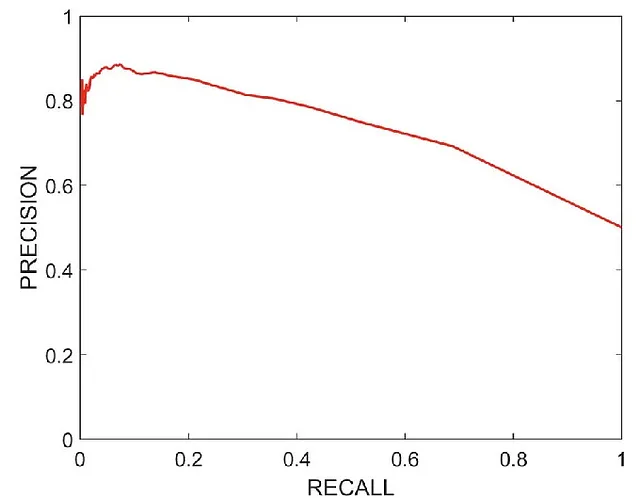
これが典型的な適合率-再現率曲線の見た目です。グラフを見ることで、再現率=0.65、適合率=0.75の点を得ることができます。これにより、適合率と再現率の両方に対してかなり高い値を得ることができます。
受信者操作特性(ROC)曲線
ROC曲線は、2クラス分類問題の評価指標として使用されます。ROC曲線は、真陽性率(つまり再現率)と偽陽性率をプロットします。
これが典型的なROC曲線の見た目です。
真陽性率(TPR)と偽陽性率(FPR)は、以下の式を使用して求めることができます。
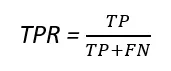
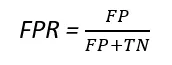
点線は純粋にランダムな分類モデルのROC曲線を表しており、良い分類器は常にその曲線からできるだけ遠ざかるようになります(左上の角に向かって)。
モデルのROC曲線がランダムモデルのROC曲線からどれだけ遠いかを知る方法の1つは、曲線下の面積を求めることです。モデルのROC曲線の下の面積が1と等しい場合、それはランダムモデルのROC曲線からできるだけ遠いことを意味します。したがって、この場合、モデルは完璧なモデルと考えられます。ROC曲線の下の面積が大きいモデルがより優れたモデルとなります。
ROC曲線の下の面積は、2つの分類器を比較するために使用することができます。ROC曲線の下の面積がより大きい分類器は、パフォーマンスの面でより優れたモデルとなります。
適合率-再現率曲線とROC曲線の使用時期
一般的なルールとして、陽性クラスがまれである場合や偽陽性よりも偽陰性に関心がある場合は、適合率-再現率曲線を選択することをお勧めします。それ以外の場合は、ROC曲線を使用してください。
たとえば、まれな病気の感染症の研究を行っている場合、まれな陽性クラスが得られます。この場合、パフォーマンス指標としては適合率-再現率曲線がより適しています。
詳細は次をご覧ください:
scikit-learnドキュメント
「Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow」という書籍
(1527) The NO CONFUSION matrix! // What is the confusion matrix? // Confusion matrix visual explanation — YouTube
(1527) Never Forget Again! // Precision vs Recall with a Clear Example of Precision and Recall — YouTube
アウトロ
この記事がお気に入りになったことを願っています。VoAGIで私の他の記事を読むためにフォローしてください。
以下の方法で私と連絡を取ることができます。
ウェブサイト
メールアドレス: [email protected]
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 光ベースのコンピューティング革命:強化された光ニューラルネットワークでChatGPTタイプの機械学習プログラムを動かす
- 「Advanced Reasoning Benchmark(ARB)に会いましょう:大規模な言語モデルを評価するための新しいベンチマーク」
- 「FACTOOLにご紹介いたします:大規模言語モデル(例:ChatGPT)によって生成されたテキストの事実エラーを検出するためのタスクとドメインに依存しないフレームワーク」
- LGBMClassifier 入門ガイド
- 「MLOpsの全機械学習ライフサイクルをカバーする:論文要約」
- 「ゲート付き再帰型ユニット(GRU)の詳細な解説:RNNの数学的背後理論の理解」
- NLPの探索 – NLPのキックスタート(ステップ#1)