機械学習を直感的に理解する
直感的に機械学習を理解する
ML:オーバーコンプリケートな数学なしで知っておく必要があるすべて

機械学習とは何ですか?
確かに、ChatGPTのようなモデルの背後にある実際の理論は非常に難しいですが、機械学習(ML)の基本的な直感は直感的です!では、MLとは何ですか?
機械学習は、コンピュータがデータを使用して学習することを可能にします。
しかし、これはどういう意味ですか?コンピュータはどのようにデータを使用するのですか?コンピュータが学習するとはどういうことですか?そして、まず、誰が気にするのですか?まず最後の質問から始めましょう。
今日では、データは私たちの周りにあります。したがって、明示的にプログラムされることなくデータ内の意味のあるパターンを見つけるためにMLのようなツールを使用することがますます重要になっています!言い換えれば、MLを利用することで、一般的なアルゴリズムをさまざまな問題に成功裏に適用することができます。
機械学習にはいくつかの主要なカテゴリがありますが、その中でも代表的なタイプは教師あり学習(SL)、教師なし学習(UL)、強化学習(RL)です。今日は教師あり学習について説明しますが、後続の投稿では教師なし学習と強化学習について詳しく説明したいと思います。
1分のSLスピードラン
わかります、この記事全体を読みたくないかもしれません。このセクションでは、後のセクションでより詳しく説明する前に、非常に基本的なことを教えます(多くの人にとっては必要な情報です!)。
教師あり学習は、さまざまな特徴を使用してラベルを予測する方法を学習することです。
例えば、カラット、カット、クラリティなどの特徴を使用してダイヤモンドの価格を予測する方法を見つけようとしていると想像してください。ここでは、特定のダイヤモンドの特徴を入力として受け取り、関連する価格を出力する関数を学習することが目標です。
人間は例を通じて学ぶように、この場合、コンピュータも同じことをします。予測ルールを学習するためには、このMLエージェントがダイヤモンドの「ラベル付きの例」、つまり特徴と価格の両方を含む例が必要です。教師あり学習の前提条件として、ラベル付きの例が「確かなもの」として考慮されることが重要です。
さて、最も基本的な基礎を説明したので、データサイエンス/MLパイプラインの詳細について少し詳しく説明しましょう。
問題設定
この教科書に触発された、非常に関連性の高い例を使用しましょう。あなたが「ジャスティンメロン」という珍しい果物しか食べるものがない島に取り残されたと想像してください。特にジャスティンメロンを食べたことはありませんが、他の果物をたくさん食べたことがあり、腐った果物は食べたくないことを知っています。また、通常、果物が腐っているかどうかは色と硬さで判断できることも知っていますので、ジャスティンメロンにも同様のことが当てはまると推測し、仮定します。
機械学習の観点では、ジャスティンメロンが腐っているかどうかを正確に予測するために、色と硬さという2つの特徴を決定するために事前の業界知識を使用しました。
しかし、果物が腐っていることを示す色と硬さはどうやって知ることができますか?誰にもわかりません。試してみる必要があります。機械学習の観点では、データが必要です。具体的には、本物のジャスティンメロンとそれらに関連するラベルから成るラベル付きデータセットが必要です。
データの収集/処理
したがって、次の数日間、メロンを食べて、色、硬さ、メロンが腐っているかどうかを記録します。腐ったメロンを食べ続ける苦痛な数日後、次のようなラベル付きデータセットが得られました:
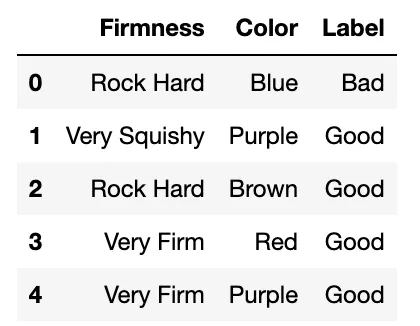
各行は特定のメロンであり、各列は対応するメロンの特徴/ラベルの値です。ただし、特徴は数値ではなくカテゴリカルなので、単語が含まれていることに注意してください。
実際には、コンピュータが処理できるように数値が必要です。カテゴリカルな特徴を数値の特徴に変換するためのさまざまな技術があります。ワンホットエンコーディングから埋め込みなど、さまざまな方法があります。
一番簡単なことは、「Label」の列を「Good」の列に変換することです。メロンが良い場合は1、悪い場合は0になります。今のところ、色と硬さを-10から10の範囲に変換する方法があると仮定します。ボーナスポイントとして、色のようなカテゴリカルな特徴をそのようなスケールに置くことの前提条件について考えてみてください。この前処理後、データセットは次のようになるかもしれません:
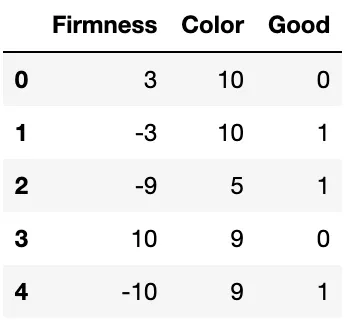
これでラベル付きのデータセットができました。つまり、監視学習アルゴリズムを適用することができます。アルゴリズムは分類アルゴリズムである必要があります。カテゴリ good (1) または bad (0) を予測しています。分類は、ダイヤモンドの価格のような連続した値を予測する回帰アルゴリズムと対照的です。
探索的データ分析
しかし、どのアルゴリズムを使用するのでしょうか?基本的なロジスティック回帰からハードコアなディープラーニングアルゴリズムまで、さまざまな複雑さの教師あり分類アルゴリズムがあります。まずは探索的データ分析(EDA)を行ってデータを確認しましょう:
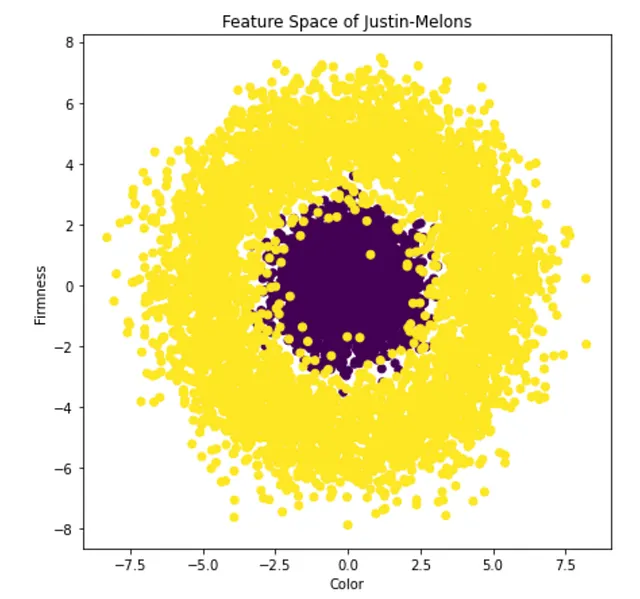
上記の画像は特徴空間のプロットです。2つの特徴があり、各例を2つの軸でプロットしています。また、関連するメロンが良い場合は紫色、悪い場合は黄色にします。わずかなEDAで明らかな答えがあります!
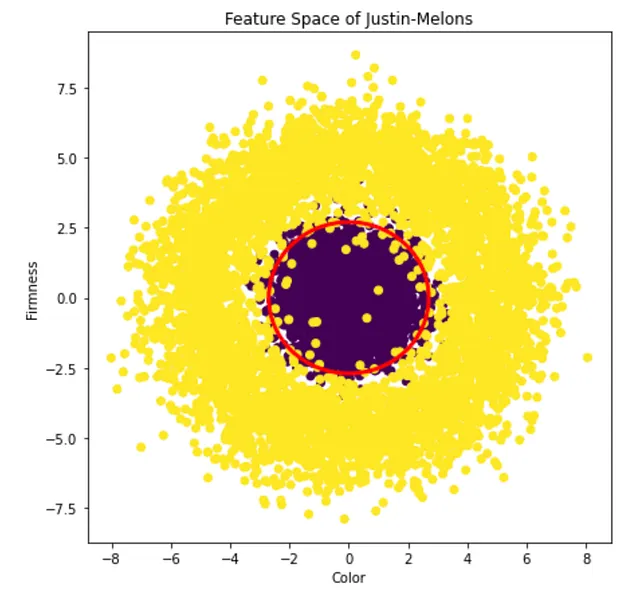
赤い円の内部にあるすべてのポイントを良いメロンと分類し、円の外部にあるポイントを悪いメロンと分類するのが適切でしょう。直感的には、完全に固いメロンも望ましくありませんが、極端に柔らかいメロンも望ましくありません。それよりも、その中間のものが望ましいですし、おそらく色にも同じことが言えるでしょう。
赤い円を決定境界とすることを決めましたが、これは予備的なデータの可視化に基づいているだけです。これを体系的にどのように決定するのでしょうか?これは特に問題が複雑な大きな問題の場合に重要です。数百の特徴がある場合、100次元の特徴空間を合理的な方法で可視化することは不可能です。
何を学んでいるのか?
最初のステップはモデルを定義することです。分類モデルはたくさんあります。それぞれが独自の仮定を持っているため、良い選択をすることが重要です。これを強調するために、最初に非常に悪い選択をします。
直感的なアイデアの1つは、各要素を重み付けして予測することです:
Justin CheighによるFormula using Embed Fun
たとえば、パラメータ w1 と w2 がそれぞれ2と1であるとします。また、入力のJustin MelonがColor = 4、Firmness = 6であるとします。すると、予測値 Good = (2 x 4) + (1 x 6) = 14 になります。
分類結果の14は、妥当なオプション(0または1)ではありません。これは実際には回帰アルゴリズムです。実際には、最も単純な回帰アルゴリズムである線形回帰の単純なケースです。
したがって、これを分類アルゴリズムに変換しましょう。線形回帰を使用し、出力がバイアス項 b より高い場合に1と分類することができます。実際には、出力が0より高い場合に1と分類するために、モデルに定数項を追加することで簡略化することができます。
数学では、PRED = w1 * 色 + w2 * 硬さ + b とします。そして、次のようになります:
Embed Funを使用したJustin Cheighによる式
これは確かに良いです。少なくとも分類を行っていますが、PREDをx軸、分類をy軸にしたプロットを作成しましょう:
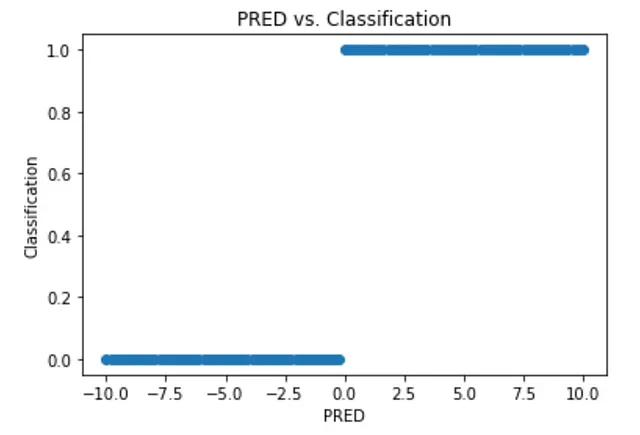
これは少し極端です。PREDのわずかな変化で分類が完全に変わってしまう可能性があります。一つの解決策は、モデルの出力がJustin-Melonが良いという確率を表すようにすることです。これは、曲線を滑らかにすることで実現できます:
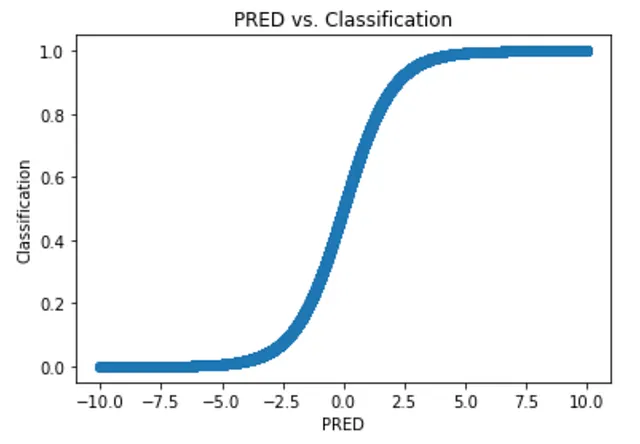
これはシグモイド曲線(またはロジスティック曲線)です。したがって、PREDを取り、この分岐関数を適用する代わりに、このシグモイド活性化関数を適用して上記のような滑らかな曲線を得ることができます。全体として、ロジスティックモデルは次のようになります:
Embed Funを使用したJustin Cheighによる式
ここで、sigmaはシグモイド活性化関数を表しています。素晴らしいですね、モデルはできました。あとは最適な重みとバイアスを見つけるだけです!このプロセスはトレーニングとして知られています。
モデルのトレーニング
素晴らしいですね、あとは最適な重みとバイアスを見つけるだけです!しかし、これは言うほど簡単ではありません。無限の可能性があり、最適なものとはどういう意味ですか?
まず後者の質問から始めましょう:最適な重みは、トレーニングセットで最高の正確さを達成するものです。
したがって、正確さを最大化するアルゴリズムを見つける必要があります。しかし、数学的には何かを最小化する方が簡単です。言葉で言えば、高い価値が「良い」とされる値関数を定義する代わりに、低い損失が「良い」とされる損失関数を定義することを好みます。通常、(2値)分類の損失にはバイナリクロスエントロピーなどが使用されますが、私たちは単純な例として「誤分類されたポイントの数を最小化する」とします。
これには、勾配降下法として知られるアルゴリズムを使用します。大まかに言うと、勾配降下法は近視のスキーヤーが山を下りようとしている様子に似ています。良い損失関数の重要な特性(そして私たちの粗い損失関数には実際に欠けているところ)の一つは、滑らかさです。パラメータ空間(パラメータの値と関連する損失を同じプロットに表示したもの)をプロットすると、山のような形になります。
したがって、まずランダムなパラメータから始めます。したがって、損失は悪い状態で始まる可能性があります。スキーヤーができるだけ速く山を下りようとするように、アルゴリズムはすべての方向を見て、最も損失を下げる方法を見つけようとします。ただし、スキーヤーは近視眼者なので、各方向にわずかにしか見ることができません。このプロセスを繰り返し、最終的には最下部に到達します(鋭い目の人々は実際には局所的な最小値に到達する可能性があることに気付くかもしれません)。この時点で、最終的に得られるパラメータはトレーニングされたパラメータです。
ロジスティック回帰モデルをトレーニングした後、パフォーマンスがまだ非常に悪く、正確さが60%程度(ほとんど推測と同じ程度)であることに気付きます。これは、モデルの仮定の一つを破っているためです。ロジスティック回帰は数学的には線形な決定境界しか出力できませんが、EDAから、決定境界は円形であるべきだということがわかっていました!
これを考慮に入れて、異なる、より複雑なモデルを試し、正確さが95%になるものを得ました!これで、良いJustin-Melonと悪いJustin-Melonを区別することができる完全にトレーニングされた分類器を持つことができ、望むだけの美味しいフルーツを食べることができます!
結論
一歩下がってみましょう。10分程度で、機械学習について多くのことを学びました。これは、基本的な教師あり学習のパイプライン全体を実質的に理解するための記事です。次は何でしょうか?
それはあなた次第です!一部の人にとって、この記事はMLの高レベルな全体像を把握するのに十分でした。他の人にとっては、この記事は多くの疑問を残すかもしれません。それは素晴らしいことです!この好奇心が、このトピックをさらに探求することを可能にするかもしれません。
たとえば、データ収集の段階では、特定の特徴を考慮せずに数日間で大量のメロンを食べると仮定しました。これは意味がありません。もし緑色でドロドロのジャスティンメロンを食べて激しい体調不良になったら、あなたはおそらくそのメロンを避けるでしょう。実際には、経験を通じて学習し、信念を更新することによって学びます。このフレームワークは、強化学習により類似しています。
また、もし1つの悪いジャスティンメロンが即座にあなたを殺す可能性があり、確信が持てないまま試すのは危険すぎると知っていた場合はどうでしょうか?これらのラベルがなければ、教師あり学習を実行することはできません。しかし、ラベルがなくても洞察を得る方法があるかもしれません。このフレームワークは、教師なし学習により類似しています。
今後のブログ投稿では、強化学習と教師なし学習について類推的に拡張したいと思っています。
読んでいただきありがとうございます!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Gitタグ:それらは何であり、どのように使用するのか
- 3つの難易度レベルでベクトルデータベースを説明する
- Stack Overflowで最もよく尋ねられるPythonリストの10の質問
- Pythonを使用したデータのスケーリング
- Metaphy LabsのAIエバンジェリストに会いましょう
- 今日、開発者の70%がAIを受け入れています:現在のテックの環境での大型言語モデル、LangChain、およびベクトルデータベースの台頭について探求する
- マイクロソフトの研究者たちは、ラベル付きトレーニングデータを使用せずにパレート最適な自己監督を用いたLLMキャリブレーションの新しいフレームワークを提案しています
