生成AI倫理’ (Seisei AI Rinri)
生成AI倫理' (Seisei AI Rinri)' 'AI Ethics Generation
自律コンテンツの時代における重要な考慮事項

生成型人工知能(AI)に関する騒ぎの中で、この変革的な技術を責任を持って実装する方法についての未解決の問題が増えています。このブログでは、欧州連合(EU)のAI倫理ガイドラインを概説し、大規模言語モデル(LLM)の使用時にAI倫理フレームワークを実装する際の重要な考慮事項について議論します。
信頼性のあるAIに関する倫理ガイドライン
2019年4月8日、欧州連合は人工知能(AI)の倫理的かつ責任ある使用のための枠組みを実施しました。この報告書では、信頼性のあるAIを構築するための3つの指針が定義されています:
- 法的:AIは法の支配と地域の規制に従う必要があります。
- 倫理的:AIシステムは倫理的であり、倫理的な原則と価値観に従う必要があります。
- 堅牢:AIは短期間で大規模な人口に重大な害を与える可能性があるため、技術的および社会的に堅牢である必要があります。
多国籍企業にとって、世界のある地域で法的および倫理的とされるものが、他の地域ではそうではない場合、どのようにこの枠組みを地政学的な境界を越えて適用すべきかという興味深い問題が生じます。多くの企業は、最も厳格な規制を採用し、それを全ての地域に一律に適用します。しかし、「一つのサイズがほとんど適している」というアプローチは適切または受け入れられるとは限りません。
EUの枠組みは、以下の図1.1に示されています。
図1.1:欧州連合のAI倫理フレームワーク
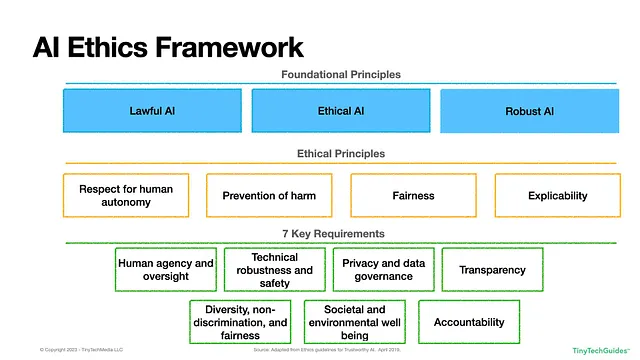
上記の3つの基本原則に基づいて、4つの倫理原則と7つの重要な要件が導かれます。倫理原則には以下が含まれます:
- 人間の自律性への尊重:この原則は、人間がAIとの相互作用において制御と自由を維持すべきであることを強調しています。「AIシステムは人間を不当に従属させたり、強制したり、欺いたり、操作したり、条件付けたり、群れたりしてはなりません。」[1]基本的に、AIは民主的なプロセスへの人間の参加を支援すべきです。一部の国では、市民に対して「社会的スコアリング」を実施していることがあり、これは懸念事項となるべきです。
- 害の予防:AIシステムは身体的、精神的、感情的な害を引き起こしてはなりません。AIの普及と急速な影響を考えると、AIの出力は市民、従業員、企業、消費者、政府が「力や情報の非対称性によって」[2]誤って操作されることを防ぐために、注意深く監視される必要があります。自律車メーカーがAIトロリープロブレムとして知られる問題に取り組んでいるのを見たことがあります。もちろん、これはロボットシステムに限定されるものではありません。ChatGPTに医療アドバイスを求める人々がいるため、事実を作り上げる傾向があるため、注意が必要です。
- 公正さ:AIシステムは偏見を持たず、差別的ではなく、「利益と費用の均等な分配」[3]を目指すべきです。公正さは人間の選択が損なわれないことを意味し、「AIの開発者は、手段と目的の間の相当性の原則を尊重しながら、競合する利益と目的をバランスさせるべきです。」[4]表面上は簡単に思えるかもしれませんが、公正さの数学的定義は20以上存在することを知っていますか?[5]
- 説明可能性:AIシステムは透明で、監査可能で、再現可能で、解釈可能である必要があります。AIがあなたに影響を与える何かを決定するために使用される場合、その決定がアルゴリズムによってどのように行われたかについての説明の権利を持っています。例えば、クレジットが拒否された場合、そのAIシステムの運営者は、その決定に寄与したすべての要因を提供できる必要があります。これは、「ブラックボックス」モデルが使用される場合に問題となることがあります。これは、多くのLLMの基盤となっているニューラルネットワークや一般的な敵対的ネットワーク(GAN)のようなものです。
これにより、7つの要件が導き出されます:
- 人間の代理権と監視:基本的に、この要件はAIシステムが人権を尊重し、完全に自律的には動作しないことを述べています。AIは人間の意思決定を補完し、置き換えるのではなく、人間の意思決定をサポートするべきです。 AIの意思決定に異議を唱えるプロセスが必要であり、必要な場合には人間がAIの意思決定を上書きできるようにする必要があります。これは良いことのように聞こえますが、何百、何千もの意思決定が自動的に行われる場合、すべてを効果的に追跡して問題が起こらないようにするにはどうすればよいのでしょうか?
- 技術の堅牢性と安全性:AIシステムは、悪意のある行為者やサイバー攻撃に対して安全で堅牢であり、耐性を持つ必要があります。信頼性があり再現性のある正確な予測を提供する必要があります。組織はサイバーセキュリティを優先し、攻撃やシステムのオフライン時の運用に備えた緊急事態対応計画を持っている必要があります。また、悪意のある行為者がトレーニングデータを変更して正しい予測を引き起こす敵対的データ汚染に特に注意を払う必要があります。
- プライバシーとガバナンス:「AIシステムは、システムの全生命周期を通じてプライバシーとデータ保護を保証しなければならない。」[6] AIシステムの開発者は、悪意のあるデータやコードがシステムに供給されるのを防ぐために保護策を講じる必要があります。ガイドラインはまた、個人のデータには認可されたユーザーのみがアクセスできることを強調しており、そのデータは公平で偏りのないものであり、生命周期全体ですべてのプライバシー規制に従う必要があります。組織が考えなければならない問題の一つは、「認可されたユーザー」とは何を意味するのかということですか?Roombaが便器で女性の写真を撮ってFacebookに投稿された事件を見ましたか?
- 透明性:組織はデータの系統を追跡できる必要があり、そのソース、収集方法、変換方法、使用方法を理解する必要があります。このプロセスは監査可能であり、AIの出力結果は説明可能であるべきです。これはデータサイエンティストにとって課題となる要件です。なぜなら、説明可能なモデルはしばしば「ブラックボックス」アルゴリズムよりも正確性が低い場合があるからです。この要件はまた、AIと対話している人々がそれを意識していることを認識するべきであり、つまり、AIが人間であるかのように振る舞ってはならず、私たちがボットと対話していることが明確であるべきです。
- 多様性、非差別性、公正さ:AIはすべてのグループを平等に扱うべきですが、それは言うほど簡単ではありません。この要件は、異なる文化、経験、背景を持つ人々をデザイナーに含めることで、多くの文化に蔓延する歴史的な偏見を軽減するのに役立つと示唆しています。AIは障害やその他の要因に関係なく、誰にでも利用可能であるべきです。では、「グループ」とは何を定義するのでしょうか?明らかな保護されるクラス、年齢、人種、色、地域/信条、国籍、性別、年齢、身体または精神の障害または退役軍人の地位があります。考慮すべき他の要因はありますか?もし私が保険会社だった場合、「健康的な」習慣を持つ人々に対して「非健康的な」人々よりも低い料金を請求することはできるのでしょうか?
- 社会的および環境的な幸福:AIシステムは社会の改善、民主主義の促進、環境にやさしい持続可能なシステムの構築を目指すべきです。何かを行うことができるからといって、必ずしも行うべきとは限りません。ビジネスリーダーはAIの潜在的な社会的影響を批判的に考慮する必要があります。AIモデルのトレーニングにかかるコストは何ですか?それらは環境、社会、企業のガバナンス(ESG)方針と矛盾していますか?すでに、TikTokなどのソーシャルメディアプラットフォームが有害なコンテンツを子供たちに推進している例を見ています。
- 責任:AIシステムの設計者は、システムに関連する人々が不公平な意思決定を修正し、訂正できる方法を提供するため、そのシステムに責任を持つべきです。設計者は個人やグループに対して与える害に対して責任を負う場合があります。これは興味深い問題を提起します – システムが暴走した場合、誰が責任を負うのでしょうか?基礎モデルの提供者なのか、生成型AIを使用している企業なのか?
これらの原則は表面的には直感的に思えるかもしれませんが、「これらの原則の解釈方法、なぜそれらが重要であるか、どの問題、領域、または関係者に関連しているか、およびそれらをどのように実装するかに関して、実質的な相違があります。」[7]
LLMのためのAI倫理の考慮事項
EUのAI倫理ガイドラインを理解したので、LLMに対する独自の考慮事項について掘り下げましょう。
以前のブログ記事「GenAIOps:MLOpsフレームワークの進化」で、生成型AIとLLMの3つの主要な機能について説明しました:
● コンテンツ生成:生成型AIは、テキスト、音声、画像/ビデオ、さらにはソフトウェアコードなど、人間のような品質のコンテンツを生成することができます。ただし、生成されたコンテンツが事実に基づいているか、誤解を招かないかは、エンドユーザーの責任になります。開発者は生成されたコードがバグやウイルスから解放されていることを確認する必要があります。
● コンテンツ要約と個別化: 大量のドキュメントを選別し、内容を素早く要約する能力は、生成型AIの強みです。ドキュメント、メール、Slackメッセージの要約を素早く作成するだけでなく、生成型AIはこれらの要約を特定の個人やパーソナに合わせて個別化することもできます。
● コンテンツの発見とQ&A: 多くの組織は、さまざまなデータシロに散在する大量のコンテンツとデータを持っています。多くのデータ分析ベンダーは、LLMと生成型AIを使用して、自動的に異なるソースを発見し結びつけることができます。エンドユーザーは、自然な言葉でこのデータにクエリを投げることで、主要なポイントを理解し、詳細を掘り下げることができます。
これらのさまざまな機能を考慮すると、AI倫理フレームワークを作成する際にはどのような要素を考慮する必要があるでしょうか?
人間の主体性と監視
生成型AIは基本的に自律的にコンテンツを生成するため、人間の関与と監視が減少するリスクがあります。例えば、1日にどれだけの迷惑メールを受け取りますか?マーケティングチームがこれらのメールを作成し、マーケティング自動化システムに読み込んで「実行」ボタンを押します。これらはオートパイロットで実行され、しばしば忘れられて永遠に実行されます。
生成型AIがテキスト、画像、音声、動画、ソフトウェアコードを瞬時に生成できることを考えると、重要なアプリケーションにおいて特に人間が関与する仕組みをどのように確立できるでしょうか?医療アドバイスや法律アドバイスなど、より「敏感な」タイプのコンテンツを自動化する場合、組織はこれらのシステムに対して自身の主体性と監視を維持する方法について重要な考慮をする必要があります。企業は、意図や価値観と一致する意思決定が行われるようにするための保護策を講じる必要があります。
技術的な堅牢性と安全性
生成型AIモデルは、予想外または有害なコンテンツを作成することがあることはよく知られています。企業は、信頼性と安全性を確保するために、生成型AIモデルを厳密にテストして検証する必要があります。また、生成されたコンテンツに誤りがある場合、その出力を処理して修正する仕組みを設ける必要があります。インターネットはひどい分裂をもたらすコンテンツで溢れており、一部の企業は疑わしいコンテンツをレビューするためにコンテンツモデレータを雇っていますが、これは不可能な仕事のように思えます。最近では、このようなコンテンツが心の健康に非常に悪影響を与えることが報告されています(AP News – Facebook content moderators in Kenya call the work ‘torture.’ Their lawsuit may ripple worldwide.)
プライバシーとガバナンス
生成型AIモデルは、インターネット全体から収集されたデータで訓練されています。多くのLLMメーカーは、モデルの訓練に使用されたデータの詳細を実際には公開していません。では、生成型AIが実在の個人データまたは機密データを含むまたは類似した出力を生成した場合はどうでしょうか?TechCrunchによれば、Samsungは誤って独自のデータを漏洩させた後、ChatGPTのような生成型AIツールの使用を禁止しました。Bloomberg Lawによると、OpenAIは最近、ChatGPTの幻覚に関連して名誉毀損の訴訟を受けました。
企業は、生成型AIモデルの訓練に使用されるデータソースについて詳細な理解を持つ必要があります。独自のデータを使用してモデルを微調整し、適切に匿名化することができます。ただし、基礎モデルの提供元がモデル訓練に不適切なデータを使用した場合、責任は誰にあるのでしょうか?
透明性
「ブラックボックス」モデルは解釈が難しい性質を持っています。実際には、これらのLLMは数十億のパラメータを持っているため、解釈可能ではないと言えます。企業は透明性を追求し、モデルの動作方法、制約、リスク、およびモデルの訓練に使用されたデータに関するドキュメントを作成するべきです。ただし、これは言うのは簡単ですが、実行するのは難しいです。
多様性、非差別性、公平性
前述のように、適切に訓練されずに考慮されない場合、生成型AIは偏ったまたは差別的な出力を生成する可能性があります。企業は、データが多様で代表的であることを確認するために最善を尽くすことができますが、これはLLMプロバイダーの多くが訓練に使用されたデータを開示していないため、大変な作業です。訓練データの理解、リスクと制約の把握に最大限の注意を払うだけでなく、企業は有害なコンテンツを検出し、配信を阻止し、必要に応じて修正するための監視システムとメカニズムを設ける必要があります。
社会と環境の福祉
ESGイニシアチブを持つ企業にとって、LLMのトレーニングは膨大な計算リソースを消費します。つまり、かなりの電力を使用します。生成型AIの能力を展開する際には、組織は環境への影響を考慮し、軽減策を模索する必要があります。モデルのサイズを縮小し、トレーニングプロセスを加速する方法を研究している研究者もいます。この領域が進展するにつれて、企業は少なくとも年次報告書で環境への影響を考慮すべきです。
責任
生成型AIが有害または誤解を招くコンテンツを生成した場合、誰が責任を負うのでしょうか?誰が法的責任を負うのでしょうか?米国の裁判所で審理中のいくつかの訴訟が、今後の訴訟の舞台となるでしょう。有害なコンテンツに加えて、LLMが派生作品を生成した場合はどうでしょうか?LLMは著作権や法的に保護された資料で訓練されたのでしょうか?データの派生物を生成した場合、裁判所はこれをどのように取り扱うのでしょうか?企業が生成型AIの能力を実装する際には、状況を是正するための対策を講じるための制御とフィードバックメカニズムを設けるべきです。
まとめ
生成型AIは世界での業務の進化において非常に大きな可能性を秘めていますが、その急速な進化には多くの倫理的ジレンマが存在します。企業が生成型AIの領域に進出する際には、確立された倫理的ガイドラインを深く理解しながら実装を進めることが重要です。これにより、組織は倫理基準を維持し、潜在的な落とし穴や害から身を守りながら、AIの変革力を活かすことができます。
[1] European Commission. 2021. “Ethics Guidelines for Trustworthy AI | Shaping Europe’s Digital Future.” Digital-Strategy.ec.europa.eu. March 8, 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[2] European Commission. 2021. “Ethics Guidelines for Trustworthy AI | Shaping Europe’s Digital Future.” Digital-Strategy.ec.europa.eu. March 8, 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[3] European Commission. 2021. “Ethics Guidelines for Trustworthy AI | Shaping Europe’s Digital Future.” Digital-Strategy.ec.europa.eu. March 8, 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[4] European Commission. 2021. “Ethics Guidelines for Trustworthy AI | Shaping Europe’s Digital Future.” Digital-Strategy.ec.europa.eu. March 8, 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[5] Verma, Sahil, and Julia Rubin. 2018. “Fairness Definitions Explained.” Proceedings of the International Workshop on Software Fairness — FairWare ’18. https://doi.org/10.1145/3194770.3194776.
[6] European Commission. 2021. “Ethics Guidelines for Trustworthy AI | Shaping Europe’s Digital Future.” Digital-Strategy.ec.europa.eu. March 8, 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[7] Jobin, Anna, Marcello Ienca, and Effy Vayena. 2019. “The Global Landscape of AI Ethics Guidelines.” Nature Machine Intelligence 1 (9): 389–99. https://doi.org/10.1038/s42256-019-0088-2.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





