現代のNLP:詳細な概要パート2:GPT
現代のNLP GPTの詳細な概要パート2
シリーズの最初の部分では、Transformerが自然言語処理と理解のシーケンスツーシーケンスモデリング時代を終わらせたことについて話しました。この記事では、最も強力な生成的NLPツールであるOpenAIのGPTの開発に焦点を当て、その道筋に沿った特定の進展も見ていきます。
トランスフォーマー以降のNLP領域の進化
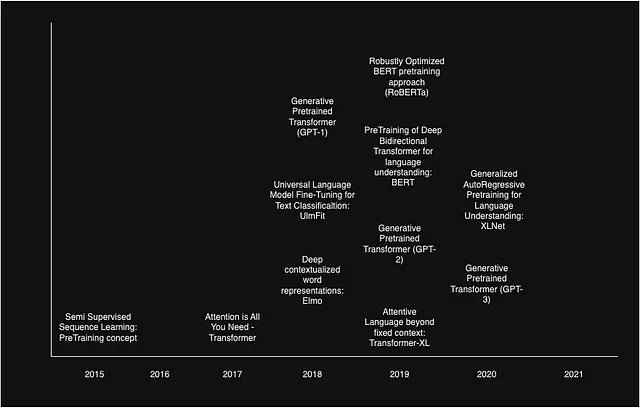
始める前に、NLP領域で大きな進展をもたらした作品のタイムラインを見てみましょう。これにより、以前の作品の進展が今後の開発にどのように影響を与えたかをよりよく理解し、それらの相互依存関係に対処するのに役立ちます。
生成的事前学習トランスフォーマー(GPT)
2018年、OpenAIはGPTを導入しました。これは、事前学習、転移学習、適切な微調整を実装することで、トランスフォーマーが最先端のパフォーマンスを実現できることを示しました。それ以来、OpenAIはモデルのパワーやパラメーターを増やし、トレーニングデータを改善する取り組みを行い、ChatGPT、InstructGPT、AutoGPTなどの現代のツールが生まれました。
しかし、問題は、これらの概念がどのように結びついたのかということです。ステップバイステップで見てみましょう。
半教師付きシーケンス学習
皆さんもご存知のように、教師あり学習には欠点があり、適切な文脈と単語の埋め込みをモデルに与えるためには膨大なラベル付きデータセットが必要です。NLP領域では、モデルをトレーニングするための大量のデータを入手することが課題でした。2015年、GoogleのAndrew M. Daiが「半教師付きシーケンス学習」という論文を発表しました。この論文では、DBPediaの抽出データ、IMDB、Rotten-tomatoのレビュー、未公開の原稿など、さまざまなドキュメントでモデルを事前学習する非教示的なアプローチが提案されました。この事前学習により、モデルは単語の理解をより高めることが観察されました。

最終的に、モデルを特定のタスクに微調整しました。これは教師ありのタスクであり、学習が安定し、収束が速くなることがわかりました。したがって、半教師付きのプロセス全体としては素晴らしい結果が得られました。
著者は、予測に対して通常のRNNよりも良い結果をもたらすと証明されているクリッピング勾配法を使用して基本的なLSTMを使用しました。次に、著者は2つの事前学習手法を使用しました。
- モデルにシーケンスが渡され、次の単語を予測するようにトレーニングされました。これはLM-LSTM、または言語モデリングモデルと呼ばれています。
- モデルにシーケンスが渡され、それから単一のベクトルが作成されます。このベクトルはモデルのデコーダによって使用され、全体の文を再構築します。これはSA-LSTM、またはシーケンスオートエンコーダモデルと呼ばれています。
後に、これらの事前学習済みモデルは、感情分析などのタスクに対して微調整が行われ、最先端のパフォーマンスを上回ることがわかりました。他の結果は次のとおりです。
- 事前学習により、学習の安定性とモデルの汎化能力が向上しました。
- より多くのデータを追加することでさらに改善が見られました。
- LM-LSTMが次の単語のみを予測するのに対して、SA-LSTMは文全体の長い文脈を考慮する必要があったため、より良いパフォーマンスを発揮しました。
論文リンク: https://arxiv.org/pdf/1511.01432.pdf
重要な結論: 事前学習はパフォーマンスを向上させます。
長いシーケンスの要約によるWikipediaの生成
この研究は、2019年にGoogleのPeter J Liuによって発表されました。著者たちは、元のトランスフォーマーアーキテクチャのデコーダ部分のみを使用することで、要約などの生成タスクにおいて最先端のパフォーマンスが達成できると提案しました。このアーキテクチャは自己回帰的な構造であり、つまりモデルは一度に1つの単語を生成し、予測された単語と連結されたシーケンスを受け取って次の単語を予測します。基本的には、前の単語の文脈で単語を予測します。
著者らは、タスクのソースドキュメントとして複数のWikipedia文書を使用し、提案されたアーキテクチャのパフォーマンスを検証するために強力なRNNおよびトランスフォーマーエンコーダデコーダのベースラインモデルを使用しました。
複数のソースドキュメントを使用したため、重複が発生し、巨大なセットが生成されました。しかし、処理能力の不足のためにモデルをトレーニングすることは不可能でした。そのため、著者らは人間と同様の2段階のプロセスを使用しました。
ステップ1:異なる記事からポイントを抽出して有用な情報のセットを作成します。これには、tf-idfやtext-rankアルゴリズムなどの抽出型要約手法が使用されました。著者らは5つの抽出手法を使用し、最も優れたパフォーマンスを発揮した手法を選択しました。
ステップ2:ステップ1で選択されたポイントを、抽象的な要約手法またはディープラーニング手法(この場合はトランスフォーマーのデコーダ)を使用して実際に要約することです。
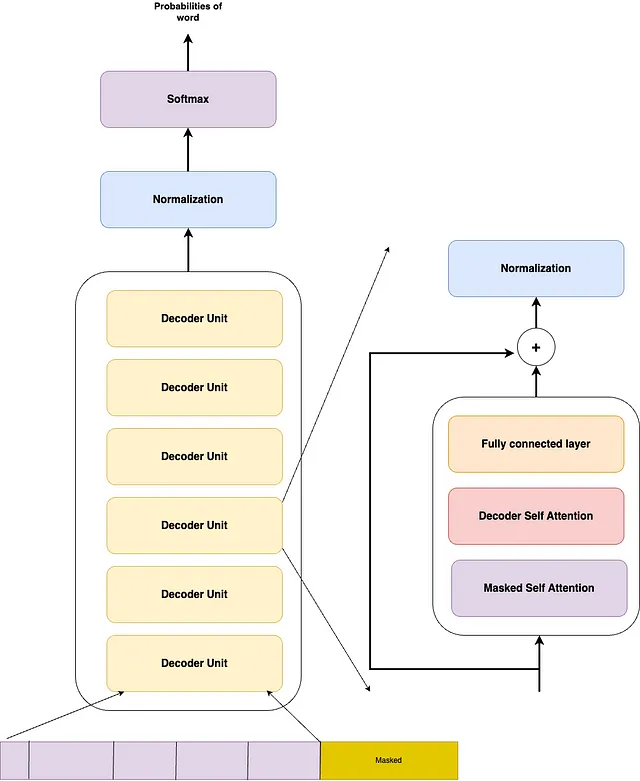
アーキテクチャは実際のトランスフォーマーで見たものと同じです。マスク付きのアテンションブロック、セルフアテンションブロック、完全に接続された層の順に続きますが、エンコーダブロックは削除されています。文とその結果は1つのベクトルに連結され、モデルに渡されてトレーニングされます。デコーダ層は隠れベクトルを作成し、そのベクトルをワード予測のためのソフトマックス層に渡します。
論文リンク:https://arxiv.org/pdf/1801.10198.pdf
重要な結論:デコーダは生成タスクには十分です。
テキスト分類のためのユニバーサル言語モデルの微調整:UlmFit
この研究は、Fast AIのJeremy Howardによって2018年に発表されました。これは、現在私たちが見ているすべてのNLPモデルを強化する、この世界での主要な開発となりました。著者たちは、自然言語処理、理解、推論の世界での転移学習の考え方を導入しました。
コンピュータビジョンの世界に精通している人々は、転移学習という概念についてある程度の理解があるでしょう。したがって、同等のものを見つけるために少しコンピュータビジョンの世界にシフトする必要があります。
教師あり学習は、超深層モデルをトレーニングするために画像処理のための巨大なデータセットが必要であり、データの不足が問題となりました。この時点で、ImageNetやMS-COCOなどのデータセットが登場し、これらのモデルをトレーニングするのに十分なデータが提供されました。モデルがトレーニングされると、オブジェクトの境界検出、色や勾配の検出などについて良い一般的なアイデアを持っていることがわかりました。したがって、これらのモデルは異なるソースタスクでトレーニングされたものですが、トレーニング済みモデルを使用し、最終的な分類層を変更して他のタスクに簡単に微調整することができます。これらの一般化されたモデルは、データが不足しているタスクにおいて優れた結果を得るのに役立ちました。
ここで、NLPの世界に戻ると、モデルは主にタスク固有のトレーニングが行われていたため、データが少ない場合には対処のしようがありませんでした。一般化の要件が浮上しました。転移学習の概念が以前に試されたことはありましたが、成功しなかったのですが、それが救世主が現れました。著者たちは、いわゆるダウンストリームタスク(データの利用可能性が少なく、事前にトレーニングされたモデルを適切に微調整する必要があるタスク)のための解決策を見つけました。
著者たちは、これまでの失敗の理由を、モデルの微調整方法の不足と、言語モデリングなどの目的で見つかった事前トレーニング済みの重みを使用してモデルを初期化することの良い影響を認識しながら、挙げています。以前の研究では、モデルの微調整にはラベル付きデータがあまりにも多く必要とされ、使用性に影響を与えました。研究者たちがより小さなデータセットを使用してトレーニングしようとした場合、データの不足のためにデータセットにオーバーフィッティングが生じ、結果としてモデルの一般化の喪失や忘却が生じ、最終的には発散してしまいました。
著者らは、最も優れたパフォーマンスを発揮するために、事前学習済みモデルをトレーニングして微調整するための3つのステップの方法を提案しています。この主張を証明するために、著者らは通常の3層LSTMモデルを使用し、サンプル効率性を証明するために100個のラベル付きIMDBレビューの短いデータセットを使用して微調整を行いました。

以下にステップを見てみましょう:
- LMの事前学習:言語モデルの事前学習は、28,595の前処理されたWikipedia記事と1億3,000万語から成るWikitext-103(Merity et al., 2017b)で行われました。著者らは、これがImageNetとサイズの面で比較可能なデータセットであり、良い事前学習モデルを作成するのに十分なものであると提案しています。
- LMの微調整:著者らは、事前学習は良い初期化重みと一般化された単語意味を見つけるための良い方法であるが、ドメイン固有のタスクを扱うためには、モデルを最初に対象ドメインの語彙で微調整する必要があると述べています。一般的なドメインとターゲットタスクの特定のドメインでは、単語の分布が異なる可能性があるためです。ただし、この段階では必要な分類器レイヤーでモデルを微調整していないことに注意してください。単にドメイン固有のデータセットで同じ言語モデリングタスクを行い、単語の分布を適切にシフトさせるだけです。ただし、ここでの注意点は、モデルを単純に微調整することはできないということです。過学習のリスクがあるためです。a. 識別的微調整:モデルの異なるレイヤーは、異なるレベルのデータを捉えることがわかっています。微調整のために、モデルのすべてのレイヤーを同じ学習率でトレーニングしようとすると、過学習を引き起こす可能性があります。その代わり、著者は、モデルの異なるレイヤーを異なるレートでトレーニングすることを提案しています。SGDにおける通常のバックプロパゲーションの方程式は次のようになります。
θt = θ(t−1) − η · ∇θJ(θ)
ここで、θはモデルの重みを表し、ηは学習率、tは時間ステップを示します。著者らは、モデルのレイヤーをレベル0からLまで分け、モデルパラメーターθlと学習率ηlをl番目のレイヤーの学習率として定義します。新しい方程式は次のようになります。
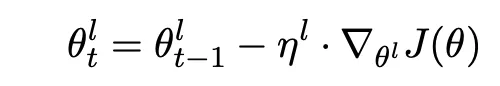
通常、(l-1)レイヤーの学習率は、l番目のレイヤーの学習率を2.6で割ったものです。
b. 傾斜三角形の学習率:レイヤーの一定の学習率は、学習の収束に影響を与えることが観察されました。この問題を解決するために、著者らは傾斜三角形の学習率を提案しています。これにより、モデルの特定のレイヤーはすべてのトレーニングエポックで一定の学習率でトレーニングされるべきではありません。代わりに、学習率は急速に増加し、最高値に達した後、徐々に減少するべきです。
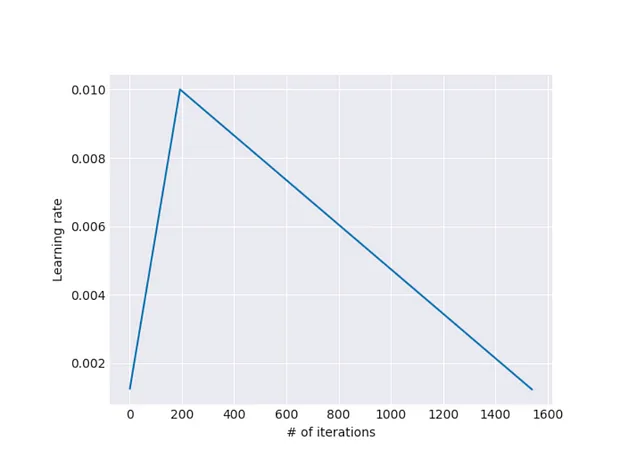
この場合、学習率は反復回数の関数です。
3. 分類器の微調整:これが最後のステップで、拡張されたモデルを取り、ターゲットタスクに基づいてトレーニングするための分類器を追加します。著者らは、CVの手法を借りて、バッチ正規化とソフトマックスのレイヤーを追加しました。著者らは、より高いパフォーマンスを実現するために2つの方法を使用しました:
a. 連結プーリング:分類タスクでは、最も影響力のある単語を使用することが多いことが観察されています。例えば、感情分析では、bestやgoodのような単語はほとんど肯定的な感情を伝えることをほぼ確定させます。これらの単語はドキュメントのどこにでも現れる可能性があり、したがって隠れた状態表現のどこにでも存在する可能性があります。著者らは、影響力のある単語に焦点を当てるために、最大プーリングと平均プーリングの両方を追加しました。最終的な隠れた層の出力は、隠れた層の出力、その最大プールされたバージョン、および平均プールされたバージョンの連結です。レイヤーの出力表現は情報の損失を防ぎ、プールされたバージョンは影響力のある単語に焦点を当てます。
b. Gradual Unfreezing: 著者は観察した結果、すべての層を最初からアンフリーズして一緒に訓練すると、忘却効果が生じることがあります。最後の層がより一般的な理解を持つために最適である可能性があります。これを処理するために、段階的なアンフリーズが導入されています。最後の層を最初にアンフリーズして訓練し、一定のエポック数後に前の層をアンフリーズしていくなど、すべての層を微調整するまで続けます。
論文リンク: https://arxiv.org/pdf/1801.06146.pdf
重要な結論: モデルは、異なる訓練タスクで訓練されていても、ターゲットタスクに微調整できる。
そして最後に、
Generative Pre-Trainingによる言語理解の向上
GPT、またはGenerative Pre-trained Transformerは、2018年にOpenAIのAlec Radfordによって発表されました。この研究は、前の開発のすべての知見を巧妙に最適化し、大規模なパラメータ化モデルと厳選された訓練データと組み合わせることで、大幅な性能向上を実現しました。
GPTの目的は、少しの適応で広範なタスクに転送可能な普遍的な表現を学ぶことです。これは、他のトランスフォーマーデコーダーベースの自己回帰モデルであり、2段階の方法を使用して訓練されました。最初のステップは非教示的な事前訓練フェーズであり、その後タスク固有の微調整が行われます。著者は、より良い性能を実現するために、ULMFitが提案した方法を使用してモデルを微調整しました。
- 事前訓練:
著者は、事前訓練ドキュメントシーケンスを長い単一のベクトルシーケンスに分割し、言語モデリングの目的で事前訓練を行いました。シーケンスの長さは、処理能力がサポートする限り最大化され、長いシーケンスを使用することでモデルが長期依存関係を処理するようになると主張しています。また、著者は事前訓練中にPOSタグ付け、チャンキング、固有表現認識などの補助目標も追加し、これにより教師ありモデルの汎化性能が向上し、収束が加速されました。
2. 微調整:
微調整では、入力と出力を単一のベクトルに接続するトラバーサルモデルが使用されました。生成を必要とするタスクや類似性比較のようなタスクでは、ユニークな区切り文字で区切られた文のペアが連結されます。

テキストの帰結: 帰結タスクでは、前提pと仮説hのトークンシーケンスを区切りトークン($)で連結します。
類似性: 類似性タスクでは、比較される2つの文には固有の順序付けがありません。これを反映するため、入力シーケンスを2つの可能な文の順序付け(区切り文字で区切られた)を含むように変更し、それぞれを独立して処理してから、線形出力層に供給する前に要素ごとに追加します。
質問応答と常識的な推論: これらのタスクでは、文脈ドキュメントz、質問q、および可能な回答セット{ak}が与えられます。ドキュメントコンテキストと質問を可能な回答ごとに連結し、区切りトークンを追加して[z; q; $; ak]を取得します。これらのシーケンスはそれぞれ独立してモデルで処理され、ソフトマックス層を介して正規化されて可能な回答の出力分布が生成されます。
これが微調整の方法です。
モデルの仕様とデータ: 言語モデリングのためにモデルを事前訓練するため、著者はBooksCorpusデータセットを使用しました。これには、アドベンチャー、ファンタジー、ロマンスなどのさまざまなジャンルの7,000以上の未公開の書籍が含まれています。
マスクされた自己注意ヘッド(768次元の状態と12の注意ヘッドを持つ12層のデコーダーのみのトランスフォーマーをトレーニングしました。位置ごとの順送りネットワークには、3072次元の内部状態を使用しました。最大学習率2.5e-4のAdam最適化スキーム[27]を使用しました。
このセクションでは、モデルのアーキテクチャについて説明しています。実際のトランスフォーマーアーキテクチャの知識を持っていれば、論文からの引用ですので不一致を避けるために理解するのは非常に簡単です。
リンク:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
これまでの改良点
これまで、最初のGPTモデルの動作について説明してきました。その後、OpenAIはパフォーマンスを向上させるために取り組んできました。さまざまな調整を行い、ビッグデータの世界の改良を活用しています。
言語モデルは教師なしマルチタスク学習者です
この論文は、OpenAIによって2019年に公開され、GPTの後継モデルであるGPT-2が発表されました。OpenAIは、実際のモデルと比較して論文とより小さなモデルを公開しましたが、モデルの能力を誤用する可能性があるため、実際のモデルは公開されませんでした。
OpenAIは、このモデルの唯一の目的は生成能力の向上であり、つまり次の単語を最適に予測できることを述べています。著者たちは、すべての最先端のモデルが半教師あり学習アプローチを採用しているが、非常に脆弱でターゲットタスクに対して敏感であることに気付きました。つまり、異なるターゲットタスクを訓練すると発散する可能性があります。これを軽減するために、著者たちはより一般的なものを求めていました。著者たちは基本的に、ダウンストリームタスクのためのゼロショット学習の設定を構築したかったのです。これは、ファインチューニングに追加のデータセットが必要なく、完全に教師なしであることを意味します。
マルチタスク学習またはメタ学習は、そのような目標を達成するための安定したフレームワークとして登場したとされています。このトピックに関する研究では、10のデータセットを組み合わせて17のタスクでまずまずのパフォーマンスを達成しました。著者たちは、特定のタスク学習とマルチタスク学習の違いは、モデルが予測する確率であると考えました。特定のタスク学習の場合はP(output/input)ですが、マルチタスク学習の場合はP(output/input, task)であり、異なる場合もあります。さまざまなタスク条件付けの作業からは、モデルが最も優れていることが示されました。つまり、教師なしの事前トレーニングタスクである言語モデリングのグローバルミニマムがファインチューニングの教師ありタスクのグローバルミニマムと一致する場合、最終的な目標は教師なしタスクを最適化し、最良のグローバルミニマムを見つけることでした。抜粋から明らかになったことは、十分に大きなデータセットがあれば、これが実現できるということです。
データセット:著者たちは、同様の作業に使用されるCommon Crawlerというウェブスクレイパーの知見を活用し、WebTextというデータセットを作成するために独自のクローラーを開発しました。このデータセットには、これらの4500万のリンクのテキストサブセットが含まれており、800万のテキストドキュメントがあり、合計で40GBのデータが生成されました。著者たちはBPE(Byte-Pair Encoding)も使用しました。これは、単語レベルと文字レベルのエンコーディングの間に線を引くもので、モデルがあらゆるタイプのデータでトレーニングできるようにします。
モデルの変更:著者たちは、トランスフォーマーデコーダーブロックをわずかに変更して、ブロックの前に正規化層を追加し、ある種のプリアクティベーションとして使用し、最終的なセルフアテンション層の後にもう一つの正規化と残差接続を追加しました。モデル全体で15億のパラメーターを含み、GPT-1モデルの10倍です。
結果:巨大なデータセットでこの巨大なモデルをWikipediaの抜粋などの一般的なデータで事前トレーニングすると、研究者はファインチューニングなしでも生成モデルがかなりうまく機能することを観察しました。これにより、「ゼロショット学習」という概念が生まれました。つまり、モデルはトレーニングに任意のラベル付きデータセットを必要とせずに、それでもパフォーマンスを発揮できるのです。
論文リンク:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
結論
最近、OpenAIはGPT3などを開発しており、マルチタスク学習などのさまざまな概念を使用していますが、これはまた別の話です。この記事では、NLPの世界の進化をGPT-2まで見てきました。次のシリーズの記事でさらなる開発を見ることになるでしょう。
お楽しみに!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





