現代の自然言語処理(NLP):詳細な概要パート1:トランスフォーマー
現代の自然言語処理(NLP)の概要:トランスフォーマー(パート1)

過去の半年間で、BERTやGPTなどのアイデアの導入により、自然言語処理の分野で大きな成果が見られました。この記事では、改善の詳細について段階的に掘り下げ、それらがもたらした進化を見ていきます。
注意はすべてに必要です
2017年、Google BrainsのAshish Vaswani氏とトロント大学の同僚らは、ニューラル言語翻訳や言い換えなどのシーケンス・トゥ・シーケンスのタスクにおいて、LSTMやRNNによる既存のワード単位のアプローチとは異なる、一度にシーケンス全体を扱うアイデアを提案しました。
RNNの既存のアーキテクチャの問題点は以下の通りです:
- TensorFlowモデルのハイパーパラメータ調整にKeras Tunerを使用する
- 「テキスト要約の革新:GPT-2とXLNetトランスフォーマーの探索」
- GPT-エンジニア:あなたの新しいAIコーディングアシスタント
- 長いシーケンスの場合、一度に単語を追加する際に情報を保持するのが難しいという点です。エンコーダ・デコーダの構造を持つモデルでは、RNNとLSTMを使用して隠れベクトルを1つのタイムスタンプから他のタイムスタンプに渡します。そして、最終的なステップで、最終的なコンテキストベクトルをデコーダに渡します。デコーダに渡される隠れコンテキストベクトルは、シーケンスの最初の数単語に比べて、最後の数単語に対してより大きな影響を与えます。つまり、情報は時間とともに薄れてしまいます。
- 第1のポイントで述べた問題を解消するために、アテンションメカニズムが導入されました。これは、デコードする際に、入力シーケンスの単語に個別のアテンションを与えるというものです。入力シーケンスの各単語は、特定のアテンション重みベクトルを取得し、それを単語ベクトルと乗算してベクトルの加重和を作成します。しかし、問題は、これを一度に1ステップずつ行っていたため、計算に時間がかかりすぎることと、情報の損失を完全に解消できなかったことです。
アイデア
Transformersは、セルフアテンションという概念を使用することを提案しました。モデルは一度に文全体を受け取り、セルフアテンションを使用して現在の単語の文脈における他の単語の重要性を判断します。したがって、既存の再帰的なアーキテクチャと比較して、いくつかの利点があります:
- 重みを検出する際にはすべての単語が既にあるため、情報の損失の可能性がなく、また、両方の単語、選択された単語の前の単語と後続する単語を文脈として把握することができます。これは、再帰的な構造(Bi-LSTMの場合を除く)よりも良い文脈を形成するのに役立ちます。
- フルセンテンスを使用できるし、また、文の各単語に対して他のすべての単語の重要性を見つける必要があるため、すべての単語に対して並列に行うことができます。これにより、処理時間を大幅に節約し、処理能力をフルに活用することができます。
セルフアテンション:ビルディングブロック
セルフアテンションメカニズムは、特定の単語に関連する他の単語の重要性を見つけ、それを表すための組み合わせたコンテキストベクトルを作成しようとします。基本的には、文の中の単語を選ぶと、その単語が文の他の単語とどの程度関連しているかを見つけることを意味します。誰もが知っているように、単語は文の文脈を定義し、単語の意味はその文脈に依存することが多いです。これは文の文脈と関連する単語を見つける方法です。
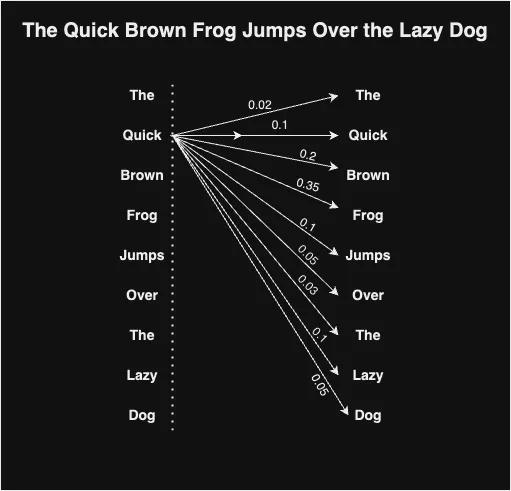
これを実現するために、各入力単語埋め込み(xi)に対して、Query(Qi)、Key(Ki)、Value(Vi)という3つのベクトルを使用します。論文によれば、埋め込みベクトルxの長さは512であることが提案されています。これらのベクトルを得るために、まず3つの重み行列Wq、Wv、およびWkを定義します。各入力単語ベクトルXiを対応する重み行列と乗算して、与えられた単語に対するキー、クエリ、および値のベクトルを得ます。
Qi = Xi * Wq
Vi = Xi * Wv
Ki = Xi * Wk
単語xjの文脈における単語xiの重要性を知るために、単語xiに対応するキーベクトルKiと単語xjのクエリベクトルQjのスカラー内積を求める必要があります。内積の結果は、ベクトルKiの次元の平方根で割られます。ベクトルKiの次元は8であり、論文によって与えられたkの次元は64です。論文で示されているように、割らないと内積の値が大きくなりすぎてしまい、softmaxの値が急激になり、滑らかな学習のための悪い勾配を生成してしまいます。
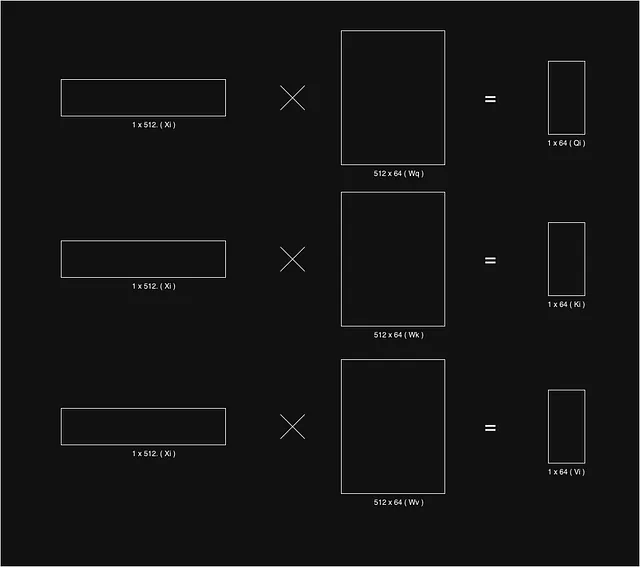
ある単語のすべての単語の重要性を見つけたら、すべての単語の結果に対してsoftmaxを使用します。softmaxは、すべての個々の単語の最終的な重要性を提供し、それらの総和が1になるようにします。次に、単語の値ベクトルViがありますが、これらのベクトルViをそれぞれの重要性と乗算します。直感的には、値ベクトルは単語の表現を作成しますが、重要性要素は主題単語の文脈に重みを与えます。単語が文脈単語と関係がない場合、その重要性値は非常に低くなり、したがって最終的な製品ベクトルは非常に低くなり、タスクに対するその重要性を無視できます。最後に、これらの重み付けられた値ベクトルの合計を取り、アテンションブロックから受け取った特定の単語の最終的な文脈ベクトルを作成します。

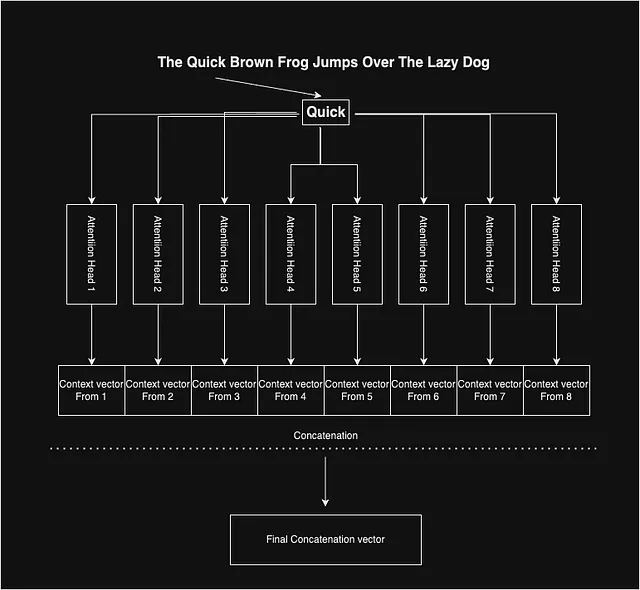
マルチヘッドアテンション
アテンションがどのように機能し、各単語の文脈ベクトルを生成するかを見てきました。論文の著者は、バイアスのない複合文脈ベクトルを得るためにマルチヘッドアテンションを使用しました。彼らは8つのこのようなアテンションヘッドを使用し、単語に対して8つの異なる文脈ベクトルを与えます。アイデアは、内部の重み行列(Wq、Wv、Wk)の各ヘッドの初期化ポイントの変動が、文脈ベクトルのさまざまな特徴を捉えるのに役立つかもしれないということです。
最終的に、各単語には8つの文脈ベクトルがあり、それらを連結して特定の単語の代表的な文脈ベクトルを得ます。
セルフアテンションブロック:全てを結びつける
ここまでの話は文の特定の単語に基づいていますが、文のすべての単語について考え、システムを並列化する必要があります。
論文では、文中の各単語を表すために長さ512の埋め込みを使用することが提案されています。さらに、NLPのタスクでは通常、文の長さを均等にするためにゼロパディングを使用する必要があります。次に、512次元の単語ベクトルをすべて積み重ね、文の中の単語の固定された数があるため、文全体を表すための固定次元の2Dベクトルが得られます。このベクトルは、全体のアテンションメカニズムを通過します。
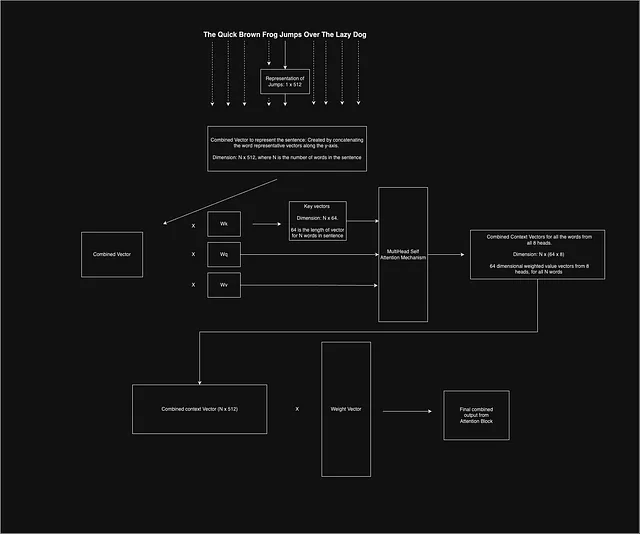
すべての単語の組み合わせた文脈ベクトルを取得したら、別の重み行列で乗算され、学習を集中させ、ベクトルの次元を減らします。
トランスフォーマー:アーキテクチャ
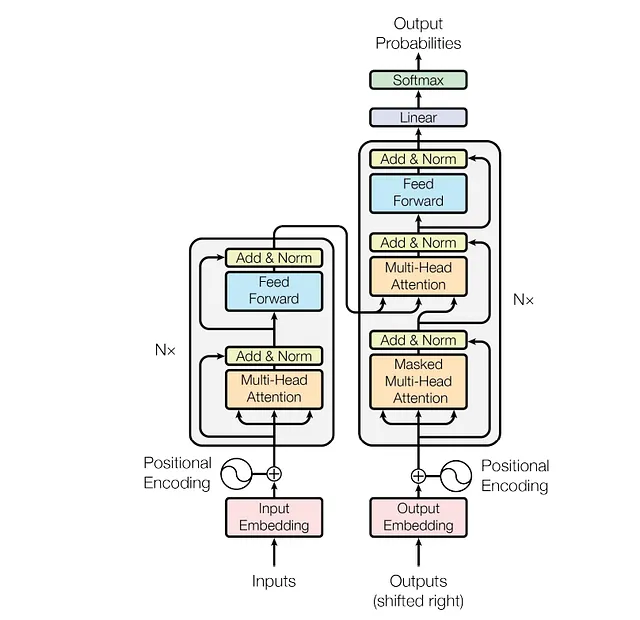
Transformerは、標準的なエンコーダー-デコーダーのアーキテクチャに従います。簡単でより良い学習のために、単語ベクトルの次元とレイヤーの出力はすべて512に保たれています。モデルの学習は自己回帰的に行われます。つまり、単語は1つずつ生成され、(t+1)番目の単語の予測には、t番目の単語の出力を入力に付加してモデルに与えます。
エンコーダー: 著者は2つのサブレイヤーを持つモジュールを使用しています。最初のレイヤーには、前述のマルチヘッドアテンションが含まれており、2番目のサブレイヤーは完全に接続された順伝播レイヤーです。順伝播レイヤーは、2つの通常のニューラルネットワークレイヤーで構成されています。順伝播レイヤーの入力と出力は512次元ですが、内部の次元は2048であり、内部レイヤーのノード数は2048です。完全に接続されたレイヤーはReLU活性化関数を使用しています。著者はまた、学習をスムーズにし、NLPやコンピュータビジョンの場合に見られる情報の損失を避けるために、加算と正規化レイヤーも使用しています。
したがって、方程式は次のようになります。
Output = Norm( x + f(x))、ここでxは入力であり、f()はレイヤーの変換です。変換は順伝播またはアテンションブロックのいずれかであることがあります。
エンコーダーブロックには6つのこのようなモジュールがあります。
デコーダー: これはエンコーダーブロックと非常に似ています。これも6つのモジュールと同様のアーキテクチャを持っています。唯一の違いは、既に存在する2つのサブレイヤーに加えて、デコーダーブロックが3番目のサブレイヤーを導入することで、これもアテンションレイヤーですが、入力はマスクされています。これにより、モデルはt番目の単語を予測する際に(t+1)番目のタイムスタンプの単語を入力として使用することはできません。マスクのないマルチヘッドアテンションサブレイヤーは、対応するレイヤーのエンコーダーから値を受け取ります。したがって、このレイヤーは前のデコーダーレイヤーと対応するエンコーダーレイヤーからの入力を受け取ります。
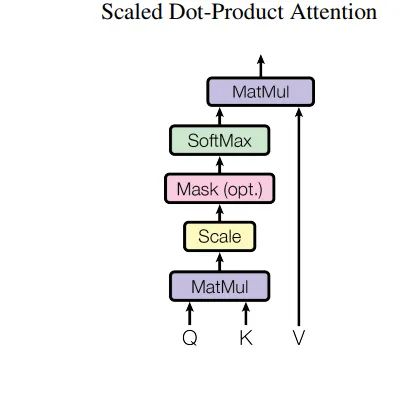
アテンションレイヤーは、著者によれば、トレーニング中にモデルによって3つの異なる方法で使用されています。すでに知っているように、アテンションブロックにはすべての単語のキー、クエリ、および値の3つのベクトルを入力します。著者はこれを使用してモデルをより良く訓練しました。
オプション1: この場合、クエリは前のデコーダーレイヤーから来ており、メモリキーと値はエンコーダーの出力から来ています。これにより、デコーダーの各位置が入力シーケンスのすべての位置にアテンションを向けることができます。

オプション2: この場合、値とクエリはエンコーダーの前のレイヤーの出力から来ます。エンコーダーの各位置は、エンコーダーの前のレイヤーのすべての位置にアテンションを向けることができます。
オプション3: この場合、値とクエリはデコーダーの前のレイヤーの出力から来ます。デコーダーの各位置は、デコーダーの前のレイヤーのすべての位置にアテンションを向けることができます。これによって、マスクされたマルチヘッドアテンションの重要性が浮かび上がります。モデルはt+1の単語を見ることができないため、自己回帰プロパティが保持されます。
最後に、著者は線形変換レイヤーとソフトマックスレイヤーを使用しました。
位置エンコーディング
モデル以外にも、この論文では位置エンコーディングの概念も紹介されています。問題は、この論文では再帰的または畳み込みネットワークを使用せず、時間ステップベースでもないため、単語の位置を示すものが必要だと著者は感じたことです。なぜなら、単語の位置は文の意味を表現する上で重要な役割を果たすからです。
そのために、著者は2つの推定を導入しました。
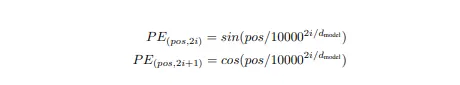
ここでposは単語の位置、iは次元、dmodel = 512は入力次元のサイズです。エンコーディングのサイズも512次元に保たれているため、単語埋め込みに簡単に追加することができます。著者はこれらの特定の関数を選んだ理由は、これらの関数があるオフセット後に同じ値の倍数を与えるため、線形関数として表現できるからです。
結論
私たちはトランスフォーマーの動作方法を学びました。次に、他の進化とそれらの実装についても学びます。
それまで、楽しい読書を!!!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






