現代の自然言語処理(NLP):詳細な概要パート4:最新の展開
現代の自然言語処理(NLP)の最新展開
現在の世界では、Webに接続している人なら誰もがChatGPTというツールの存在を聞いたことがあるでしょう。このツールは世界中で大混乱を巻き起こし、一部の人々は日常生活のさまざまなタスクに使用しようと試みています。多くの人がそれをどんな質問や疑問にも答えることのできる革命として知っています。しかし、ここに到達するまでにどのようになったのか、AIはどのようにしてほとんどの質問や疑問に答えることができるようになったのか、考えたことはありますか?
それでは、少し明かりを当ててみましょう。始める前に、この記事全体で議論する概念は、TransformersやGPT 2などの以前の作品の概念を必要とします。これらの作品に詳しくない場合は、私はこれらのトピックについてすでに話しているので、簡単に目を通してください。
それでは、さっそく始めましょう。
- 「バイオインスパイアードハードウェアシステムのPOEモデル」
- 「NVIDIAは3DワールドのためのOpenUSD標準を設定するためのフォーラムの形成を支援します」
- 「愛らしい3Dクリーチャーが、今週「NVIDIA Studio」で父子コラボレーションによって生み出されました」
この記事では、GPT 3、3.5、およびchatGPTについて話します。GPT3について話し始める前に、GPT3の進化に重要な役割を果たしたOpenAIの別の作品を紹介します。
スパーストランスフォーマで長いシーケンスを生成する
2019年、トランスフォーマが非常に人気を博し、さまざまな作品で使用されるようになってきました。入力コンテキストの長さが増すにつれて、1つの問題が浮かび上がりました。トランスフォーマは入力の全体の長さに対して注意を払うため、必要な時間とメモリの要件が入力の長さの増加に比例して二次的に増加します。時間の複雑性はO(N²)となります。各トークンまたは単語に対してモデルが他のすべての単語に注意を払うため、各単語に対してO(N)、すべての単語に対してN x O(N) = O(N²)となります。これにより、学習がすぐに困難になります。OpenAIはこの論文を2019年にリリースし、この時間の爆発的な問題に対処しました。
このアイデアは、性能を損なうことなく、時間の複雑性をN^(1+ 1/p)(ここでpは1より大きい因子化要素であり、通常p=2となります)に減らすモデリングの変更を導入するというものでした。したがって、最終的にはO(N*sqrt(N))となります。
観察結果:あるトークンに対して注意機構がすべてのピクセルまたは単語に対して注意を払う必要はないことがわかりました(以下の図を参照)。

レイヤーは既に行と列ベースのスパースアテンションを学習し、データ依存のパターンが確立されていました。したがって、著者は、パフォーマンスにあまり影響を与えずに注意行列を構築するために、スパースウェイトカーネルを導入することができると結論付けました。
アイデア:著者は、フルセルフアテンションを2つのステップに分解し、観察結果に基づいて2つの異なるカーネルを使用しました。著者は、画像のアテンションでは一般的に特定のパターンに注意が向けられるが、音声やテキストのような非画像データではカーネルのための固定パターンは存在しないということを発見しました。決定されたカーネルは以下の画像に示す通りです。
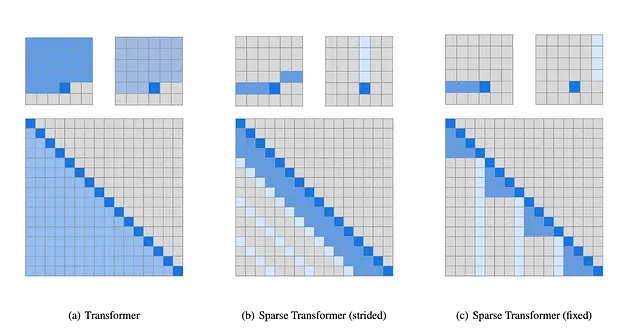
最初の画像(a)は実際のトランスフォーマのセルフアテンションを示しており、1つの出力トークンを生成するためにモデルは出力位置より前に発生するすべてのステップまたはトークンに注意を払います。著者は、実際のセルフアテンションを(b)と(c)の2つの異なるアテンションベースのカーネルに因数分解しました。
(B) ストライドカーネル:この場合、モデルは出力位置の行と列に注意を払います。このタイプは画像ベースの場合に有用です。
(C) 固定カーネル:この場合、モデルは固定された列と最新の列要素以降の要素に注意を払います。このタイプはテキストや音声に有用です。
これらの因子化されたアテンションレイヤーはほぼ同等の結果を提供しましたが、操作時間とメモリ消費量を効果的に削減しました。
スパーストランスフォーマのアーキテクチャ:
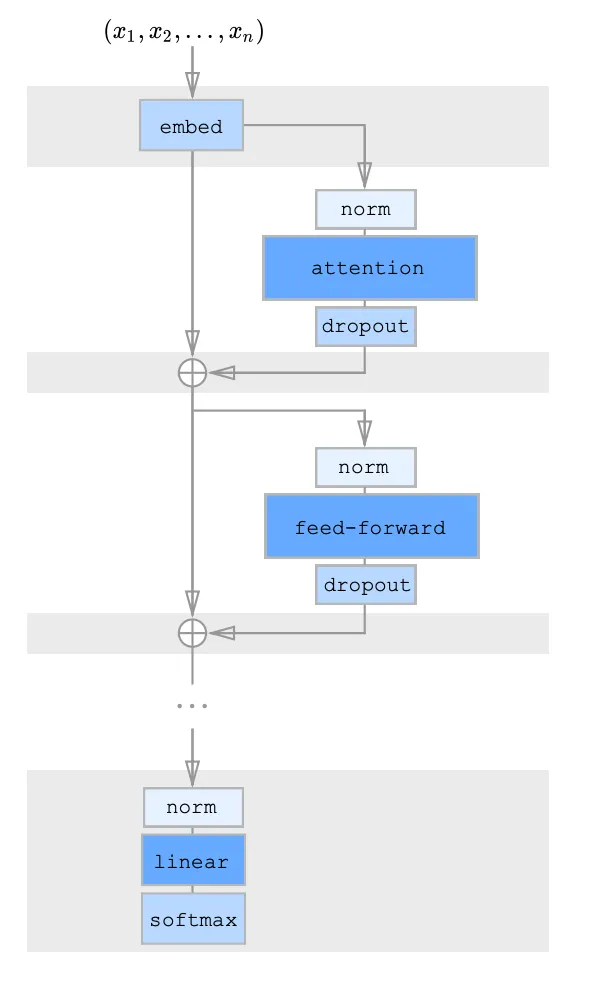
著者は、トランスフォーマーモデルの元のアーキテクチャに対して、因子分解された注意機構を組み合わせるための残差アーキテクチャを導入しました。彼らは3つのアプローチを提案しました:
(1) 各残差ブロックは1種類の因子分解された注意カーネルを持ち、それらを交互に配置します
(2) 注意ヘッドが1つあり、それは両方のカーネルによって指定された位置に共同で注目し、マージドヘッドとして機能します。
(3) 元のアーキテクチャと同様に、複数の注意ヘッドがあり、複数の注意メカニズムが並行して行われ、結果が連結されて最終結果が取得されます。
このアーキテクチャのアイデアは、GPT 3でも使用されています。
論文リンク:https://arxiv.org/pdf/1904.10509.pdf
重要な結論:因子分解された注意と交互の残差構造を使用することで、計算量と時間を劇的に削減しながら効率を維持することができます。
言語モデルは少ないデータ学習者です
この作品はOpenAIによって2020年に発表されました。提案されたモデルは、NLPの世界で最も大きなモデルの1つとして立ちます。この作品によって、今日私たちが楽しんでいるNLPのイノベーションに多くの扉が開かれました。著者たちは、モデルの現状のアプローチについて3つの問題を認識しました。
(1) タスク固有のデータをトレーニングするためには非常に多くのデータが必要ですが、これらの膨大な量のデータを見つけることは時には不可能です。
(2) モデルは、一般化されたモデルとして大量のデータで事前トレーニングされますが、特定のタスクの微調整後には非常に狭い分布に投影されるため、モデルは偏ってしまい、データが少ない場合には過学習やパフォーマンスの低下の可能性があります。
(3) 人間としては、学習するためにあまり多くのデータは必要ありません。一般的には、いくつかのデモンストレーションや時にはプロンプトさえあれば学習できることが多いですが、これは機械にとっては非常に異なるものです。モデルが人間と同様の振る舞いをする必要がある場合、データの問題を解決する必要がありました。
これらの問題を解決するために、著者たちは非常に一般化されたモデルをトレーニングする必要があると理解しました。唯一の方法は、メタラーニングと呼ばれる概念です。
メタラーニング
メタラーニングは機械学習の発展途上の分野であり、モデルに学び方を教えるために使われるため、学び方を学ぶとも呼ばれます。人間は通常の経験からほとんどのことについて事前知識を持っているため、学び方についてのアイデアを持つことができますが、モデルが学習を始めると、データや目標についてのアイデアがないため、これが違いとなります。これはしばしばConditioningと呼ばれ、過去の経験や刺激から学ぶための生き物の性質です。事前知識には3つの主要なタイプがあると言われています。
- 類似性の事前知識
- データの事前知識
- 学習の事前知識
メタラーニングは、モデルが人間のようなことをできるようにするために、モデルを教える計画を立てることを意味します。また、アルゴリズムを完璧にするためにも使用されます。メタラーニングにはいくつかの可能性があります:
(A) 少数データ学習:またはN-Way-K-Shot学習とも呼ばれ、Nクラスと各クラスからのKサンプルがあります。モデルは、これらのデータからサポートセットと呼ばれるデータでトレーニングされますが、学習はクエリセットと呼ばれる別のセットで検証されます。ただし、この場合、バックプロパゲーションは非常に短いサポートセットで行われます。

(B) ワンショット学習:サポートセットには各Nクラスからの1つのサンプルのみが存在し、モデルはクエリセットでのパフォーマンスを行う必要があります。バックプロパゲーションがあります。
(C) ゼロショット学習:サンプルが存在せず、モデルは直接クエリセットでのパフォーマンスを行います。
つまり、事前トレーニングされたデータモデルは、特定のタスクに対して少ないまたはまったくデータを使用して直接実行することができます。事前トレーニングフェーズはメタラーニングフェーズと呼ばれ、特定の学習フェーズはメタラーニングの世界で適応フェーズと呼ばれます。メタラーニングをトレーニングするためには、通常、タスク固有の設定ではなく、さまざまなデータセットとモデルの豊富なセットが使用されます。
メタ学習とアルゴリズムの流れであるメタ学習がありますが、それについては長くなりすぎるので触れません。私はGPT3を理解するために必要な部分に触れただけです。
言語モデルでメタ学習を実装するために、著者たちはインコンテキスト学習と呼ばれる手法を使用しました。この手法についてすぐに見ていきましょう。このアイデアはGPT-2の研究から取られたもので、巨大なデータコーパスで事前にトレーニングされると、モデルはさまざまな依存関係やパターン認識を捉えるスキルを学び、非常に少数のデモンストレーションで新しい特定のタスクに非常に迅速に適応できることが証明されました。
論文リンク: https://arxiv.org/pdf/2004.05439.pdf
https://aclanthology.org/2022.acl-long.53.pdf
それでは、インコンテキスト学習とは何ですか?
インコンテキスト学習
インコンテキスト学習とは、類推から学習することを意味します。これは、私たち人間が学ぶ方法と非常に似ています。通常、人間の学習には3つのケースがあります:
- 「木についての段落を書いてください」というプロンプトが与えられる。
- デモンストレーション付きのプロンプトが与えられる。「合計を見つけてください:1+2=34+5= <予測>」
- 複数のデモンストレーションがあるプロンプトが与えられる。「合計を見つけてください:1+2=34+5= 96+7= <予測>」
インコンテキスト学習は同じように機能します。モデルのコンテキストベクトルにプロンプトまたはデモンストレーション付きのプロンプトを入力し、モデルは予測結果を出力します。この場合、バックプロパゲーションや学習はありません。プロンプトとデモンストレーションを含む全体の入力は、モデルの入力ベクトルとして文字列として入力されます。これは、条件付けに基づいた予測と言えます。
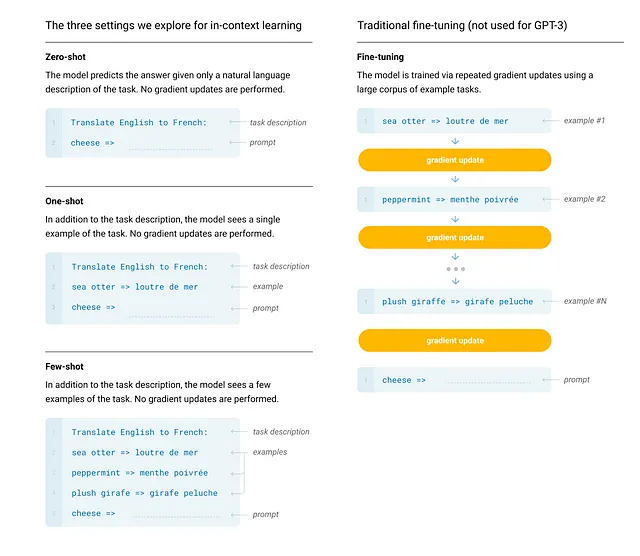
さて、著者はモデルの性能を評価するために4つのケースを定義しました:
- 事前調整:以前のケースと同様に、事前トレーニングの後、モデルはタスク固有のデータで訓練されます。
- フューショット学習:この場合、事前トレーニング済みのモデルに、複数のデモンストレーション付きのプロンプトが与えられます。デモンストレーションの数は、入力ベクトルのコンテキスト長に収まる数になります。モデルはデモンストレーションに基づいて予測を行います。バックプロパゲーションは行われません。
- ワンショット学習:この場合、モデルには1つのデモンストレーションのみを持つプロンプトが与えられます。バックプロパゲーションは行われません。
- ゼロショット学習:この場合、デモンストレーションのないプロンプトのみが提供されます。
GPTモデルのトレーニングの直感は、モデルによるモデルに依存しないメタ学習という非常に一般的なアルゴリズムから取られました。
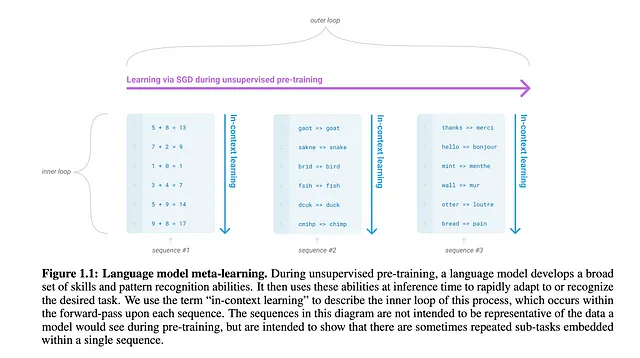
MAMLでは、通常、タスク固有のモデルと一般的なメタラーナーがあり、タスク固有の予測とメタラーナーの予測の間の損失を減らすことを試みます。タスク固有モデルの学習は内部ループと呼ばれ、複数のタスク固有モデルから学習するメタラーナーの重み更新は外部ループと呼ばれます。
この場合、著者は内部ループをインコンテキスト学習と呼びました。これは、事前トレーニングでは、モデルがさまざまなドメイン(サブタスクと呼ばれる)の異なるデータセットを使用してトレーニングされるためです。ドメインに対しては内部ループで学習が行われますが、モデルは外部ループで一般化を学習します。
アーキテクチャ:著者は、GPT-2で使用されたと同じモデルを使用しましたが、スパーストランスフォーマーのための交互の密な注意を使用する修正を加えました。パラメータの範囲が125億から1750億までの8つのモデルが提案され、サイズの影響を評価しました。1750億パラメータを持つモデルはGPT3と呼ばれます。
トレーニングデータ:
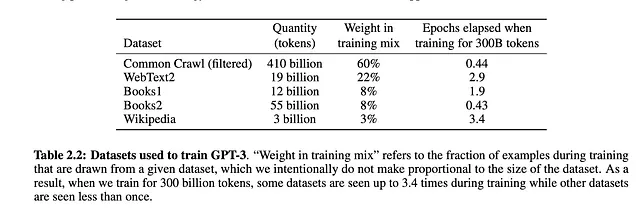
上記の画像は、モデルのトレーニングに使用されるデータセットを説明しています。著者は、データセットから品質が低いデータ、重複、冗長性を除去しました。
なぜインコンテキスト学習は機能するのか? 皆さんの心にある疑問だと思います。モデルはどのようにデモンストレーションだけで出力を生成できるのでしょうか?
多くの研究が行われていますが、その理由はまだ数多くの研究者によって調査されています。私は、StandfordとMeta AIの2つの影響力のある研究結果について話します。
論文リンク:
- Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?: https://aclanthology.org/2022.emnlp-main.759.pdf
- An Explanation of In-context Learning as Implicit Bayesian Inference: https://arxiv.org/pdf/2111.02080.pdf
2つ目の論文では、モデルがどのように機能するかが提案されており、最初の論文ではモデルのパフォーマンスに影響を与える要因について包括的な研究が行われています。どちらの論文も膨大なパラメータサイズの複数のモデルを使用しています。モデルのサイズが増加すると、学習能力とモデルのパフォーマンスも向上することが証明されています。
「An Explanation of In-context Learning as Implicit Bayesian Inference」は、大規模な言語モデルがCommon Crawlerなどのさまざまなデータソースから大量の異なるデータを事前トレーニングすることで、モデルは多数のトピックと言及に出会い、次の単語を予測するために長いデータシーケンスとして提供されます。モデルは注意力を使用し、シーケンスの内部的な推論を理解することを学びます。これにより、モデルはこれらのトピックをパラメータ埋め込み空間に覚えておくことができます。タスク固有の推論中、モデルはデータを取得し、注意力を使って検討し、埋め込み空間で概念を「位置」を特定して答えを見つけます。デモンストレーションとプロンプトは、注意メカニズムがより良いパフォーマンスを発揮し、より良い結果を提供するのに役立ちます。
「Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?」では、GPT3を含む6つのモデルを12つの異なるデータセットで研究しました。以下のことが観察されました:
- デモンストレーションでラベルを変更する(例:ランダムなラベルを提供する)と、モデルのパフォーマンスにほとんど影響がありませんでした。
- 研究者は、入力-ラベルのデモンストレーションの可変数(k)を実験しました。デモンストレーションがある場合、モデルのパフォーマンスは0のデモンストレーションよりも大幅に改善されました(kが小さい場合でも、k=4)。しかし、k≥8以上になるとパフォーマンスの向上は非常に遅くなります。
- 入力形式のテンプレートはパフォーマンスを向上させました。
実験から、インコンテキスト学習がどのように機能し、なぜ機能するのかを示す4つの結論が導かれました:
- 入力-ラベルのマッピング
- 入力の分布
- ラベルセットの分布
- 入力の形式
インコンテキストベースのメタ学習でトレーニングされたGPT3は、フューショット学習の下でプロンプトとデモンストレーションに基づいて人間の行動に近いパフォーマンスを発揮し、翻訳、質問応答、補完などのタスクにおいてSOTAパフォーマンスに匹敵しますが、常識的な推論では一貫した利益を提供できないことがわかりました。
論文リンク:https://arxiv.org/pdf/2005.14165.pdf
次に、GPT 3のアップグレードについて話します。これがChatGPTの誕生につながりました。
ヒューマンフィードバックによる指示の追跡のための言語モデルのトレーニング:InstructGPT
GPT3をリリースした後、OpenAIの研究者たちは、大規模な言語モデルが素晴らしいパフォーマンスを発揮できるとはいえ、必ずしもユーザーの意図に従って動作しているわけではなく、むしろ、GPT3が生成する結果は真実ではなく、有害であり、人々の助けになりません。この状況を改善するために、著者たちは175Bのパラメータを持つGPT3を100倍カットして、1.3Bのパラメータを持つモデルであるGPT3.5またはInstructGPTを作成しました。モデルは、人間の意図により合わせるために、人間のフィードバックを活用して微調整されました。著者たちは、モデルが正直で助けになり、害のない回答を提供することを望んでいました。
モデルをより人間との対話に適したものにするために、著者たちは以前の研究からの手法を導入しました。それは、人間のフィードバックを用いた強化学習を使用するものです。近接方策最適化(PPO)の強化学習手法が使用されました。
InstructGPTモデルをトレーニングするために、著者たちは4つのステップを使用しました。最初のステップは、従来の言語モデリングによる事前トレーニングで、その後に3つのステップが続きます。このステップの後、事前トレーニングされたGPT3モデルから始めました。
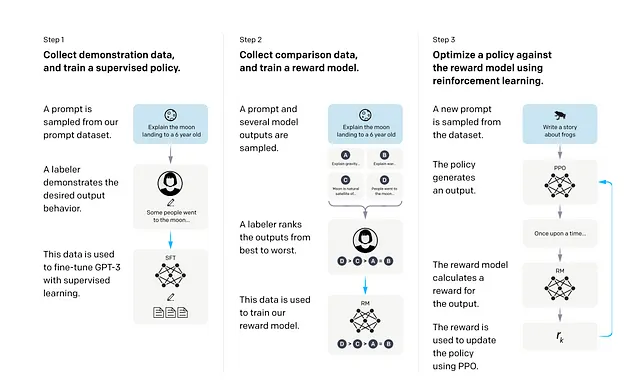
- 最初のステップでは、短い教師あり微調整ステップが含まれていました。著者は事前のGPT3.5ポータルを投稿し、ユーザーはプロンプトとデモを投稿しました。また、OpenAIは40人の契約者を採用し、選考後にいくつかのプロンプトとデモを作成させました。タスクには生成、質問応答、対話、要約、抽出などの自然言語タスクなど、十分な多様性があることを確認し、微調整ステップでの偏りを避けました。また、目的が明確でないタスクのプロンプトは排除しました。事前学習されたGPT3モデルは、このデータでドロップアウト率0.2で16エポック分の微調整を行いました。
- ステップ2では、強化学習のための報酬モデルをトレーニングします。このモデルは最終的なPPOトレーニングフェーズでメインモデルと対話します。生成モデルの場合、同じ入力を与えることで複数の出力を生成する可能性があります。このステップでは、最初のステップで微調整されたモデルに入力を与え、複数の出力を生成し、契約者やラベラーが好ましい出力をマークします。これによりデータセットが作成されます。最終層が削除された微調整済みのGPT3モデルは、プロンプトと回答を受け取り、スカラーの報酬値を生成するように構築されました。ラベラーによって作成されたデータセットを使用して報酬モデルをトレーニングしました。報酬モデルをトレーニングするために、GPT3モデルのサイズを175Bパラメータから6Bパラメータに減らしました。大規模なモデルをトレーニングすることは非常に時間がかかり、時には不安定であることがわかったためです。スカラーの報酬は、モデルが生成した回答の確率からラベラーの好ましい回答への対数オッズの差として定式化されます。つまり、人間のフィードバックメカニズムが導入されています。
- 最後のステップでは、ステップ1から微調整されたモデルの次元を1.3Bパラメータに減らし、バンディット環境でPPO強化学習アルゴリズムを使用して再び微調整します。これは基本的に、モデルにユーザーからの任意のプロンプトが与えられ、モデルが回答を生成します。報酬モデルは回答を受け取り、スカラーの報酬を提供します。トレーニーモデルは報酬モデルに対して報酬を最大化する最適なポリシーを見つけようとします。
結果: InstructGPTは、人間の要件に合わせた振る舞いとパフォーマンスを目標として評価された際に次のような結果が観察されました:
- ラベラーは、GPT-3の出力よりもInstructGPTの出力を大幅に好みます。
- InstructGPTモデルはGPT-3よりも真実性が向上しています
- InstructGPTはGPT-3よりも毒性が少し改善されていますが、バイアスはありません
- InstructGPTは、公開データセットを予測する際に、それをトレーニングした言語モデルを反映しません。
- モデルは、微調整ドメイン外のデータでテストされた際に、原則の一般化をうまく行います。
- InstructGPTはまだ単純なミスをします。例えば、InstructGPTはまだ指示に従わず、事実を捏造したり、簡単な質問に対して長い言い逃れの回答をしたり、偽の前提条件の指示を検出できなかったりすることがあります。
論文リンク:https://arxiv.org/pdf/2203.02155.pdf
ChatGPT
InstructGPTモデルの即時の成功に続いて、OpenAIはInstructGPTモデルをさらに一般的な対話テキストに微調整し、モデルにチャットボットベースの機能を導入しました。これにより、より人間らしく、より優れた対話スキルを持つChatGPTが生まれました。したがって、ChatGPTは特定のタスクに特化したものであり、元のGPT3モデルよりもはるかに小さいです。
結論
ChatGPTは、技術の世界に革新をもたらすツールとして大きな影響を与えました。成功の後、OpenAIはMicrosoftの支援を受けてGPT-4もリリースし、GPTのパワーを画像にも拡張しました。モデルの仕様はセキュリティ上の理由から公開されていません。一方、GoogleもBARDというプロジェクトでチャットボットの世界に参入しました。BARDは、基礎となるLAMDA(Language Models for Dialog Applications)モデルによって強化されています。LAMDAの目標もchatGPTと非常に似ており、人間の要件に合わせた、真実で非毒性な応答を生成するチャットボットの構築です。
論文リンク:
GPT4: https://arxiv.org/pdf/2303.08774.pdf
LAMDA: https://arxiv.org/pdf/2201.08239.pdf
他にも、XLNetやErnieなどの改良があります。テックジャイアンツは、技術的により強い未来を見据え、頻繁な改善を追求しています。
お役に立てれば幸いです。楽しい読書を!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






