なぜ、そして何が特徴エンジニアリングとは何ですか?
特徴エンジニアリングとは何ですか?
機械学習のためのデータ変換と選択
はじめに
機械学習モデルのために改善されたデータを作成するための特徴変換、選択、または抽出のプロセスです。データサイエンスの担当者によってデータの処理と改善が行われ、良いモデルを得るために異なるアプローチがあります。ほとんどの人が特徴エンジニアリングの技術を使用します。この記事では、特徴エンジニアリングのさまざまな技術について説明します。
特徴エンジニアリングには以下の4つのパートがあります:
- 特徴変換
- 特徴構築
- 特徴選択
- 特徴抽出
このPart-1の記事では、特徴変換とその異なる技術について説明します。
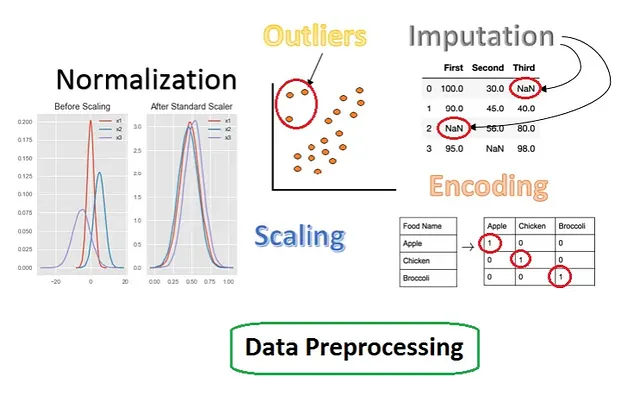
特徴変換
モデルに渡す前のデータの前処理を行うために最もよく使用される方法や技術です。欠損データの補完、スケーリング、エンコーディング、外れ値の検出などのプロセスが含まれます。
スケーリング:
データの値にばらつきがある場合に使用される方法です。例えば、ある入力列の値が非常に低く、他の入力列の値が非常に高い場合、モデルは良いパフォーマンスから外れる可能性があります。大きな値の列がモデルの学習に優先され、他の特徴に対しては重要度が低くなります。
キーポイント:
- トレーニングとテストの分割後にスケーリングを行うことが望ましいです。
- 他の変換後にスケーリングを行うと、より良いモデルのパフォーマンスを得ることができるかもしれません。
スケーリングの種類:
- 標準化:
- このタイプのスケーリングでは、値は平均と標準偏差に収束します。新しく変換されたデータポイントは平均値がゼロで、標準偏差が1になります。
- sklearnのスカラーライブラリを使用すると、新しく変換された列のnumpy配列が返されますが、それらをデータフレームで使用する必要があります。
- どのモデルを適用するかわからない場合に使用します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






