データサイエンスにおける正規分布の適用と使用
正規分布の適用と使用
データサイエンスのステップ
データサイエンスの正規分布のさまざまな応用のレビュー
はじめに
データサイエンスを始める際に非常に困難なことの一つは、その旅がどこで始まりどこで終わるのかを確定することです。データサイエンスの旅の終わりについては、この分野で毎日進歩があり、新しい進歩があることを覚えておくことが重要です。データサイエンスは、科学、統計、プログラミングだけでなく、他の数々の学問から成り立っています。
データサイエンスの圧倒的な性質を最小限に抑えるためには、情報を小分けにして取り入れることが重要です。特定の領域についての研究に没頭し、データ、プログラミング、機械学習、分析、または科学についてより詳しく学ぶことは楽しいことですが、時にはその焦点を絞り、特定のトピックについて可能な限りすべてを学ぶことも素晴らしいことです。初心者にとっては、これらの相互に関連する領域が始めるための疑問の残る場所であるということは理解できます。統計と正規分布は、データサイエンスを始めるには最適な場所だと私は断言します。私はこのことを詳しく説明し、正規分布について詳細に説明した記事を書きました。ここではこの記事の要約を行いますが、詳細は省略されます。
データサイエンス統計の最初の学びどころ – 正規分布
シンプルな正規分布の概要とプログラミング。
chifi.dev
上記のように説明される正規分布は、データに適用できる単純な確率密度関数(PDF)です。この関数は、f と呼ぶことにします。この関数は、f(x) において、平均からの標準偏差 x の数を計算します。考えてみてください。平均からの標準偏差を求めるには、その値が平均からどれだけ離れているかを確認する必要がありますよね?それからその差が何個の標準偏差かを見る必要があります。したがって、この式ではまさにそのことを行っています。したがって、各 x に対して、平均を引き、その差を標準偏差で除算します。統計学では、小文字のシグマ(σ)は標準偏差を表し、小文字のミュー(µ)は平均を表します。以下の式では、x bar(x̄)は観測値を表し、f(x) の中の x です。
- モデルの解釈のマスタリング:パーシャル依存プロットの包括的な解説
- People Analyticsは新しい大きなトレンドであり、それを知っておくべき理由があります
- 学習トランスフォーマーコード入門:パート1 – セットアップ
プログラミング言語への移行
前の記事の最後で、これをプログラミング言語であるJuliaにもっていきました。言語の選択は、完全にデータサイエンティストによって決定されますが、考慮すべきトレードオフもあり、業界の動向も考慮することが重要です。たとえば、Rは比較的遅い言語ですが、優れた開発者によって長年にわたり改良され、メンテナンスされた分析パッケージや優れたダッシュボードツールがあります。今日最も人気のある選択肢は、Cライブラリへの高速な接続と使いやすさのためにおそらくPythonです。Juliaは比較的新しい言語ですが、私のお気に入りのプログラミング言語であり、ほとんどのデータサイエンティストが知っているべき言語です。Juliaは人気が急上昇していますが、両方を知っていれば、より多くの仕事にアクセスできるようになります。幸いにも、データサイエンスによく使用される一般的な言語のほとんどは共通点が多く、互いを参照しやすくなります。以下は、PythonとJulia REPLのそれぞれで書かれた正規分布です。
python
>>> from numpy import mean, std>>> x = [5, 10, 15]>>> normed = [(mean(x) - i) / std(x) for i in x]>>> print(normed)[1.224744871391589, 0.0, -1.224744871391589]julia
julia> using Statistics: std, meanjulia> x = [5, 10, 15]3要素のVector{Int64}: 5 10 15julia> normed = [(mean(x) - i) / std(x) for i in x]3要素のVector{Float64}: 1.0 0.0 -1.0また、各プログラミング言語のノートブックもあります。このチュートリアルを誰にでもアクセス可能にするだけでなく、複数の言語を使って取り組むことを推進するために、これらの言語のノートブックをすべて作成します。これらの言語はかなり似ており、読みやすく、違いを比較すること、好きな言語を見つけること、さらには各言語の詳細なトレードオフを探索することも容易です。
ノートブック
python
Emmetts-DS-NoteBooks/Python3/Applying the normal distribution (py).ipynb at master ·…
さまざまなプロジェクトのランダムなノートブック。アカウントを作成してemmettgb/Emmetts-DS-NoteBooksの開発に貢献してください…
github.com
julia
Emmetts-DS-NoteBooks/Julia/Applying the normal distribution.ipynb at master ·…
さまざまなプロジェクトのランダムなノートブック。アカウントを作成してemmettgb/Emmetts-DS-NoteBooksの開発に貢献してください…
github.com
関数の設定
最初に必要なのは、数値のVectorの平均を求める関数です。これは、平均と標準偏差を取得して、その2つとVectorの各要素を式に代入するだけの簡単なものです。この関数は1つの引数、つまりVectorを取り、正規化されたVectorを返します。そのためにはもちろん平均と標準偏差が必要です。これについては依存関係を使用することもできますが、今日はすべてをゼロから行いますので、以下にPythonとJuliaのシンプルな平均と標準偏差の関数を示します。
# pythonimport math as mtdef mean(x : int): return(sum(x) / len(x))def std(arr : list): m = mean(arr) arr2 = [(i-m) ** 2 for i in arr] m = mean(arr2) m = mt.sqrt(m) return(m)
# juliamean(x::Vector{<:Number}) = sum(x) / length(x)function std(array3::Vector{<:Number}) m = mean(array3) [i = (i-m) ^ 2 for i in array3] m = mean(array3) try m = sqrt(m) catch m = sqrt(Complex(m)) end return(m)end必要な値を取得するいくつかの関数があるので、これらを関数にまとめる必要があります。これは非常に簡単で、上記のメソッドを使用して人口の平均と標準偏差を取得し、各観測値から平均を引き、その差を標準偏差で割るための内包表記を使用します。
# pythondef norm(x : list): mu = mean(x) sigma = std(x) return([(xbar - mu) / sigma for xbar in x])
# juliafunction norm(x::Vector{<:Number}) mu::Number = mean(x) sigma::Number = std(x) [(xbar - mu) / sigma for xbar in x]::Vector{<:Number}endさあ、正規化関数を試してみましょう。これは簡単なテストです。私たちは平均値を知っているベクトルを提供するだけです。なぜなら、ベクトルの平均値はゼロになるはずだからです。したがって、[5, 10, 15]の場合、0は10([5, 10, 15]の平均値)になります。5は約-1.5であり、平均値から1つの標準偏差(この場合、数値2.5と等しい)です。
norm([5, 10, 15])[-1.224744871391589, 0.0, 1.224744871391589]通常、正規分布上の統計的に有意な値は、平均値からほぼ2つの標準偏差離れると認識され始めます。言い換えれば、ほとんどの人が約10インチの身長であり、誰かが20インチの身長である場合、これは平均値から3つの標準偏差離れており、非常に統計的に有意です。
mu = mean([5, 10, 15])sigma = std([5, 10, 15])(15 - mu) / sigma1.5811388300841895(20 - mu) / sigma3.162277660168379分析用の正規分布
Z分布、または正規分布は、データ分析にも多くの応用があります。この分布はテストに使用できますが、T検定などと比べてはあまり一般的ではありません。その理由は、正規分布の裾がかなり短いためです。その結果、分散が既知で大きなサンプルサイズで実行されるテストにしばしば予約されています。例えば、T分布と比較すると、T分布の裾ははるかに長くなります。つまり、統計的な有意性の領域がより長くなるため、検出が容易になります。

このようなテスト、Zテストは、母集団の平均値が統計的に有意に異なるかどうかを検定します。公式も以前のPDFで見た公式と非常に似ているため、ここではあまり新しいことはありません。各観測値を使用する代わりに、xbarを検定したい母集団の平均値を表すように変更します。このテストはZ統計量と呼ばれるものを返します。T統計量と同様に、これは確率値を得るために別の関数にかけられます。一次元の観測値のセットを作成し、そのようなテストをどのように実行するか見てみましょう。
pop = [5, 10, 15, 20, 25, 30]mu = mean(pop)sigma = std(pop)中央からランダムなサンプルを取得してZ統計量を計算します:
xbar = mean(pop[3:5])これを単純に公式に代入します…
(xbar - mu) / sigma0.5976143046671968この新しい数字が私たちのZ統計量です。これらの統計値を確率値に変換するための数学はかなり複雑です。これらのことを支援するための両方の言語にはライブラリがあります。Juliaの場合、HypothesisTestsをお勧めします。Pythonの場合、scipyモジュールをお勧めします。この記事では、オンラインのZ統計量から確率値への変換計算機を使用します。ここに私たちのZ統計量を入れてみましょう:
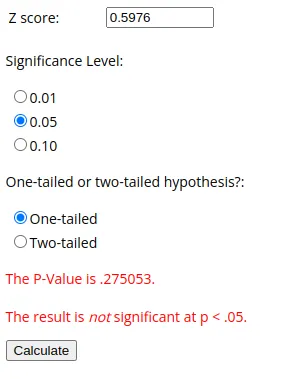
予想通り、私たちの集団の一部は他のサンプルや平均に非常に近い位置にあり、統計的には全く有意ではありません。とは言え、私たちはもちろんより統計的に有意なもので実験して、帰無仮説を棄却することもできます!
xbar = mean([50, 25, 38])(xbar - mu) / sigma4.820755390982054
正規分布はテストには非常に適しています。重要なのは、この形式のテストには大きなサンプルサイズが必要であり、すべてのデータに適用できないということです。初心者には、より簡単にテストできる分布(例:T分布)から始めることをお勧めします。Zテストではデータがより重要になりますが、初心者向けの大量のデータソースを見つけるのは難しいかもしれません。さらに、統計的に有意な結果を得ることもより困難かもしれません。
正規分布はデータサイエンスプロジェクトでクイックな分析にも使用できます。データを集団との関係に変換できる能力は、データの可視化から与えられた集団のばらつき具合を特定するまで、非常に役立ちます。私たちの観測値の平均との関係を調査することで、集団について多くのことを学ぶことができます。このプロセスについて詳しく知りたい場合は、こちらの初心者向けの概要を参照してください。
初心者向けの応用科学入門
特徴と統計分析の基本を学ぶ
towardsdatascience.com
データ正規化のための正規分布
正規分布はデータ正規化にも大いに活用されます。連続した特徴量を崩す要因はいくつかありますが、その中でも最も重要なのは外れ値です。データを一般化するためには、外れ値を取り除く必要があります。優れたデータを構築するための鍵は、優れた集団を構築することです。つまり、データの全体性(平均など)が、ある程度の分散を持つ通常のデータを代表していることが望ましいということです。これにより、何かが異なる場合には非常に明確になります。
正規分布は値が平均からどれだけの偏差を持っているかを示してくれるため、データ正規化に使用できることは容易に理解できるかもしれません。先述の通り、2.0は有意になり始める範囲です。そのため、マスクを作成し、これを使用して不適切な値をフィルタリングすることができます!
# juliafunction drop_outls(vec::Vector{<:Number}) normed = norm(vec) mask = [~(x <= -2 || x >= 2) for x in normed] normed[mask]endこのシンプルなマスクフィルタリングにより、値が平均から大きく外れているかどうかを判別し、その基準に基づいてそれらを削除する機能が追加されました。ほとんどの場合、これらの外れ値を平均値で置き換えることも検討されます。これにより、他の特徴量やターゲットの観測値を失うことなく、データを正しく保持できます。
# pythondef drop_outls(vec : list): mu = mean(vec) normed = norm(vec) mask = [x <= -2 or x >= 2 for x in normed] ret = [] for e in range(1, len(mask)): if mask[e] == False: ret.append(vec[e]) else: ret.append(mu) return(ret)データのスケーリングのための正規分布
データサイエンスで一般的な正規分布の最終的な応用は、スタンダードスケーラーです。スタンダードスケーラーは、単純にデータに正規分布を適用するものです。このスケーラーは非常に役立ちます。なぜなら、データを対象の特徴とより関連性のあるデータに変換するのに役立つからです。これは機械学習において非常に役立ちますし、連続的な特徴量を持つ場合にはモデルの精度を簡単に向上させることができます。スタンダードスケーラーの使用は非常に簡単です。以前と同様にPDFを使用して正規化された特徴量を取得するだけです。
myX = [1, 2, 3, 4, 5]
normedx = norm(x)これは機械学習に提供されるデータに使用されます。正規分布は、毎日展開される多くの機械学習モデルで連続的な特徴を処理するためによく使用されます。
まとめ
まとめると、正規分布は統計学やデータサイエンスの基本的な要素であり、データサイエンスのさまざまな応用に広範に使用されています。この分野では、比較的単純な始まりから徐々に複雑に進展するさまざまなトピックがあります。トピックに没頭することは素晴らしいことですし、正規分布も例外ではありません。この基本的でシンプルな分布がどれだけ魅力的で重要なものであるかについて、皆さんが読んでくださり、この概要が有益であったことを願っています。ありがとうございました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
