「欠損データの解明:データサイエンティストのための絶対初心者向け入門書」
欠損データの解明:初心者向け入門書
データ品質のクロニクル
欠損データ、欠損メカニズム、および欠損データプロファイリング
今年の初めに、私は機械学習モデルに深刻な影響を与えるいくつかのデータ品質の問題(または特性)についての記事を始めました。
その中の1つは、驚くべきことに、欠損データでした。
私はこのトピックを数年間研究してきましたが(そうです、そうです!)、データ中心コミュニティで貢献したいいくつかのプロジェクトに取り組む中で、まだ多くのデータサイエンティストがこの問題の完全な複雑さを理解していないことに気付きました。これが私がこの包括的なチュートリアルを作成するきっかけとなりました。
今日は、欠損データの問題の複雑さについて深く掘り下げ、現実のデータセットで欠損値を特定およびマークする方法を探求します。
欠損データの問題
欠損データは、ドメインの性質により自然に生じる場合や、データの収集、伝送、または処理中に誤って作成される場合など、興味深いデータの欠陥です。
本質的に、欠損データはデータ中に欠損値が現れることによって特徴付けられます。つまり、データセットの一部のレコードや観測に欠損値が存在し、単変量(1つの特徴に欠損値がある)または多変量(複数の特徴に欠損値がある)のいずれかになります。
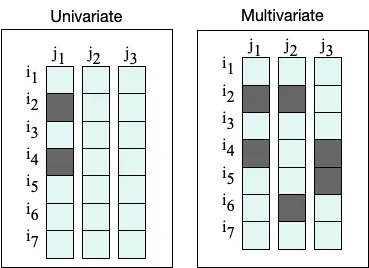
例を考えてみましょう。例えば、糖尿病に関する患者コホートの研究を行っているとしましょう。
医療データはこれには非常に適した例です。なぜなら、欠損値が頻繁に発生するからです。患者の値は調査と検査結果の両方から取得され、診断や治療の経過中に何度も測定され、異なる形式で保存される(場合によっては機関間で分散される)ことがあり、異なる人々によって扱われることが多いです。これは(そしてほとんど確実に)混乱します!
私たちの糖尿病の研究では、欠損値の存在は、行われている研究や収集されているデータに関係している可能性があります。
たとえば、欠損データは、血圧の高い値の場合にセンサーが故障してシャットダウンすることによって発生する場合があります。また、特徴量「体重」の欠損値は、年配の女性では欠損している可能性が高く、この情報を公開する意欲が低いことがあります。また、肥満の患者は体重を共有する意欲が低いかもしれません。
一方で、データが欠損している理由は、研究とは何の関係もない理由である場合もあります。
患者が情報の一部を欠落しているのは、パンクしたタイヤのために医師の予約に遅れたためかもしれません。データが欠損している理由は、人為的なエラーによる場合もあります。たとえば、分析を実施する人がいくつかの文書を紛失または誤読した場合です。
データが欠損している理由に関係なく、モデル構築の前にデータセットに欠損データが含まれているかどうか調査することが重要です。なぜなら、この問題は分類器にとって重大な影響をもたらす可能性があるからです:
- 一部の分類器は内部的に欠損値を処理できません:これにより、欠損データを含むデータセットを処理する際には適用できません。いくつかのシナリオでは、これらの値は事前に定義された値(たとえば、「0」)でエンコードされるため、機械学習アルゴリズムがこれらの値を扱うことができますが、これは最良の方法ではありません、特に欠損データの割合が高い場合(またはより複雑な欠損メカニズムの場合)にはそうです。
- 欠損データに基づく予測はバイアスがかかり、信頼性が低くなる場合があります:一部の分類器は欠損データを内部的に処理できるかもしれませんが、トレーニングデータから重要な情報が欠落しているため、予測が妥協される場合があります。
また、欠損値は「すべて同じように見えるかもしれません」が、その根本的なメカニズム(なぜ欠損しているのか)は3つの主要なパターンに従う可能性があります:完全に無作為な欠損(MCAR)、無作為でない欠損(MAR)、および無作為でない欠損(MNAR)。
これらの異なる欠損メカニズムを考慮することは重要です。なぜなら、これらは欠損データを効率的に処理するための適切な方法の選択と、それらから導かれる推論の妥当性を決定するからです。
では、それぞれのメカニズムを簡単に repass してみましょう!
欠損データメカニズム
数学的な人であれば、この論文(cof cof)を一読することをお勧めします。特に第 II 章と第 III 章には、必要な表記と数学的な定式化がすべて含まれています(実際にはこの本に触発されました。非常に興味深いプライマーでもあります。第 2.2.3 節と 2.2.4 節を参照してください)。
私のようなビジュアルラーナーの場合、それを「見る」ことができると嬉しいですよね?
そのため、論文で使用されている思春期のタバコ使用に関する研究の例を見てみましょう。各欠損メカニズムを示すために、ダミーデータを考慮します:
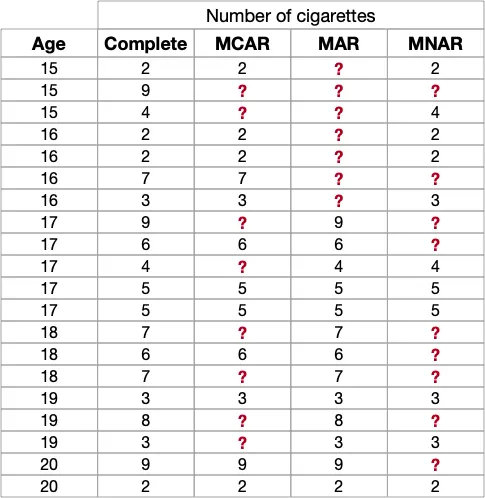
1つ念頭に置いておくべきことは、欠損メカニズムは、欠損パターンが観測データと/または欠損データによって説明できるかどうかを示しています。少しややこしいですが、例を見ればより明確になります!
私たちのタバコの研究では、思春期のタバコ使用に焦点を当てています。20の観測値(20人の参加者に対応)があり、特徴量Ageは完全に観測されていますが、1日の喫煙本数Number of Cigarettesは異なるメカニズムによって欠損することになります。
完全に無作為な欠損(MCAR):問題ありません、罰金です!
完全に無作為な欠損(MCAR)メカニズムでは、欠損プロセスは観測データと欠損データの両方とは無関係です。つまり、特徴量に欠損値がある確率は完全にランダムです。
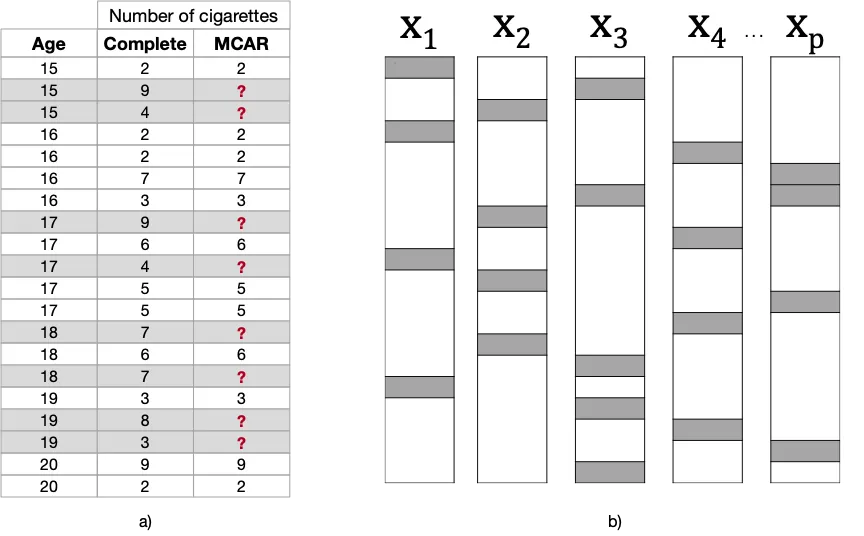
この例では、いくつかの値をランダムに削除しました。欠損値がAgeまたはNumber of Cigarettersの特定の範囲に配置されていないことに注意してください。このメカニズムは、研究中に予期しないイベントが発生したために発生する可能性があるためです:例えば、参加者の回答を登録する担当者が調査の質問を誤ってスキップした場合などです。
無作為な欠損(MAR):手がかりを探してください!
名前は実際には誤解を招くものですが、無作為な欠損(MAR)は、欠損プロセスがデータの観測情報に関連付けられる場合に発生します(ただし、欠損情報自体には関連付けられません)。
次の例を考えてみてください。ここでは、Ageが若い参加者(15歳から16歳)だけにNumber of Cigarettesの値を削除しました。欠損プロセスが clearly Ageの観測値に関連していることに注意してください。これは、これらの若者が吸っている場合には(観測されていた場合)、Number of Cigarettesの欠損値の中に低い値と高い値が見つかることを示しています。
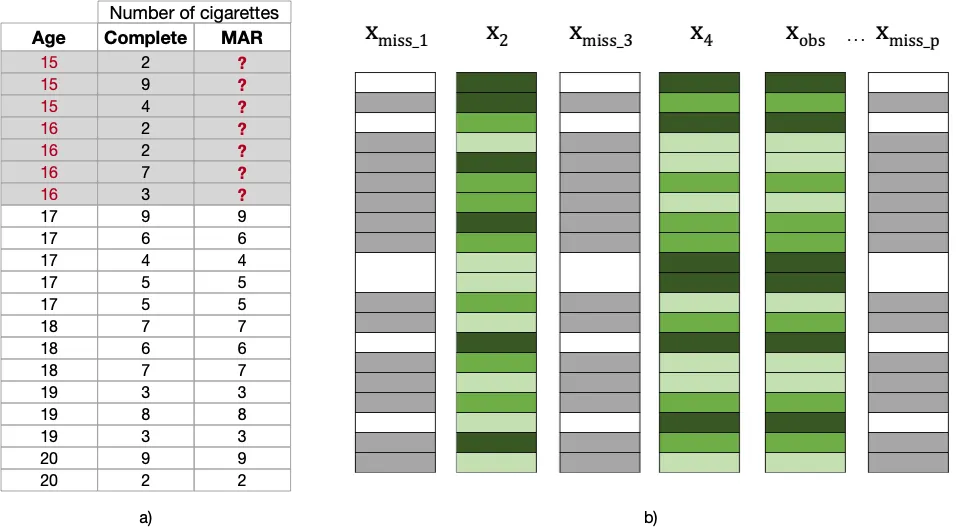
これは、若い子供たちが1日に吸うタバコの数を明かしたがらず、彼らが定期的な喫煙者であることを認めたくないため、喫煙本数の欠損値が関連している場合に当てはまります(吸う量に関係なく)。
ランダムではない欠損(MNAR):ああ、ほんとうに!
予想通り、ランダムではない欠損(MNAR)メカニズムは、観測された情報と欠損情報の両方に依存するため、すべてのメカニズムの中で最もトリッキーです。つまり、特徴の欠損値が発生する確率は、データ内の他の特徴の観測値だけでなく、その特徴自体の欠損値にも関連する可能性があることを意味します!
次の例を見てみましょう:「喫煙本数」の値が大きいほど欠損しています。つまり、「喫煙本数」の欠損値の発生確率は、欠損値が観測されていた場合に欠損値自体に関連しています(「完全」列に注目してください)。
これは、非常に多くの量を吸うために、ティーンエイジャーが1日に吸うタバコの数を報告しない場合の事例です。
欠損データメカニズムの影響
私たちのシンプルな例に沿って、MCARは欠損メカニズムの中で最も単純なものであることがわかりました。このようなシナリオでは、欠損値の発生によって引き起こされる複雑さの多くを無視することができ、ケースリスト単位またはケース単位の削除、およびより単純な統計的な補完技術など、簡単な修正が有効です。
ただし、便利ではありますが、真実は、実世界のドメインではMCARはしばしば現実的ではなく、ほとんどの研究者は少なくともMARを想定します。これは、MCARよりも一般的で現実的なものです。このシナリオでは、観測データから欠損情報を推測できるより堅牢な戦略を考慮することができます。この関連で、機械学習に基づくデータ補完戦略が一般的に最も人気があります。
最後に、MNARは遥かに最も複雑なケースです。欠損の原因を推測することは非常に困難です。現在のアプローチは、ドメインの専門家によって定義された修正要因を使用して欠損値の原因をマッピングすること、分散システムから欠損データを推測すること、最先端のモデル(例:生成モデル)を拡張して複数の補完を組み込むこと、または異なる状況下で結果がどのように変化するかを決定するために感度分析を実行することに焦点を当てています。
また、識別可能性の問題についても容易ではありません。
MCARとMARを区別するためのいくつかのテストがありますが、これらは広く普及しておらず、複雑な実世界のデータセットには適用できない制限的な仮定があります。また、MNARとMARを区別することはできません。なぜなら、必要な情報が欠損しているからです。
実践で欠損メカニズムを診断および区別するためには、仮説検定、感度分析、ドメインの専門家からの洞察を得ること、およびドメインの理解を提供できるビジュアライゼーション技術の調査に焦点を当てることがあります。
当然ながら、欠損データの処理戦略には他の複雑さも考慮する必要があります。具体的には、欠損しているデータの割合、影響を受ける特徴の数、および手法の最終目標(分類または回帰のためのトレーニングモデルへのフィード、可能な限り元の値を再構築するなど)です。
全体として、容易な仕事ではありません。
欠損データの特定とマーキング
少しずつ進めてみましょう。欠損データとその複雑な関係について、情報のオーバーロードを学びました。
この例では、実世界のデータセットで欠損データをマークし、視覚化する方法の基本をカバーし、欠損データがデータサイエンスプロジェクトにもたらす問題を確認します。
そのために、Kaggleで利用可能なPima Indians Diabetesデータセットを使用します(ライセンス-CC0:パブリックドメイン)。チュートリアルに参加したい場合は、Data-Centric AI CommunityのGitHubリポジトリからノートブックをダウンロードしてください。
データのプロファイリングを素早く行うために、ydata-profilingも使用します。これにより、わずか数行のコードでデータセットの完全な概要を取得できます。インストールから始めましょう:
ydata-profilingの最新リリースをインストールします。スニペット提供:著者。
それでは、データをロードし、簡単なプロファイルを作成します:
データのロードとプロファイリングレポートの作成。スニペット提供:著者。
データを見ると、このデータセットには欠損データがないように見えます。ただし、このデータセットは欠損データの影響を受けることが知られています!それを確認する方法はありますか?
「アラート」のセクションを見ると、ゼロのアラートが表示されていることがわかります。これは、ゼロの値が意味をなさないか、生物学的に不可能ないくつかの特徴があることを示しています。たとえば、体重指数や血圧のゼロ値は無効です。
すべての特徴を見てみると、妊娠は問題なさそうです(妊娠ゼロは合理的です)。ただし、残りの特徴に関しては、ゼロの値は疑わしいです:
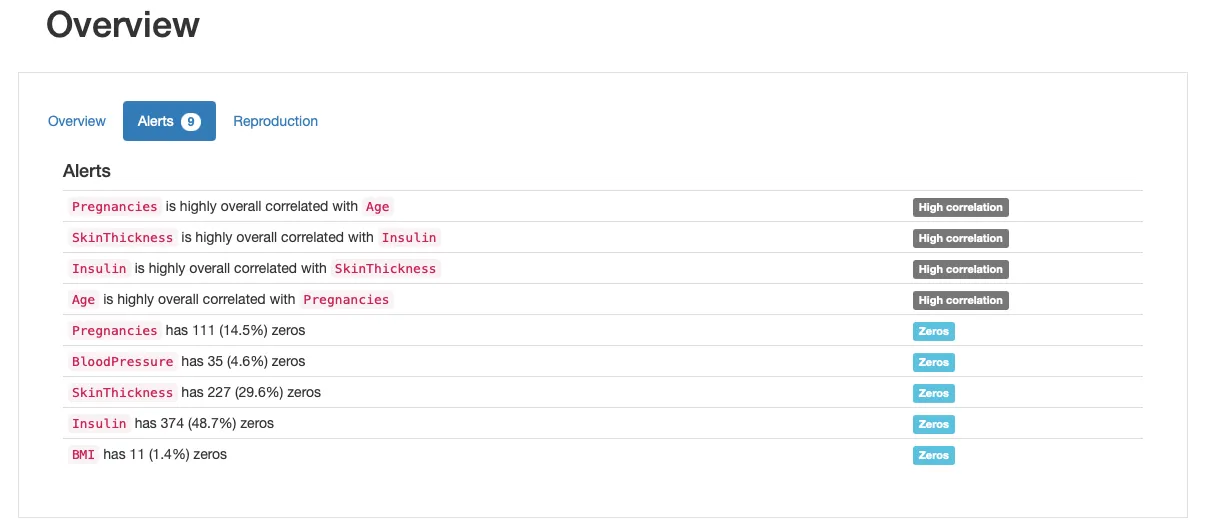
ほとんどの実世界のデータセットでは、欠損データはセンチネル値でエンコードされます:
- 999などの範囲外のエントリ;
- 特徴が正の値のみを持つ場合の負の数、たとえば-1;
- 0になることのない特徴のゼロ値。
この場合、Glucose、BloodPressure、SkinThickness、Insulin、BMIのすべてに欠損データがあります。これらの特徴のゼロ値の数を数えてみましょう:
ゼロ値の数を数える。スニペット提供:著者。
Glucose、BloodPressure、およびBMIにはわずかなゼロ値があり、SkinThicknessとInsulinにはずっと多くのゼロ値があり、存在する観測のほぼ半分をカバーしています。これは、これらの特徴を処理するために異なる戦略を検討する必要があることを意味します。たとえば、一部の特徴には他のものよりも複雑な補完技術が必要になるかもしれません。
データセットをデータ固有の規則に合わせるために、これらの欠損値を NaN 値として扱う必要があります。
これはPythonで欠損データを処理する標準的な方法であり、pandasやscikit-learnなどの人気のあるパッケージに従われています。これらの値は、sumやcountなどの特定の計算から無視され、一部の関数によって他の操作(欠損値の削除、補完、固定値での置換など)を実行するために認識されます。
欠損値をreplace()関数を使ってマークし、その後isnan()を呼び出して正しくエンコードされたかを確認します:
ゼロ値をNaN値としてマークします。著者によるスニペット。
NaN値の数は0値と同じであり、したがって欠損値が正しくマークされています!次に、欠損データが認識されているかどうかを確認するためにプロファイルレポートを再び使用することができます。以下は「新しい」データの見た目です:
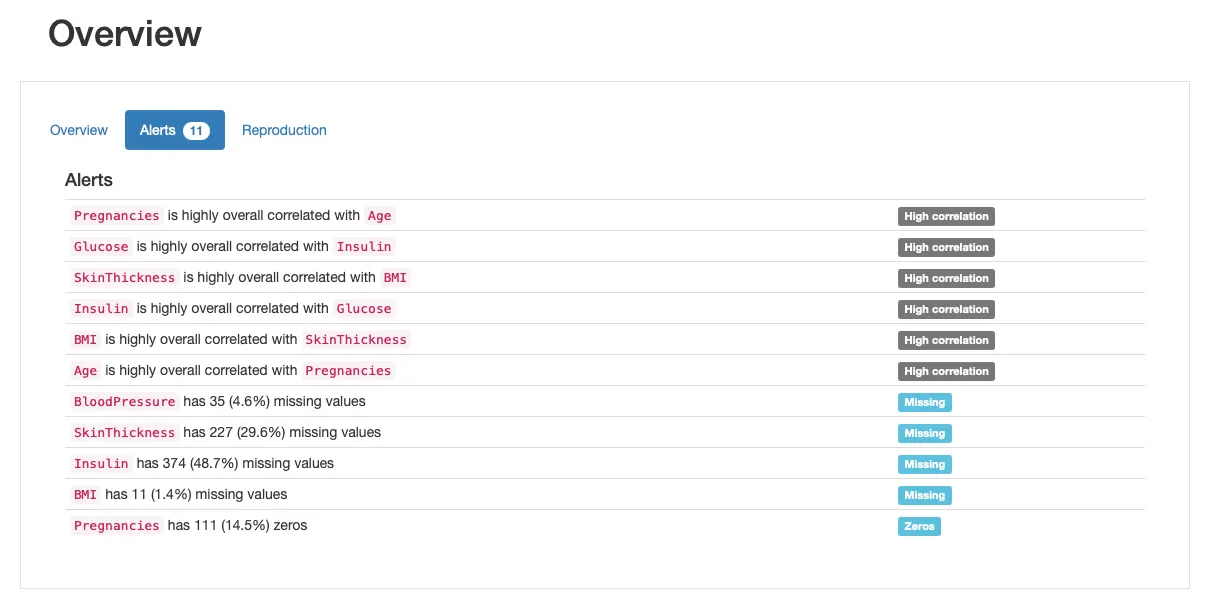
欠損プロセスのいくつかの特性をさらにチェックできます。レポートの「Missing Values」セクションをスキミングして、以下のような仮説を立てることができます:
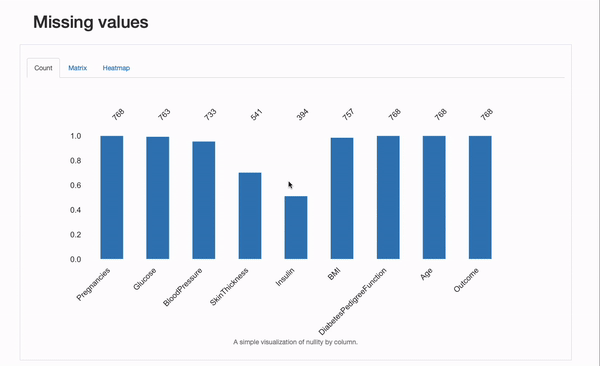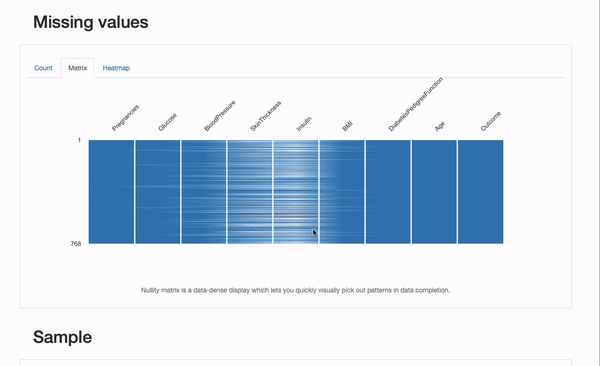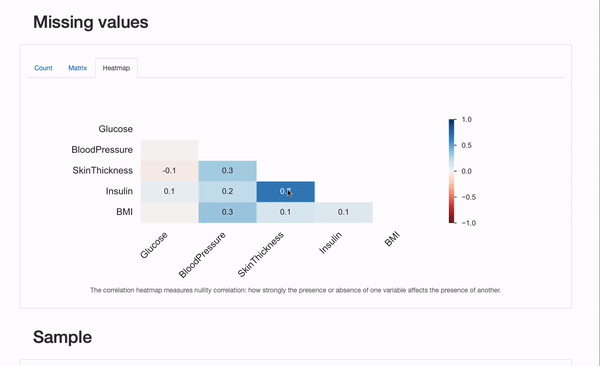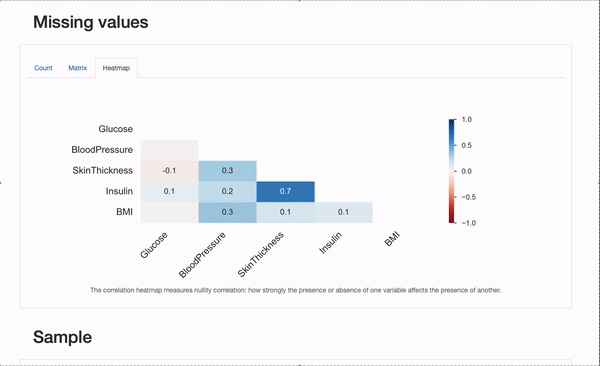
「Count」プロット以外にも、各特徴量ごとの欠損値の概要を示す「Matrix」と「Heatmap」プロットを詳細に調べることができます。特に、欠損している特徴量間の相関関係は情報を提供するかもしれません。この場合、InsulinとSkinThicknesの間には相関関係がありそうです:いくつかの患者では両方の値が同時に欠損しているようです。これが偶然(ありえない)であるか、欠損プロセスが既知の要因によって説明できるか、つまりMARまたはMNARメカニズムを表しているかどうかは、私たちが探求すべきことです!
とにかく、これでデータの分析の準備が整いました!残念ながら、欠損データの処理はまだ終わっていません。多くのクラシックな機械学習アルゴリズムは欠損データを扱うことができず、問題を軽減するためのエキスパートな方法を見つける必要があります。このデータセットで線形判別分析(LDA)アルゴリズムを評価してみましょう:
欠損値を含む線形判別分析(LDA)アルゴリズムの評価。著者によるスニペット。
このコードを実行しようとすると、すぐにエラーが発生します:

これを修正する最も単純な方法(かつ最も素朴な方法!)は、欠損値を含むすべてのレコードを削除することです。これは、dropna()関数を使用して欠損値を含む行を削除して新しいデータフレームを作成することで行うことができます…
欠損値を含むすべての行/観測を削除します。著者によるスニペット。
…そして再試行します:
欠損値のない状態でLDAアルゴリズムを評価します。著者によるスニペット。
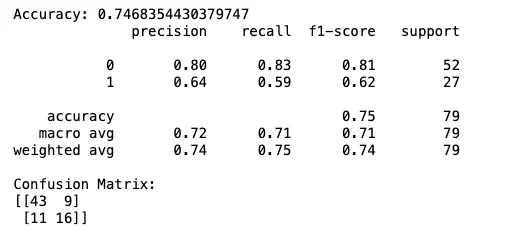
さて、以上で説明は終わりです! 欠損値を削除することで、LDAアルゴリズムを正常に動作させることができます。
ただし、データセットのサイズは392の観測のみに大幅に減少しており、利用可能な情報のほぼ半分を失っていることになります。
そのため、単に観測値を削除するのではなく、統計的な手法または機械学習ベースの代入戦略を探すべきです。また、最終的な応用に応じて欠損値を置き換えるために合成データを使用することもできます。
そのためには、データの欠損メカニズムについての洞察を得るために、将来の記事で探求してみる価値があります。
最後に
この記事では、欠損データを扱う際にデータサイエンティストがマスターする必要のある基本的な内容をすべてカバーしました。
問題自体から欠損メカニズムまで、欠損情報がデータサイエンスプロジェクトに与える影響や、NaNが同じように見えるかもしれないが、実際には異なるストーリーを伝えることについて説明しました。
次の記事では、それぞれの欠損メカニズムについて詳しく取り上げ、生成、代入、および可視化の戦略に焦点を当てますので、新しいブログ記事をお楽しみに。また、コードの更新を見逃さないように、Data-Centric AI Repositoryにスターを付けることも忘れないでください!
いつも通り、ご意見、ご質問、ご提案は大歓迎です!コメントを残したり、リポジトリに貢献したり、Data-Centric AI Communityで他のデータ関連のトピックについて議論したりすることもできます。では、そこで会いましょうか?
自己紹介
Ph.D.、機械学習研究者、教育者、データアドボケート、そして「なんでも屋」。VoAGIでは、Data-Centric AIとデータ品質について執筆し、データサイエンス&機械学習コミュニティに不完全なデータからインテリジェントなデータへ移行する方法を教えています。
YDataのデベロッパーリレーションズ | Data-Centric AI Community | GitHub | Instagram | Google Scholar | LinkedIn
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
