機械学習:中央化とスケーリングの目的を理解する
機械学習:中央化とスケーリングの目的を理解する' -> '機械学習:中央化とスケーリングの目的を理解する
変換器の使用(MinMaxScaler、StandardScaler、RobustScaler)

はじめに
この記事では、中央値とスケーリングの概念について紹介します。実世界のユースケースを使用して、データの中央化とスケール化の利点について説明します。
Scikit-Learnの準備ができたメソッドを使用して、単純な計算と説明に入ります。
技術的には、MinMaxScaler、StandardScaler、RobustScalerを比較します。これらは、前処理を容易にする変換器のメソッドの一部です。
最後に、データの中央化とスケーリングの目的を理解し、準備ができたScikit-Learnの変換器を使用できるようになります。
- 「AIは本当に低品質な画像から顔の詳細を復元できるのでしょうか? DAEFRとは何か:品質向上のためのデュアルブランチフレームワークに出会う」
- 「マイクロソフトが、自社の新しい人工知能搭載スマートバックパックに関する特許を申請」
- このAI論文は、大規模な言語モデルにおける長期的な会話の一貫性を向上させるための再帰的なメモリ生成手法を提案しています
中央化とスケーリングとは?
概念の理解
スケーリングはデータを特定の範囲やスケールに変換し、中央化はデータポイントをシフトしてその平均がゼロになるようにします。以下に例を示します。
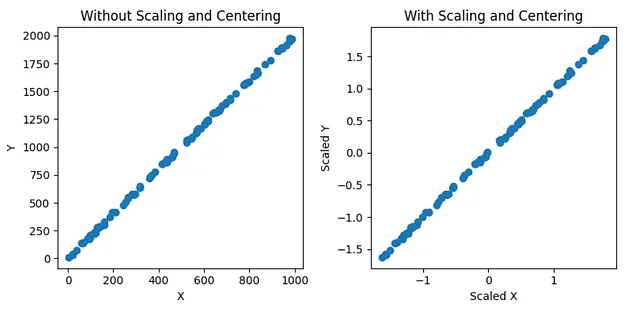
データのスケーリングと中央化の効果が見られます。右側では、データが0周りに中央化され、短いスケール(X軸およびY軸)で表示されています。
利点
データの中央化とスケーリングにはいくつかの利点がありますが、スケーリングに関しては以下が重要です:
- アルゴリズムのパフォーマンスの向上:距離を使用するK-Nearest Neighbors(KNN)やK-Meansなどのアルゴリズムは、データ間の距離に敏感です。データのスケールを縮小することで、パフォーマンスを向上させます。
- 特徴量の正規化:データセットにスケールの異なる特徴量が含まれている場合、データのスケーリングにより、大きな値を持つ特徴量に過剰な重要性を与えることを避けることができます。
- データの比較の改善:データのスケールが同じであるため、データの比較が容易になります。
- 数値的な問題の防止:データのスケーリングにより、オーバーフローやアンダーフロー(数値が非常に小さいまたは大きい場合)などの問題を防ぐことができます。
- 外れ値の影響の軽減…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




