「機械学習モデルのバリデーション方法」
機械学習モデルのバリデーション方法
機械学習ソリューションに信頼性を築く方法を学ぶ

大規模な言語モデルは、既にデータサイエンス業界を大きく変革しています。最大の利点の一つは、ほとんどのアプリケーションではそのまま使用できることです。つまり、自分自身で訓練する必要がありません。これにより、機械学習プロセス全体についての一般的な仮定を再評価する必要があります。多くの実践者は、検証を「トレーニングの一部」と考えているため、それがもはや必要ないということを示唆しています。読者が検証が時代遅れであるという提案に少し震えたことを願っています。それは確かにそうではありません。
ここでは、モデルの検証とテストの考え方について調査します。もし機械学習の基礎に完璧に精通していると思われる場合は、この記事をスキップしても構いません。そうでなければ、準備してください。私たちはあなたが信じがたいシナリオに対して疑いを抱くような内容を提供します。
この記事は、Patryk Miziuła博士とJan Kanty Milczekの共同作業です。
無人島での学習
ツイッターのツイートの言語を認識する方法を教えたいと想像してください。だから、彼を無人島に連れて行き、10の言語で100のツイートを与え、それぞれのツイートの言語を伝えて数日間彼をひとりにします。その後、彼が本当に言語を認識できるようになったかどうかを確認するために島に戻ります。しかし、どのようにそれを調べることができますか?
- メタの戦略的な優れた点:Llama 2は彼らの新しいソーシャルグラフかもしれません
- 「TableGPTという統合された微調整フレームワークにより、LLMが外部の機能コマンドを使用してテーブルを理解し、操作できるようになります」
- ReLoRa GPU上で大規模な言語モデルを事前学習する
最初の考えは、彼にツイートの言語について尋ねることかもしれません。そこで彼にこのような質問をして、彼は100のツイートすべてに正しく答えます。それは本当に彼が一般的に言語を認識できることを意味していますか?おそらく、でももしかしたら彼はただこれらの100のツイートを記憶しただけかもしれません!そして、どちらのシナリオが真実かを知る方法がありません!
ここでは、本当に確認したかったことを確認していません。このような調査に基づいて、彼のツイート言語認識のスキルが生死にかかわる状況で頼りにできるかどうかはわかりません(無人島が関係している場合は特にそうです)。
代わりにどうすればいいでしょうか?彼が学習したかどうかを確認する方法は?別の50のツイートを与え、それらの言語を教えてもらいます!もし彼が正しく答えたら、彼は本当に言語を認識できるということです。しかし、彼が完全に失敗した場合、彼は単に最初の100のツイートを暗記したとわかります。それは本来の目的ではありませんでした。
しかし、この話は機械学習モデルとはどのように関係しているのでしょうか?
上記の話は比喩的に機械学習モデルがどのように学習し、その品質を確認するべきかを説明しています:
- 物語の中の男性は機械学習モデルを表しています。人間を世界から切り離すためには無人島に連れて行く必要があります。機械学習モデルにとっては簡単です。それは単なるコンピュータプログラムであり、本質的には世界の概念を理解することができません。
- ツイートの言語を認識することは、10種類のクラス(言語)を持つ分類タスクです。
- 学習に使用される最初の100のツイートはトレーニングセットと呼ばれます。正しい言語はラベルと呼ばれます。
- 男性/モデルを調査するために使用される他の50のツイートはテストセットと呼ばれます。このセットのラベルはわかっていますが、男性/モデルはわかりません。
以下のグラフは、モデルを正しくトレーニングおよびテストする方法を示しています:
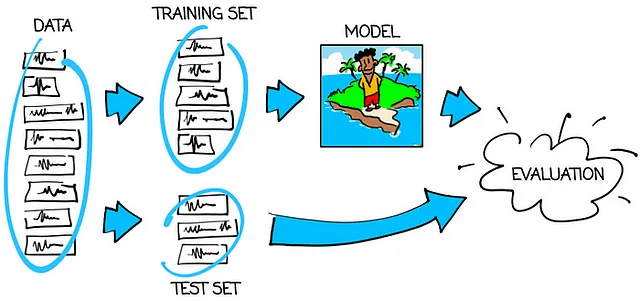
したがって、主なルールは次のとおりです:
訓練に使用したデータとは異なるデータで機械学習モデルをテストしてみましょう。
モデルがトレーニングセットでうまく機能する一方で、テストセットで性能が低い場合、モデルは過学習していると言います。「過学習」とは、トレーニングデータを記憶してしまうことを意味します。これは確かに望ましい結果ではありません。私たちの目標は、トレーニングセットとテストセットの両方に適した訓練されたモデルを持つことです。この種のモデルだけが信頼できます。そして、それがテストセットで行ったように、最終的なアプリケーションでも同じように性能を発揮すると信じることができます。
さて、さらに一歩進めましょう。
1000人が1000の無人島に
ツイッターのツイートの言語を認識するために、本当に本当にあなたは人に教えたいと思います。だから、1000人の候補者を見つけ、それぞれを異なる無人島に連れて行き、すべての候補者に同じ10の言語の100のツイートを与え、それぞれのツイートがどの言語であるかを伝え、数日間彼らをひとりにしておきます。その後、同じ50の異なるツイートのセットで各候補者を調べます。
どの候補者を選びますか?もちろん、50のツイートで最も優れた成績を収めた候補者です。しかし、彼は本当にどれほど良いのでしょうか?彼が最終的なアプリケーションでも同じように性能を発揮すると本当に信じることができるでしょうか?
答えは「いいえ」です!なぜでしょうか?単純に言えば、すべての候補者がいくつかの答えを知っていて、他のいくつかを推測している場合、最も多くの正解を得た候補者を選びます。彼は確かに最も優れた候補者ですが、彼の結果は「運の良い推測」によって膨らんでいます。それが彼が選ばれた大きな理由の一部である可能性が高いです。
数値的な形でこの現象を示すために、47のツイートがすべての候補者にとって簡単であり、残りの3つのメッセージがすべての競争相手にとって非常に困難であるため、すべての競争相手が言語を適当に推測したとしましょう。確率的には、誰か(複数の人かもしれません)がすべての3つの難しいツイートを正解した確率は63%以上です(数学マニアの情報:ほぼ1–1/eです)。したがって、おそらく完璧な成績を収めた人を選ぶことになるでしょうが、実際には必要なものには完璧ではありません。
この例の50のツイートのうち3つが驚くほどではないかもしれませんが、多くの実生活のケースでは、この不一致ははるかに顕著になる傾向があります。
では、勝者の実際の優れた成績をどのように確認できるでしょうか?そうです、もう1つの50のツイートのセットを用意し、再び彼を調べる必要があります!これだけの方法で信頼できるスコアを得ることができます。この精度レベルこそが、最終的なアプリケーションから期待されるものです。
機械学習の用語に戻りましょう
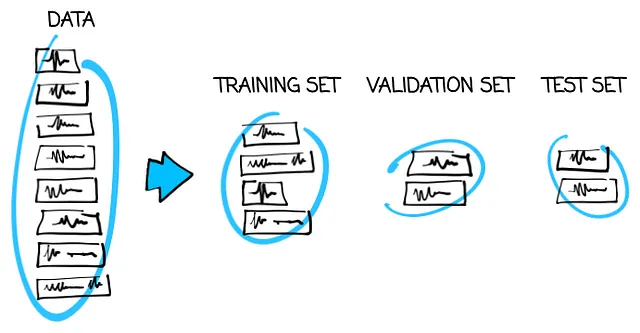
名前の観点から:
- 最初の100のツイートのセットは、トレーニングモデルに使用するため、トレーニングセットと呼ばれます。
- しかし、今度は、2番目の50のツイートのセットの目的が変わります。この時点では、異なるモデルを比較するために使用されます。このようなセットは検証セットと呼ばれます。
- 私たちはすでに、検証セットで調査された最良のモデルの結果が人為的に向上していることを理解しています。これがなぜ、もう1つの50のツイートのセットが必要で、最良のモデルの品質について信頼できる情報を提供してくれるテストセットとしての役割を果たすのです。
トレーニング、検証、テストセットの使用フローは、以下の画像で確認できます:
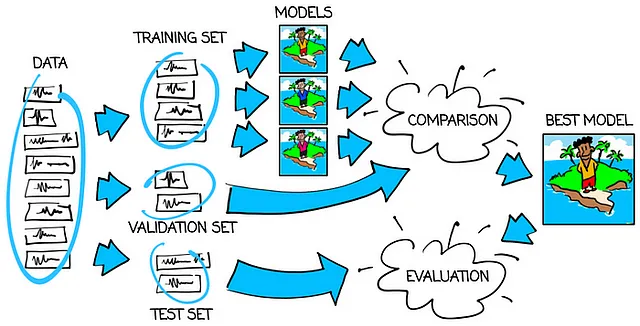
それでは、なぜちょうど100、50、50のツイートのセットを使用したのでしょうか?
これらの数字の背後にある2つの一般的な考え方は次のとおりです:
トレーニングセットにできるだけ多くのデータを入れる。
トレーニングデータが多ければ多いほど、モデルが広範な視点を持ち、過学習ではなくトレーニングする可能性が高くなります。制約はデータの入手可能性とデータの処理コストのみであるべきです。
検証セットとテストセットにできるだけ少ないデータを入れてくださいが、十分に大きくなるようにしてください。
なぜなら、トレーニング以外のことにデータを無駄に使いたくないからです。しかし、一方で、1つのツイートに基づいてモデルを評価するのはリスキーだと感じるかもしれません。そのため、本当に変わったツイートの数が少ない場合でもスコアの乱れを心配せずに済むくらい十分な数のツイートセットが必要です。
そして、これらの2つのガイドラインを具体的な数値にどのように変換するのでしょうか?もし200のツイートが利用可能な場合、100/50/50の分割は上記のルールに従っているので適しているようです。しかし、100万のツイートがある場合、800,000/100,000/100,000や900,000/50,000/50,000に簡単に移行できます。60%/20%/20%などの割合のヒントをどこかで見たかもしれませんが、それらは上記の2つの主要なルールの単純化に過ぎないため、元のガイドラインに従うことが良いでしょう。
OK、ではどのツイートをトレーニング/検証/テストセットに入れるかを選ぶ方法は?
この主要なルールはこの時点で明確になっていると考えています:
モデルのトレーニング、検証、テストには3つの異なるデータを使用してください。
では、このルールが破られた場合はどうなるのでしょうか?同じデータまたはほぼ同じデータが、偶然または注意を払わないことによって、3つのデータセットのいずれか以上に入ってしまった場合はどうでしょうか?これは私たちがデータリークと呼ぶものです。検証セットとテストセットは信頼性を失います。モデルがトレーニングされたのか、過学習されたのかを判断することができません。モデルを信頼することができません。良いことではありません。
この問題は私たちの無人島の話に関係ないと思うかもしれませんが、トレーニングには100のツイート、検証には50のツイート、テストにはさらに50のツイートを使用するだけです。残念ながら、それはそんなに単純ではありません。非常に注意が必要です。いくつかの例を見てみましょう。
例1:多数のランダムなツイート
Twitterから完全にランダムな1,000,000のツイートをスクレイピングしたと仮定しましょう。異なる作者、時間、トピック、地域、リアクションの数など。完全にランダムです。そして、それらは10の言語で書かれており、モデルに言語を認識させるために使用したいとします。その場合、トレーニングセットには900,000のツイート、検証セットには50,000のツイート、テストセットには50,000のツイートを単純に選ぶだけで心配する必要はありません。これはランダム分割と呼ばれます。
なぜ最初の900,000のツイートをトレーニングセット、次の50,000のツイートを検証セット、最後の50,000のツイートをテストセットに入れないのでしょうか?なぜなら、ツイートは最初にアルファベット順や文字数順などの方法でソートされる場合があり、それが助けにならない可能性があるからです。そして、テストセットに「Z」で始まるツイートだけを入れたり、最も長いツイートだけを入れたりすることに興味はありませんよね?だから、ランダムに選ぶ方が安全です。
ツイートが完全にランダムであるという仮定は強いです。それが本当かどうかは常に二度考えてください。次の例では、それが真実でない場合に起こることを見ていきます。
例2:あまり多くないランダムなツイート
もし10の言語で完全にランダムなツイートが200しかない場合、それらをランダムに分割することもできます。しかし、新たなリスクが生じます。ある言語が主流で128のツイートがあり、他の9つの言語ごとに8つのツイートがあるとします。確率的には、すべての言語が50の要素のテストセットに入らない可能性は61%以上になります(数学好きのための情報:包除原理を使用してください)。しかし、10の言語すべてでモデルをテストしたいので、すべての言語をテストセットに含める必要があります。どうすればいいでしょうか?
クラスごとにツイートを選ぶことができます。例えば、128のツイートを持つ主流のクラスから、トレーニングセットには64のツイート、検証セットには32のツイート、テストセットには32のツイートを選びます。その後、他のすべてのクラスについても同様に行います-それぞれのクラスごとに4つ、2つ、2つのツイートをトレーニング、検証、テストに選びます。これにより、必要なサイズの3つのセットが形成され、各セットにはすべてのクラスが同じ比率で含まれます。この戦略は層別ランダム分割と呼ばれます。
通常のランダムな分割よりも層別のランダムな分割の方が良い/安全であるため、なぜExample 1でそれを使用しなかったのでしょうか?それは必要なかったからです! 5%のツイートが英語であり、1,000,000のツイートから50,000のツイートを言語に関係なく選ぶ場合、選ばれたツイートの5%も英語であるというのが確率の働き方です。これが確率の働き方です。ただし、確率は適切に機能するためには十分な数値が必要ですので、1,000,000のツイートがある場合は問題ありませんが、200しかない場合は注意が必要です。
例3:いくつかの機関からのツイート
今度は、100,000のツイートがあると仮定しますが、それらは20の機関からのものです(ニューステレビ局、大きなサッカークラブなどとします)し、それぞれが10のTwitterアカウントを10の言語で運営しています。そして、再び私たちの目標は一般的なTwitterの言語を認識することです。ランダムな分割を単純に使用できるでしょうか?
あなたは正しいです – もし可能なら、私たちは尋ねませんでした。でもなぜでしょうか?これを理解するために、まずはもっと単純なケースを考えてみましょう:もし私たちが1つの機関のツイートのみでモデルを訓練し、検証し、テストした場合、このモデルを他の機関のツイートに使用することができるでしょうか?私たちは分かりません!この機関のユニークなツイートスタイルにモデルが過学習するかもしれません。それをチェックするための手段はありませんでした!
私たちのケースに戻りましょう。ポイントは同じです。20の機関の総数は少なめです。したがって、同じ20の機関のデータを使用してモデルを訓練し、比較し、評価すると、おそらくモデルはこれら20の機関の20のユニークなスタイルに過学習し、他の著者ではうまくいかなくなるでしょう。そして、これを確認する方法はありません。良くないですね。
では、どうすれば良いのでしょうか?もう1つの主なルールに従いましょう:
検証セットとテストセットは、モデルが適用される実際のケースをできるだけ忠実に再現する必要があります。
今、状況はより明確になりました。最終的なアプリケーションでは、私たちがデータに持っているものとは異なる著者が予想されるため、訓練セットとは異なる著者も検証セットとテストセットに含める必要があります!そして、その方法は機関ごとにデータを分割することです!たとえば、10の機関を訓練セットに選び、別の5つを検証セットに置き、残りの5つをテストセットに置けば、問題は解決します。

どの機関に対してもより緩やかな分割(4つの機関全体と残りの16つの一部をテストセットに置くなど)はデータ漏れとなり、それは良くありませんので、機関を分離する際には妥協はできません。
悲しい最終的な注意:機関ごとの正しい検証分割に対しては、異なる機関のツイートに対しては解決策を信頼することができるかもしれません。しかし、プライベートアカウントからのツイートは異なる見た目をしている可能性がありますので、私たちが持っているデータでは、それらのツイートに対してうまく機能するかどうかはわかりません。
例4:同じツイート、異なる目標
例3は難しいですが、注意深く進めた場合、これはかなり簡単になります。したがって、例3とまったく同じデータを持っていると仮定しますが、今度は目標が異なります。今回は、私たちのデータにある同じ20の機関の他のツイートの言語を認識したいと思います。今度はランダムな分割は大丈夫でしょうか?
答えは:はい。ランダムな分割は、私たちのデータにある機関に関心があるだけなので、最後の主なルールに完全に従っています。
例3と4は、データを分割する方法がデータだけに依存するのではなく、データとタスクの両方に依存することを示しています。トレーニング/検証/テストの分割を設計する際には、これを念頭に置いてください。
例5:まだ同じツイート、別の目標
前の例では、持っているデータを保持しながら、モデルに将来のツイートから機関を予測するように教えてみましょう。したがって、再び分類タスクを持つことになりますが、今回はツイートが20の機関から来ているため、20のクラスがあります。この場合はどうでしょうか?データをランダムに分割できますか?
前と同様に、しばらくの間より単純なケースについて考えてみましょう。例えば、テレビニュース局と大きなサッカークラブの2つの機関しか持っていないとしましょう。彼らはどのようなツイートをするでしょうか?両方とも、一つの話題から別の話題に飛び移るのが好きです。3日間はトランプやメッシ、次に3日間はバイデンやロナウドなどです。明らかに、彼らのツイートには数日ごとに変わるキーワードが見つかります。では、1ヶ月後にはどのようなキーワードが見られるでしょうか?現時点では完全に無名の可能性もある政治家や悪役やサッカー選手やサッカーコーチが「話題」となるかもしれません。したがって、機関を認識するためには一時的なキーワードに焦点を当てるのではなく、一般的なスタイルを把握する必要があります。
では、20の機関に戻りましょう。先ほどの観察結果は有効です:ツイートのトピックは時間とともに変わるため、将来のツイートで私たちの解決策を動作させたいので、短命なキーワードに焦点を当てるべきではありません。しかし、機械学習モデルは怠惰です。簡単な方法でタスクを達成できれば、それ以上見ることはありません。キーワードに固執することもそのような簡単な方法です。では、モデルが適切に学習したのか、一時的なキーワードをただ記憶しただけなのかをどのように確認できるでしょうか?
ランダムに分割する場合、週ごとのヒーローに関するツイートが3つのセットすべてに含まれることを予想するべきです。そのため、訓練セット、検証セット、テストセットには同じキーワードが含まれることになります。これは望ましくありません。よりスマートに分割する必要があります。しかし、どのようにすれば良いのでしょうか?
最後のメインルールに戻ると、簡単になります。将来にわたって解決策を使用したいので、検証セットとテストセットは訓練セットに対して未来であるべきです!データを時間によって分割する必要があります。たとえば、2022年7月から2023年6月までの12か月のデータがある場合、2022年7月から2023年4月までをテストセット、2023年5月を検証セット、2023年6月をテストセットに配置することで、問題を解決できます。

時間による分割では、季節ごとにモデルの品質を確認しないと心配かもしれません。それは正しいです、それは問題です。しかし、ランダムに分割するよりも小さな問題です。たとえば、次のような分割を考えることもできます:毎月1日から20日までを訓練セット、20日から25日までを検証セット、月末の25日から最後までをテストセットにするなどです。いずれにしても、検証戦略の選択はデータリークの潜在的な問題とのトレードオフです。安全性のあるオプションを理解し、意識的に選択する限り、うまくいっています。
サマリー
私たちは荒れ果てた島で物語を展開し、可能な限り現実世界の考慮事項からモデルの検証とテストの問題を分離するために最善を尽くしました。それでも、私たちは落とし穴に次々とひっかかりました。幸いなことに、それらを避けるためのルールは簡単に学ぶことができます。途中で学ぶことが多いかもしれませんが、マスターするのは難しいです。データリークをすぐに気づくことはありませんし、常にそれを防ぐことはできません。それでも、検証スキームの信頼性を慎重に考慮することは、より良いモデルにつながることでしょう。これは、新しいモデルが発明され、新しいフレームワークがリリースされても有効です。
また、私たちは荒れ果てた島に取り残された1000人を抱えています。タイムリーに彼らを救出するためには、良いモデルが必要かもしれません。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- SimPer:周期的なターゲットの簡単な自己教示学習
- LMSYS ORG プレゼント チャットボット・アリーナ:匿名でランダムなバトルを行うクラウドソーシング型 LLM ベンチマーク・プラットフォーム
- 「Mojo」という新しいプログラミング言語は、Pythonの使いやすさとCのパフォーマンスを組み合わせ、AIハードウェアのプログラム可能性とAIモデルの拡張性を他のどの言語よりも優れたものにします
- MPT-7Bをご紹介します MosaicMLによってキュレーションされた1Tトークンのテキストとコードでトレーニングされた新しいオープンソースの大規模言語モデルです
- AIとディープラーニングに最適なGPU
- ラミニAIに会ってください:開発者が簡単にChatGPTレベルの言語モデルをトレーニングすることができる、革命的なLLMエンジン
- MLCommonsは、臨床効果を提供するためのAIモデルのベンチマークを行うためのオープンソースプラットフォームであるMedPerfを紹介します






