専門家モデルを用いた機械学習:入門
機械学習の専門家モデル入門
数十年前のアイデアが今日、途方もなく大きなニューラルネットワークのトレーニングを可能にする方法

エキスパートモデルは、機械学習において最も有用な発明の一つですが、それほど十分に注目されていません。実際、エキスパートモデリングは、単に「途方もなく大きい」ニューラルネットワークをトレーニングすることができるだけでなく(後で詳しく説明します)、人間の脳のように学習するモデルを構築することも可能です。すなわち、異なる領域が異なるタイプの入力に特化して学習することができます。
この記事では、エキスパートモデリングの主要なイノベーションを紹介し、最近のブレークスルーであるSwitch TransformerやExpert Choice Routingアルゴリズムなどにつながる要素を見ていきます。しかし、まずはすべての始まりである「Mixtures of Experts」という論文に戻りましょう。
Mixtures of Experts(1991年)
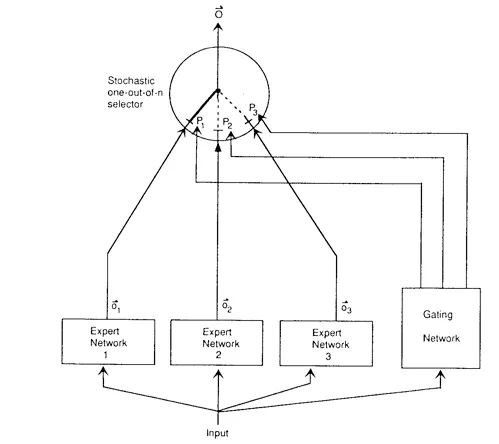
エキスパートの混合(MoE)のアイデアは、AIの神様として知られるジェフリー・ヒントンを含む共著者によって3年以上前にさかのぼります。MoEの中心的なアイデアは、出力「y」を「エキスパート」Eの組み合わせによってモデル化し、各エキスパートの重みを「ゲーティングネットワーク」Gが制御することです。
この文脈でのエキスパートは、どのような種類のモデルでも構いませんが、通常は多層ニューラルネットワークが選ばれ、ゲーティングネットワークは
- 「Amazon SageMakerでのRayを使用した効果的な負荷分散」
- 『ご要望に合わせたチャット:ソフトウェア要件に応用した生成AI(LLM)の旅』
- プラグインを使ったチャットボットのためのカスタムスキルの作成
ここで、Wは学習可能な行列であり、トレーニング例をエキスパートに割り当てます。MoEモデルのトレーニングでは、学習目標は次の2つです:
- エキスパートは、与えられた出力を最適な出力(つまり、予測)に処理するように学習します。
- ゲーティングネットワークは、ルーティング行列Wを共同で学習することにより、正しいトレーニング例を正しいエキスパートに「ルーティング」することを学習します。
では、なぜこれを行う必要があるのでしょうか?そして、なぜこれが機能するのでしょうか?大まかなレベルで、このアプローチを使用する主な動機は3つあります:
まず第一に、MoEはモデルのスパース性により、ニューラルネットワークを非常に大きなサイズまでスケーリングすることが可能です。つまり、全体的なモデルは大きいですが、実際に利用されるのはごく一部の…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






