「機械学習を使用するかどうか」
機械学習の使用
MLを使用することが良いアイデアかどうかを判断する方法、およびそれがGenAIとともに変化している方法

機械学習は、通常、特徴と結果の間の難しい関係を含む、ヒューリスティックやif-else文で簡単にハードコーディングできない複雑な問題を解決するのに非常に適しています。ただし、MLが与えられた問題に対する良い解決策かどうかを判断する際には、いくつかの制限や考慮事項があります。この記事では、「MLを使用するかどうか」というトピックについて詳しく説明します。まずは「従来の」MLモデルに対して理解し、その後、Generative AIの進歩とともにこの状況がどのように変化しているかについて議論します。
いくつかのポイントを明確にするために、以下の取り組みを例として使用します。「会社として、クライアントが満足しているかどうかと、不満の主な理由を知りたい」とします。この問題を解決する「従来の」MLベースのアプローチは次のようになります:
- クライアントがあなたについて書いたコメントを取得する(アプリまたはプレイストア、Twitterなどのソーシャルネットワーク、ウェブサイトなど)
- センチメント分析モデルを使用してコメントを肯定的/中立的/否定的に分類する
- 予測された「否定的なセンチメント」のコメントに対してトピックモデリングを使用して、それらが何についてのコメントなのかを理解する

データは十分な品質とボリュームを持っていますか?
教師ありのMLモデルでは、モデルが予測するために学習するためのトレーニングデータが必要です(この例では、コメントからのセンチメント)。データが品質が低い場合(たくさんのタイポ、欠損データ、エラーなど)、モデルのパフォーマンスは非常に低くなります。
これは一般的に「ゴミを入れればゴミが出る」として知られています。データがゴミであれば、モデルと予測もゴミになります。
同様に、モデルが予測するために必要なさまざまな事例を学習するために、十分なボリュームのデータを持っている必要があります。この例では、「使い物にならない」、「失望した」といった概念が付いたネガティブなコメントの場合、モデルはこれらの単語が「ネガティブ」のラベルの場合に通常表示されることを学習することができません。
十分なボリュームのトレーニングデータは、予測を実行するために必要なデータの適切な表現を確保するのにも役立ちます。たとえば、トレーニングデータに特定の地理的エリアや特定の人口セグメントの表現がない場合、モデルはそれらのコメントに対してうまく機能しない可能性が高くなります。
一部のユースケースでは、十分な過去のデータも重要です。これにより、適切な遅延特徴やラベル(たとえば、「お客様が次の年にクレジットを支払うかどうか」)を計算できるようになります。
ラベルは明確に定義され、簡単に取得できますか?
再び、従来の教師ありMLモデルでは、ラベル付きのデータセットが必要です。予測したい最終結果を既知の例として持つことで、モデルをトレーニングすることができます。
ラベルの定義は重要です。この例では、私たちのラベルはコメントと関連するセンチメントです。私たちは「肯定的」または「否定的」のコメントしか持っていないと考えるかもしれませんし、それに加えて「中立的」なコメントもあるかもしれません。この場合、特定のコメントについて、「肯定的」または「非常に肯定的」のラベルを付けるのは簡単でしょうか?このようなラベルの明確な定義の欠如は避ける必要があります。ノイズのあるラベルでトレーニングすると、モデルの学習が困難になります。
ラベルの定義が明確になったので、それを十分で品質の高い例のセットから取得できる必要があります。これらの例は私たちのトレーニングデータとなります。この例では、会社やチーム内で手動でコメントのセットにタグ付けすることを考慮することができますし、専門の注釈者にタグ付けを外部化することもできます(はい、機械学習のためにデータセットにラベルを付けるために専任で働く人々がいます!)。これらのラベルの取得に関連するコストと実現可能性を考慮する必要があります。
解決策の展開は実現可能ですか?
最終的な影響を得るために、機械学習モデルの予測は使える必要があります。使用ケースによっては、予測を使用するために特定のインフラストラクチャ(例:MLプラットフォーム)と専門家(例:MLエンジニア)が必要になることがあります。
この例では、解析目的でモデルを使用したい場合、オフラインで実行し、予測を利用することは非常に簡単になります。ただし、次の5分以内にネガティブなコメントに自動的に応答する場合、これは別の話です。この場合、モデルを展開して統合する必要があります。全体として、予測を使用するための要件を明確に把握することは重要です。それによって、チームと利用可能なツールで実現可能かどうかを確認できます。
何が危険ですか?
機械学習モデルの予測には常に一定の誤差があります。実際、機械学習では次のように言われています。
モデルにエラーがない場合、データまたはモデルに必ず何か問題がある
これは重要な点です。なぜなら、使用ケースがこれらのエラーを許容しない場合、機械学習を使用することは良い考えではないかもしれません。この例では、コメントと感情ではなく、顧客からのメールを「告訴するか否か」に分類するためにモデルを使用していると想像してみてください。会社に対して告訴を行うメールを誤って分類するようなモデルを持つことは、会社にとって非常に深刻な結果をもたらす可能性があるため、良い考えではありません。
機械学習の使用は倫理的に正しいですか?
性別、人種、および他の個人情報に基づいて差別的な予測モデルが多数報告されています。そのため、機械学習チームは自分たちのプロジェクトに使用するデータと特徴に注意を払う必要があります。また、倫理的な観点から、特定のタイプの意思決定を自動化することが本当に意味があるのかを疑問視する必要もあります。詳細については、以前のブログ記事をご覧ください。
説明性が必要ですか?
機械学習モデルは黒箱のようなものです。情報を入力すると、魔法のように予測が出力されます。モデルの背後にある複雑さは、統計のより単純なアルゴリズムと比較して、この黒箱の背後にあるものです。この例では、「ポジティブ」と「ネガティブ」と予測されたコメントの理由を正確に理解できないことが許容できるかもしれません。
他の使用ケースでは、説明可能性が必須となる場合があります。たとえば、保険や銀行のような厳格に規制された業界では、銀行はスコアリング予測モデルに基づいてクレジットを与える(または与えない)決定を説明できる必要があります。
このトピックは倫理的な観点と強い関係があります。モデルの意思決定を完全に理解できない場合、モデルが差別的な学習をしているかどうかを知ることは非常に困難です。
ジェネレーティブAIとともにこれらのすべては変わっていますか?
ジェネレーティブAIの進歩により、さまざまな企業が強力なモデルを消費するためのウェブページやAPIを提供しています。これにより、以前に述べた機械学習に関する制限や考慮事項はどのように変化していますか?
- データ関連のトピック(品質、量、ラベル):既存のジェネレーティブAIモデルを活用できる使用ケースでは、これは確かに変化しています。巨大なデータ量が既にジェネレーティブAIモデルの訓練に使用されています。これらのモデルではデータの品質はほとんど制御されていませんが、使用するデータの量が補償されているようです。これらのモデルのおかげで、トレーニングデータが不要になる場合があります。これをゼロショット学習(例:「ChatGPTに与えられたコメントの感情は何ですか?」と尋ねる)およびフューショット学習(例:「ChatGPTに肯定的な、中立的な、ネガティブなコメントのいくつかの例を提供し、新しいコメントの感情を提供してもらう」)と呼びます。これについては、deeplearning.aiのニュースレターで詳しく説明されています。
- 展開の実現可能性:既存のジェネレーティブAIモデルを活用できる使用ケースでは、提供されている強力なモデルに対して簡単に展開できるようになります。これらのモデルをプライバシーの理由で微調整したり、内部に持ち込んだりする必要がある場合、展開はもちろん困難になります。
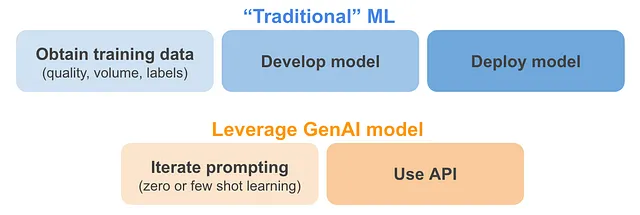
GenAI の活用の有無に関わらず、他の制約や考慮事項は変わりません:
- 高いリスク: これは問題として残ります。なぜなら、GenAI モデルも予測において誤差があります。誰もが GhatGPT が幻覚を見たり意味のない回答を提供したりするのを見たことがあるでしょう。さらに悪いことに、これらのモデルを評価するのは難しく、応答は常に自信を持って聞こえますが、その正確さに関係なく、評価は主観的になります(例:「この応答は私にとって意味があるか?」)。
- 倫理: これまでと同様に重要です。GenAI モデルは、使用された入力データによってバイアスが生じることが証明されています(リンク)。これらのタイプのモデルを使用する企業や機能が増えるにつれて、これによってもたらされるリスクを明確にすることが重要です。
- 説明可能性: GenAI モデルは「従来の」機械学習よりも大きく複雑ですので、予測の説明可能性はますます難しくなります。この説明可能性を実現するための研究は進行中ですが、まだ非常に未熟です(リンク)。
まとめ
このブログ記事では、ジェネレーティブ AI モデルの進歩により、機械学習の使用の是非を決める際に考慮すべき主要な要素を見てきました。議論された主要なトピックは、データの品質とボリューム、ラベルの取得、展開、リスク、倫理、説明可能性でした。次の機械学習(または非機械学習)の取り組みを考慮する際に、この要約が役立つことを願っています!
参考文献
[1] ML バイアス: 導入、差別的な予測モデルへのリスクと解決策(著者による)、
[2] テストセットを超えて: プロンプティングが機械学習の開発を変える方法(deeplearning.ai による)
[3] 大規模言語モデルはバイアスがある、論理はそれらを救えるのか?(MIT News による)
[4] OpenAI の言語モデルの振る舞いを説明する試み(TechCrunch)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
