スケールにおける機械学習:モデルとデータの並列化
機械学習のスケール:モデルとデータの並列化
大規模機械学習の秘密を解読する
はじめに
モデルがますます複雑になり、データセットも巨大になるにつれて、計算ワークロードを効率的に分散する方法の必要性は以前よりも重要になっています。昔ながらの一台のコンピューターのセットアップでは、現代の機械学習の計算ニーズには対応できません。
大きな問題: これらの複雑な機械学習ジョブ(モデルのトレーニングと推論)を効果的に複数の計算リソースに分散する方法は何でしょうか?
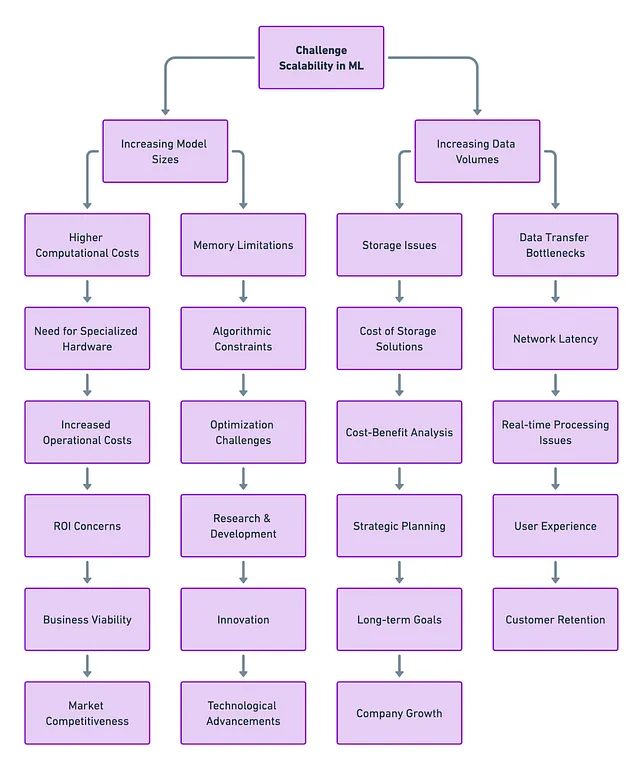
答えは、分散機械学習計算の2つの主要な技術、「モデル並列化」と「データ並列化」にあります。それぞれには強み、弱点、理想的な使用ケースがあります。この記事では、これらの技術に詳しく立ち入り、それらの微妙な違いを探求し、比較します。
モデル並列化とデータ並列化とは何ですか?
モデル並列化
この方法は、機械学習モデルの異なる部分を複数のコンピューティングリソース(GPUなど)に分散するものです。これは、単一のマシンのメモリに収まらない大型モデルに最適な解決策です。
- 「LangChainエージェントを使用してLLMをスーパーチャージする方法」
- シンプルなDockerデータサイエンスイメージの作成
- 「PyTorch ProfilerとTensorBoardを使用して、データ入力パイプラインのボトルネックを解消する」
データ並列化
一方、データ並列化は、モデル自体を各マシンに配置し、データセットを複数のリソースに小さなチャンクやバッチとして分散する方法です。この技術は、大規模なデータセットがありながらメモリに簡単に収まるモデルの場合に便利です。
モデル並列化: 詳細を見る
いつ使用するのか?
GPUに大規模なニューラルネットワークをロードしようとして、「メモリ不足」の恐れがあるエラーが発生したことはありませんか?それはまるで丸い穴に四角いくぎをはめようとするようなものです。それはうまくいきません。しかし、心配しないでください、モデル並列化がお手伝いします。
どのように機能するのか?
ニューラルネットワークがマルチストーリービルディングのようなものであり、各階がネットワークの層であると想像してみてください。さて、もしビルの各階を異なる土地(または私たちの場合は異なるGPU)に配置できるとしたらどうでしょうか?それにより、小さなプロットにビル全体を積み重ねようとしているわけではありません。技術的な言葉で言えば、モデルを分割し、異なる部分を異なるGPUに配置することを意味します。
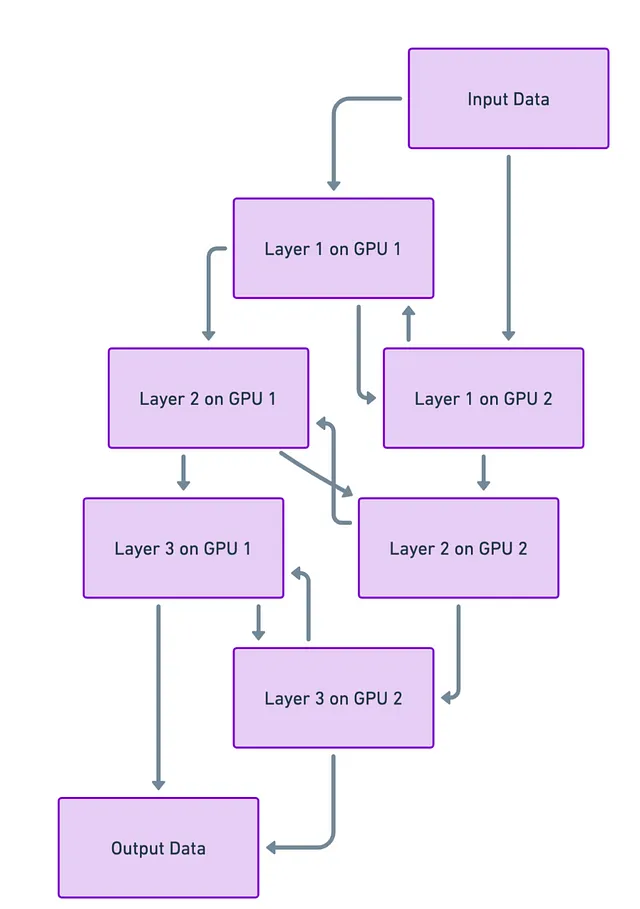
課題
しかし、すべてが順調ではありません。ビルを分割したり、ニューラルネットワークを分割したりする場合でも、階段やエレベーター(またはデータパス)が必要です。そして、これらは詰まることがあります。言い換えれば、異なる部分が迅速かつスムーズにコミュニケーションを取ることが主な課題です。この通信が遅い場合、学習プロセス全体が遅くなる可能性があります。
データ並列化: 詳細を見る
いつ使用するのか?
非常に大量のデータがあるが、機械学習モデル自体はあまり複雑ではない場合を想像してみてください。この場合、データ並列化はあなたの頼れるキッチンブレンダーのようなものです。あなたが投入するすべての材料を簡単に処理できます。
どのように動作しますか?
各コンピュータまたはGPUを個別のキッチンと考えてください。それぞれのキッチンには独自のブレンダー(モデル)があります。大量のデータを小さな部分に分割します。各「キッチン」は小さなデータの部分とそれに対応するブレンダーを取得し、そのデータに取り組みます。このようにして、複数のキッチンが同時にスムージー(勾配の計算)を作っています。
各キッチンがブレンドを終えた後、すべてのスムージーを一つの場所に持ち帰ります。それから、それらを混ぜ合わせて一つの巨大で完璧にブレンドされたスムージーを作ります(すべての個別の計算に基づいてモデルを更新します)。
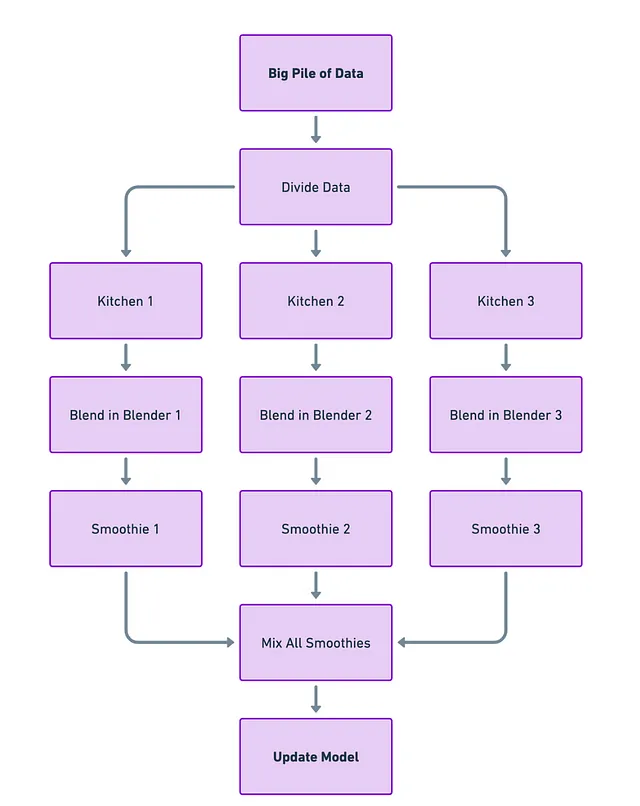
課題
難しい部分は最後のステップです-スムージーを効率的に混ぜることです。結合が遅い場合や乱雑な場合、時間の浪費だけでなく、あまり良くない最終的なスムージー(効率の悪いモデルトレーニング)になる可能性もあります。したがって、課題はできるだけ効率的かつ迅速にすべてを一緒に持ち戻すことです。
技術的な言葉で言えば、各GPUから計算された勾配を収集し、モデルを更新するための速い方法を見つける必要があります。うまく行わないと、モデルのトレーニングに時間がかかったり、実際のタスクでパフォーマンスが低下する可能性があります。
違いの概要
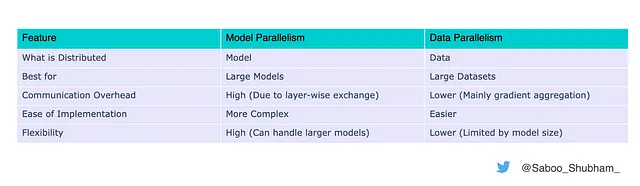
なぜ両方を使わないのですか?
機械学習の複雑な領域では、一つのサイズがすべてに合うことはほとんどありません。モデルとデータ並列化の相乗効果がしばしば最適な結果をもたらします。たとえば、大きなモデルを複数のGPUに分割して配置(モデル並列化)し、その後、データをそれぞれの並列セットアップに分散させる(データ並列化)ことがあります。
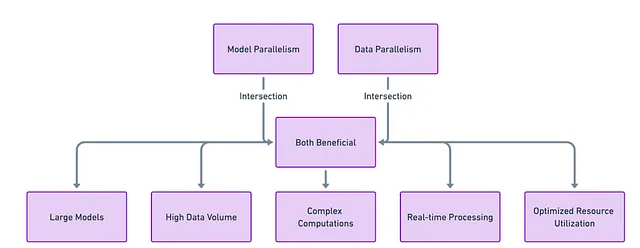
モデル並列化とデータ並列化の組み合わせは、機械学習の「レシピ」を完成させるための鍵です。
機械学習におけるレンジコンロのたとえ
このたとえでは、レンジコンロは単一のGPUまたはコンピュータのようなものです。同時に異なる調理タスクに使用できるオーブンとコンロがあります。
オーブン = モデル並列化
オーブンに入りきらない大きな七面鳥がある場合、それを切り分けて別々に調理することがあります-たとえば、胸肉をオーブンの一部に、脚肉を別の部分に。これはモデル並列化と似ており、大きなモデルを複数のGPUに分割するものです。この場合、単一のレンジコンロのオーブンのコンパートメントは、1つのGPUまたは1つのコンピューティングリソースの一部を表しています。
コンロ = データ並列化
さて、コンロのバーナーで調理している異なる副菜があるとしましょう。片方のバーナーでマッシュポテトを調理し、もう一方でインゲン豆を炒めることができます。ここでは、各バーナーはデータ並列化のアプローチを表しており、異なるデータの一部が独立して処理されますが、同じGPUまたはコンピューティング環境内で行われます。
フィーストのために両方を組み合わせる
最後に、フィーストを完成させるためにオーブンとコンロを同時に使用します。七面鳥の部位がオーブンにある(モデル並列化)、副菜がコンロにある(データ並列化)とします。調理が完了したら、すべての七面鳥の部位と副菜を組み合わせて完全な食事を提供します。同様に、モデル並列化とデータ並列化を組み合わせることで、大きなモデルと大規模なデータセットを効率的に処理し、最終的に正常にトレーニングされたモデルを提供することができます。
機械学習の”キッチン”で、’オーブン’と’コンロ’の両方を活用することで、手元にあるすべてのリソースを最大限に活用してデータとモデルを効率的に調理することができます。
結論
機械学習の分野が進化し続ける中で、モデルとデータの並列処理などの技術の重要性はますます高まり、日常の機械学習の作業においてますます関連性が高まっています。これらの微妙な違いを理解することは、LLMsやStable Diffusionなどの大規模な機械学習モデルを開発・展開する人にとって重要です。
適切な技術または両方の組み合わせを選ぶことで、現代の機械学習の課題を克服し、ML作業のスケーラビリティと効率を引き出すことができます。
最新の機械学習の動向について最新情報を知りたいですか?最新のAIのトレンドを追いかけるために私の旅をフォローしてください👇
私とつながる: LinkedIn | Twitter | Github

この投稿が役に立ったり、お気に入りの場合は、1分間クラップボタンを押してください。これにより、他のVoAGIユーザーに対して投稿が可視化されます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
