「効果的なマーケティング戦略開発のための機械学習の活用」
機械学習によるマーケティング戦略開発の活用
MLを使用したマーケティング戦略の成功に向けたヒントとトリック

マーケティングのアトリビューションモデルは、現在広くマーケティング戦略の構築に使用されています。これらの戦略は、すべての顧客の経路に沿って各タッチポイントにクレジットを割り当てることに基づいています。さまざまな種類のモデルがありますが、これらは2つのグループに分類することができます:シングルタッチアトリビューションモデルとマルチタッチアトリビューションモデルです。通常、これらのモデルは簡単に解釈および実装できます。稀なケースでは有用かもしれません。しかし、ほとんどのモデルは独自で堅牢なマーケティング戦略を構築することができません。問題は、これらのすべてのモデルが、特定のデータ/産業には適用できない可能性のあるルールに基づいて動作するか、または貴重な洞察を失うことにつながる限られたデータに依存しているという事実にあります。マーケティングアトリビューションモデルの種類について詳しくは、以前の記事をご覧ください。
今日は、機械学習を利用してマーケティング戦略を開発し、使用したデータ、および得られた結果について説明したいと思います。この記事では、以下の質問について取り上げます:
- データを入手するのに最適な場所はどこですか?
- モデルトレーニングのためにデータを準備する方法は?
- モデルの予測を効果的に活用し、有意義な結論を導く方法は?
私は、いくつかの部分を修正したうえで、クライアントのデータを使用してこれらすべてを提示します。これらの修正は、全体的な結果に影響を与えません。この会社をXYZと呼ぶことにしましょう。このデータの公開はクライアントの許可を得ています。
データ
ウェブサイトからトラフィックログを取得する方法はいくつかあります。これらの方法は、分析に必要な包括的な情報を常に提供するわけではありません。ただし、場合によっては1つのソースを別のソースに統合することができることもあり、また別の場合には複数のソースからデータを手動で蓄積および結合することができることもあります。必要な情報を収集するために自分でスクリプトを作成することもできます。では、現在需要のある最も一般的なソースについて少し話しましょう。これらのソースから取得できるデータについて説明します:
- PIDコントローラの最適化:勾配降下法のアプローチ
- あなたの製品の開発者学習のためのLLM(大規模言語モデル)
- 「WebAgentに会いましょう:DeepMindの新しいLLM、ウェブサイト上での指示に従ってタスクを完了する」
Google Analytics
Google Analytics(GA4)は、さまざまなウェブサイト分析ツールへのアクセスを提供し、アプリやウェブサイト全体のエンゲージメントとトラフィックを計測するための強力なプラットフォームです。通常、最後のクリックのアトリビューションを使用しますが、以下のGA4データを収集し、独自のMLアトリビューションモデルを構築することもできます:
- 自動イベント(ad_click、ad_impression、app_exception、file_download、first_visit、page_viewなど);
- 強化測定(scroll、click、video_start、video_progressなど);
- 推奨イベント(add_to_cart、begin_checkout、add_payment_info、purchase、add_to_wishlistなど);
- カスタムイベント。
Google Analyticsは、さまざまな業界向けにさまざまなイベントを提供しています。
Meta Pixel
Meta Pixelは、ウェブサイト上での広告プロモーションと訪問者のアクティビティを追跡するツールです。FacebookやInstagramの広告との相互作用や、広告をクリックした後のユーザーのウェブサイト上の行動に関するデータを提供します。一般的には、Google Analyticsを使用する場合と同じデータが得られます。ただし、Meta Pixelはリターゲティングにより焦点を当てているため、Google Analyticsと比較してそれに対するツールがより多く提供されます。
Yandex Metrika
Yandex Metrikaは、上記のサービスと同様の機能を持っています。ただし、利点と欠点があります。デメリットとしては、Yandex Metrikaは1つのアカウントからの処理リクエストの制限(1日当たり5,000リクエスト)があります。一方、Google Analyticsの制限は1日当たり200,000リクエストです。利点としては、Yandex MetrikaにはWebvisorがあり、マウスの動きをすべて取得できるという点です。
すべての利用可能なサービスはここに挙げたものだけではありませんが、各データソースに多くのデータの種類が表現されています。したがって、データソースを選ぶ際には、レポートの設定の容易さや他の製品との統合などの要素に注意を払うことができます。私たちは、包括的なデータと便利なツールを提供しているGoogle Analytics(GA4)を選びました。また、データはBigQueryと簡単に統合でき、Google Cloudのインフラストラクチャを利用しています。したがって、元のデータは次のようなものです:
データの準備
手に入れたタスクに戻りますが、予算配分の経費を削減しながら収益を維持または増加させるために、どの広告キャンペーンが投資により魅力的であるかを判断したいと考えています。そのため、GA4データの表現は便利です。なぜなら、以下のようなユーザのアクション/タッチポイントに関する情報を含んでいるからです:
- ボタンのクリック
- スクロール
- 写真の閲覧
- 検索など
さらに、これらのアクションはさらにマイクロコンバージョンに変換することができます。マイクロコンバージョンは私たちが必要としているものです。このセットのマイクロコンバージョンを使用して、各セッションでユーザが購入する可能性を予測します。
このようなタスクを解決する際に、以下のマイクロコンバージョンが興味深いです:
- セールページの訪問
- 人気または主要な製品の閲覧
- 特定のサイズの検索
- 製品写真の閲覧
- すべての製品写真の閲覧
- 製品のケア情報の確認
- ショッピングカートに商品を追加など
実際には、独自に任意の数のマイクロコンバージョンを考えることができます。マイクロコンバージョンの選択は、ストア/ビジネスの具体的な特性に大きく依存します。
最終的に、モデルのための以下の特徴とマイクロコンバージョンを決定しました。すべての特徴の総数は97です。これは私たちの特徴のサブセットです:
UTMに関連する多くの特徴が表示されますが、それらの意味は以下のとおりです:
- utm_sourceはVoAGIの作成に使用されるプラットフォームまたはツールの名前です。
- utm_VoAGIはトラフィックのタイプまたは上位チャネルを識別します。
- utm_campaignはマーケティングキャンペーンの名前です。
- その他のutm特徴は、ユーザジャーニーまたはセッション内の最初のタッチポイントを参照します。
他の特徴の議論に戻りましょう。いくつかの列は生データで利用可能ですので、何もする必要はありません。ただし、いくつかの列は使用する準備ができていないため、最初にいくつかの操作を行う必要があります。例として、ショッピングカートに商品を追加するなどのマイクロコンバージョンをどのように取得したかを示します:
モデル
モデルを使用して、各タッチポイントでのユーザが購入する確率を求めたいと思います。それから、これをセッション内での購入確率に変換します。そのため、私たちはpredict_probaを使用した分類モデルを使用しました。線形からブースティングまでいくつかのモデルを試した後、私たちはCatBoostClassifierを使用することに決定しました。モデルのデプロイと毎日の再学習の前に、ハイパーパラメータのチューニングを行いました。モデルの作成の詳細については割愛しますが、ハイパーパラメータのチューニング、後続のモデルトレーニング、および関連するメトリクスの計算に従ったクラシックなアプローチを取りました。
現在、モデルは1ヶ月のデータを使用してトレーニングされています。長い期間や短い期間に変更しても、大幅な改善は見られませんでした。さらに、購入を決定するためのしきい値として0.1を使用しています。この値は、クライアントのベースラインの購入確率よりも10倍高いため、これらのイベントを考慮し、購入が行われたかどうか、されなかった場合はなぜかを調査するためのトリガーとして機能します。言い換えると、モデルの確率が0.1よりも高いアクションは購入と分類されます。その結果、リコールと正確さのメトリクスには以下の値が得られました:
テストのリコール:0.947テストの正確さ:0.999得られたメトリクスに基づくと、まだいくつかの購入が抜けていることがわかります。これらの購入へのパスが通常のユーザジャーニーと異なる可能性があります。
したがって、特徴とモデルの確率がすべて揃ったので、今度はレポートを作成し、どの広告キャンペーンが過小評価されているか、どれが過大評価されているかを理解したいと思います。広告キャンペーンを取得するために、utm_source、utm_VoAGI、およびutm_campaignの特徴を組み合わせます。次に、各ユーザセッション内で最大の確率を取り、それをテストデータセットと同じ期間の平均注文価値と乗算します。その後、各広告キャンペーンの合計を計算してレポートを生成します。
以下のレポートが得られます:
今度はマーケティング指標に移りましょう。マーケティングキャンペーンの成功を測定したいので、通常マーケターが使用する以下の指標を考慮することができます:
- ROAS(Ad Spendに対する収益)は、デジタル広告キャンペーンの効果を測定するマーケティング指標です;
- CRR(Cost Revenue Ratio)は、事業によって生成された収益に対する運営費の比率を測定します。
これらのデータを使用して計算し、通常マーケターが最後のクリックに基づいて取得するROASとCRRの値と比較します。
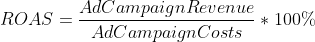
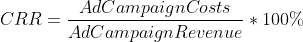
分析期間内で課金キャンペーンが3つしか表示されないため、これらのキャンペーンの指標をGA4で見つけ、最後のクリックに基づいたROASとCRRを追加します。なぜなら、最後のクリックに基づいたアプローチは広告キャンペーンの貢献を評価するための正確な手法ではないと前の記事で議論しました。
そして、上記で言及された数式を使用して、予測されたROASとCRRを使用して最終レポートを計算します:
広告キャンペーンについての結論を導くためのすべてのデータが揃いました:
- キャンペーン“google/cpc/mg_ga_brand_all_categories_every_usa_0_rem_s_bas”は過大評価されています。予測されたROASは、最後のクリックに基づいたROASよりも2倍低いです。おそらく、ユーザーはこの広告キャンペーンをクリックした後に購入を行うことが多いですが、彼らは既にウォームカスタマーです。
- 広告キャンペーン“instagram / cpc / 010323_main”は過小評価されています。予測されたROASは事実のROASよりも4倍高いです。
- そしてキャンペーン“google / cpc / mg_ga_brand_all_categories_every_latvia_0_rem_s_bas”は、予測されたROASと実際のROASが似ています。
そして、このデータを使用して、次の期間のためのマーケティング戦略を独自に開発することができます。また、マーケティング戦略はテストを必要とすることを忘れないでください。ただし、それは私たちの記事の範囲外です。
この記事では、機械学習を使用してマーケティング戦略を構築する方法について説明しました。データの選択、モデリングのためのデータの前処理、モデリングプロセス自体、そして得られた結果からの洞察について触れました。同様のタスクに取り組んでいる場合、あなたが利用している手法も興味深いものになるでしょう。
読んでいただきありがとうございました!
今日共有された洞察が役に立ったことを願っています。もし私に連絡を取りたい場合は、LinkedInで私を追加していただくことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






