「機械学習が位置データ産業において革命を起こす方法」
機械学習と位置データの革命方法
位置データはユニークな洞察を提供できますが、コストとプライバシーの問題があります。機械学習はこれらの欠点を克服し、位置データ製品を改善することができます。
位置データ業界は急速に成長していますが、まだ技術的に未熟です。位置データを基にした多くの製品は、技術的には比較的シンプルで、実装された記述統計(例:店内で見られるデバイスの平均数)や、最悪の場合、位置データそのものと見なすことができます。機械学習は、コストの削減、製品の品質向上、プライバシーの向上によって、この業界に多くの価値をもたらすことができます。
この記事では、機械学習がコストを削減し、プライバシーを向上させることで、より堅牢な位置データ製品を提供する方法について、高レベルで直感的な概要を提供することを目指しています。
はじめに
位置データ業界とプライバシー
位置データ業界は、顧客にユニークな洞察を提供できる製品を提供する急速に成長しているビジネス領域です。位置データに基づく特定の製品により、企業は、競合他社の店舗に何人の人々が訪れるか、顧客がどこから来ているか、どれだけの人々がある地域から別の地域に移動したかなどを分析することができます。しかし、位置データを扱うことは決して簡単ではなく、1つの大きな問題があります:プライバシーです。
位置データを扱う際には、他の技術的およびデータ関連の問題に加えて、個人のプライバシーが最も重要であり、長期的にはおそらくこの業界で最も困難な問題となります。位置データが携帯電話からのGPSデータ、Telcoデータ、または衛星画像であるかどうかは関係ありません。位置データの本質は場所を明らかにすることであり、シンプルな製品(生データまたは集計データ)は逆解析の可能性を排除せず、したがって、誰かのプライバシーを侵害する可能性があります。
- 「openCypher* はどんなリレーショナルデータベースに対しても使えます」
- 「データ構造とアルゴリズムにおける双方向連結リスト」
- 「グリオブラストーマ患者におけるMGMTメチル化状態を予測するための機械学習アプローチ」
ユニークな識別子をハッシュ化したり、緯度と経度を曖昧化したり、データを集計するなどの「プライバシーに配慮した」データ変換でも、逆解析を不可能にすることはほとんどありません。さらに、第三者の企業がその位置データを完全にプライバシーに配慮した方法で集計している場合でも、個別に識別可能なデータは既にデジタルでその企業に送信されており、この機密データはもはや第一当事者のデータ所有者または個人によって制御されていません。
したがって、位置データ業界の将来は、第1当事者データ側でのデータの早期集約(識別不可能な形式で)と、これらの集約データの上に機械学習を利用して高品質な人間の移動性の洞察を作り出す組み合わせにあります。
位置データ業界の現状
位置データに基づくほとんどの製品は、人間の移動性に関する洞察を提供し、比較的シンプルな技術的手法に基づいています。たとえば、店舗へのフットトラフィックを推定する製品の一般的なワークフローは次のようになります:
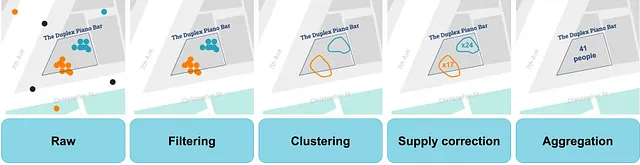
業界内のより洗練された製品では、自宅や職場、地域の人口統計などのより多くのコンテキストが提供されます。しかし、フローは常に同じです:まず、生データを前処理し、個々のデータポイントを居住イベントにクラスタリングし、データの技術的な問題を修正し、エリア内のすべての居住イベントを集計します。
このアプローチはシンプルですが効果的です。特に時間の経過にわたるパターンに興味がある場合、非常に正確な徒歩通行量の推定が可能です。技術的な洗練さとほとんど独自の部分は、シンプルな集計に対する供給の修正にあります。供給に関連する基本的な問題によって、シンプルな集計は非常に影響を受けます。供給量のわずかな変化でも、適切な修正なしに集計データ製品には大きな悪影響を及ぼす可能性があります。したがって、品質の高いデータ製品には自動化された供給の修正が不可欠です。
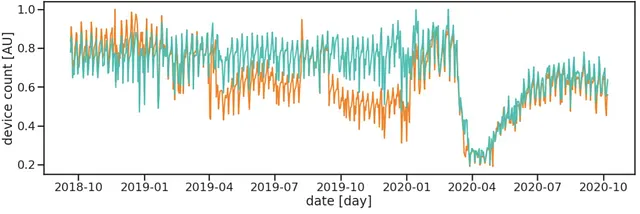
ただし、供給の修正は機能しますが、重要な制約も存在します。いくつかの制約は次のとおりです:
- 供給は絶えず変化し、改善や新しい製品バージョンが必要です。
- 時間の経過に伴うデバイスレベルのデータの取得と保存には高いコストがかかります。
- ますます多くの位置データが操作され、再生され、さらには偽造され、製品の品質に影響を与えています。
- データを扱うことに対する一般的な評判は低く、プライバシーの理由から利用可能なデータの量が減少しています。
そのため、将来的には、生の形式の位置データを購入し、何らかの派生物として再販する一般的な設定は持続可能な道ではありません。既存の位置データ製品の堅牢性と品質が低下します。
第一当事者側でのデータの集約は、上記の制約を解消し、全員にとってのWin-Winを提供しますが、既に集約されたデータを基にした製品をどのように構築することができるのでしょうか?データの重複排除、データの場所への割り当て、店舗への徒歩通行量の推定はどのように行われるのでしょうか?その答えは機械学習です!
機械学習とは何か
AIと機械学習の基礎については、さまざまな優れた紹介(例えばこの1つ)があり、簡単なインターネット検索(またはLLMに尋ねる)でこのストーリーに比べてより良い答えが得られます。ただし、超直感的で簡単にするために:
機械学習は、人間の介入なしでデータ間の関係を学習する人工システムを可能にします。
シンプルな現実の比較として、犬が褒美をもらうたびに足を上げることを学ぶ古典的な条件付けが挙げられます。この「足を上げる」と「報酬」との関係は、簡略化された形で機械が学ぶ人工システムです(ただし、犬は人間が今までに作り上げたどんなAIシステムよりも知能が高いです)。
重要な点は、入力特徴の数が1つに制限されていないことです。実際には、機械学習では通常、多くの特徴を使用して堅牢な関係を学習します。利点は多岐にわたります。例えば、第一当事者データプロバイダからの集計データの問題を考えると、機械学習を使用することで、それらの集計データと推定したい目標(例:店舗への徒歩通行量)の関係を学習することができます。
位置データを使用した機械学習の方法
店舗への徒歩通行量の推定
より直感的にするために、ここではモバイルデバイスからのGPSデータを使用したケーススタディを選択します。目的は、特定の店舗を毎日訪れた人数をお客様に通知する信頼性の高い製品を開発することです。これは、競合他社の店舗のパフォーマンスやサイト選定に興味がある企業にとって非常に有用な洞察です。
最新の方法論の現状
現在、GPSデータを基に店舗のトラフィックを推定する企業は、生のGPSデータに基づいて直接推定するか、その生データを集約して供給の変動を補正する方法を使用しています。ただし、以下に示すように、これらの2つのアプローチは、関心のある店舗内でデータが観測された後にのみ機能します。
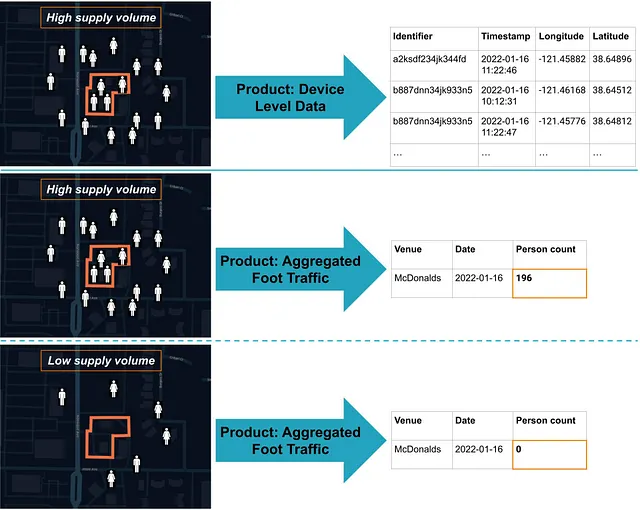
製品に十分なデータ量がある場合、デバイスレベルと集約の両方の製品手法は機能し、主な懸念事項はデータプライバシー、供給変動、コスト、およびデータ供給への信頼性に関するものです。
ただし、データ量が少ない場合や店舗が一般的に市場シェアが低い地域にある場合、単純な集約では製品ができないため、「0」のカウントになることがあります。利用可能な場所データの一般的な減少を考慮すると、これは既に業界の問題です。
機械学習モデルを使用して足の交通量を推定する
以前の例からの条件づけの例を念頭に置いて、機械学習モデルは単純に条件間の関係を学習します。犬が足を上げると報酬がもらえると学習するのと同様に、機械学習モデルは、会場に近い人が多ければ、会場内にも多くの人がいる可能性が高いことを学習することができます。
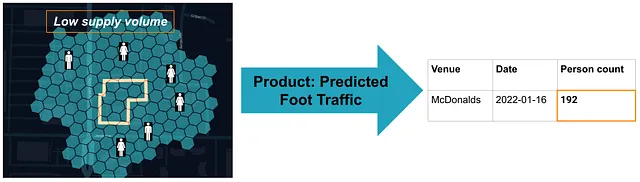
言い換えると、機械学習の目的は、店舗内の足の交通量が店舗外の交通量の変動に基づいてどのように変化するかを示す関係(またはモデル)をトレーニングすることです。例えば、ある土曜日にグランドオープニングがあり、通常の土曜日よりも2倍の人々が店舗に近くいる状況になったとします。その場合、店舗にもっと多くの人々が入店する可能性が非常に高いです。
もちろん、店舗外の足の交通量と店内の交通量の関係は必ずしも直線的である必要はありません。しかし、モデルが学習するための唯一の関係でもありません。測定できる店舗の交通量に影響を与える他の要素を考えてみてください。実際には、店舗の交通量に関連するすべてのデータはモデルの品質を向上させます。降水量、地域の人口、人口統計学、曜日、祝日など、これらの関係を向上させるいくつかのデータセットがあります。
機械学習は、これらのさまざまなデータセットを使用して、店舗の周囲を説明するデータに基づいて店舗内の足の交通量がどのように変化するかを説明する単一のモデルを作成することができます。
完璧なものはないので、メリットとデメリットは何ですか?
機械学習には多くの可能性があるものの、すべてを解決できるものではなく、対処する必要がある制約もあります。
歴史的なバイアス。トレーニングされた関係は通常、ある種の歴史的な事実に基づいています。つまり、最終的な製品は歴史的な関係に大きく影響を受けます。しかし、関係が変わる場合、モデルは再トレーニングが必要であり、予測が最新の状態に保たれ、漂流しないようにする必要があります。
予測できないこともあります。AIの現在の進展により、機械学習はほとんどすべての問題の解決策のように見えますが、予測できないことも多いことを念頭に置くことが重要です。パンデミックを予測し、店舗への影響を予測するモデルは存在しません。さらに、モデルはトレーニングデータに存在しなかったイベントや行動、またはそのデータ内に関係がないものを予測することはできません。
考え方の変化。結果として得られる製品は同じように見えるかもしれませんが、それらは基本的に異なる方法論に基づいています。これにより、商業側と製品ユーザーの両方に課題が生じ、利点と欠点が適切に対処される必要があります。
ただし、機械学習の制約を公に認識し、適切に教育すると、利点は欠点を上回るでしょう。
倫理的かつプライバシーに配慮した製品。機械学習を1stパーティの集計データと組み合わせることで、厳格な倫理基準に従った将来に向けたプライバシーに配慮した製品の構築が可能となります。
堅牢で品質の高い製品。GPSデータソースに直接依存しない場所データ製品を構築することで、製品はより堅牢で信頼性の高いものとなります。さらに、製品はさまざまな高品質なデータソースに基づくことができるため、平均してより高い品質の製品が提供されます。
データ量とコストの低減。機械学習は、現在の場所データ製品の構築に必要なデータと比較して、はるかに少ないデータで動作することができます。これにより、供給源の独立性が確保されるだけでなく、膨大なデータの不必要な保存もなくなります。さらに、機械学習インフラストラクチャによるデータ処理およびメンテナンスのコストは比較的安価です。
新製品の革新。改善されたプライバシーに続いて、最も大きな利点の一つは新製品の革新の可能性です。機械学習は、異なるデータセットとコンテキストを組み合わせることができるため、現在の場所データ産業では利用できない製品を構築することが可能です。
概要
場所データ産業は急速に成長していますが、まだ初期段階にあります。場所データに基づくほとんどの製品はシンプルで堅牢ではなく、プライバシーも不足しています。機械学習に基づく手法は、コストの削減、製品品質の向上、プライバシーの強化により、この産業に追加の価値をもたらす潜在能力を持っています。Unacastでは、早期のデータ集約を非識別形式で行い、これらの集計データの上に機械学習技術を組み合わせることで、高品質な人間の移動性に関する洞察を創造することで、場所データ産業の未来があると信じています。
すべての画像は、特に記載がない限り、著者によるものです。
私についてもっと知りたい場合や、私が何について書いているのか知りたい場合は、こちらをご覧いただき、どうぞご自由にフォローしてください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- VoAGIニュース、7月26日:Googleによる無料の生成AIトレーニング•データエンジニアリング初心者ガイド•GPT-Engineer:あなたの新しいAIコーディングアシスタント
- 「ChatGPTにおける適切なプロンプト設計の必須ガイド」
- CleanLabを使用してデータセットのラベルエラーを自動的に検出する
- DLISファイルからLASファイル形式へのウェルログデータの変換
- query()メソッドを使用してPandasデータフレームをクエリする方法
- データサイエンスのキャリアに転身する際に comitted した5つのミステイク
- 「GANの流行 | ファッション画像生成のステップバイステップガイド」
