最初のマシンアンラーニングチャレンジを発表します
最初のマシンラーニングチャレンジを発表します
Googleの研究科学者であるFabian PedregosaとEleni Triantafillouによって投稿されました。
深層学習は最近、現実的な画像生成や印象的な検索システムから、人間のように会話をすることができる言語モデルまで、さまざまなアプリケーションで大きな進歩を遂げています。この進歩は非常に興味深いものですが、深層ニューラルネットワークモデルの広範な使用には注意が必要です。GoogleのAI原則に従って、私たちはフェアなバイアスの伝播と増幅、ユーザーのプライバシーの保護などの潜在的なリスクを理解し、軽減することにより、責任を持ってAI技術を開発することを目指しています。
削除されるデータの影響を完全に消去することは難しいです。データが保存されているデータベースから単純に削除するだけでなく、そのデータがトレーニングされた機械学習モデルに与える影響も消去する必要があります。さらに、最近の研究 [1, 2] は、メンバーシップ推論攻撃(MIA)を使用して、例が機械学習モデルのトレーニングに使用されたかどうかを非常に高い精度で推論することが可能であることを示しています。これはプライバシー上の懸念を引き起こす可能性があります。つまり、個人のデータがデータベースから削除されたとしても、その個人のデータがモデルのトレーニングに使用されたかどうかを推測することができる可能性があるということです。
上記の理由から、機械学習のサブフィールドである機械アンラーニングは、トレーニング例の特定のサブセットである「忘れるセット」の影響をトレーニング済みのモデルから除去することを目指しています。さらに、理想的なアンラーニングアルゴリズムは、特定の例の影響を除去する一方で、トレーニングセットの残りの部分における精度と保持例への一般化など、他の有益な特性を維持することができるようになっています。このアンラーニングされたモデルを生成するための直接的な方法は、忘れるセットのサンプルを除外した調整されたトレーニングセットでモデルを再トレーニングすることです。しかし、これは常に実行可能なオプションではありません。なぜなら、深層モデルの再トレーニングは計算コストが高いからです。理想的なアンラーニングアルゴリズムは、既にトレーニングされたモデルを出発点として使用し、要求されたデータの影響を効率的に除去するために調整を行うことができるでしょう。
- 今年学ぶ価値のある最高報酬の言語5選
- 3Dで「ウォーリーを探せ」をプレイする:OpenMask3Dは、オープンボキャブラリークエリを使用して3Dでインスタンスをセグメント化できるAIモデルです
- Explainable AI(説明可能なAI)とInterpretable AI(解釈可能なAI)の理解
今日、私たちは幅広い学術研究者と産業研究者のグループと協力して、初のマシンアンラーニングチャレンジを開催することを発表できて大変嬉しく思っています。このコンテストは、トレーニング後に特定のトレーニングイメージのサブセットを忘れる必要がある現実的なシナリオを考慮しています。コンテストはKaggleで開催され、忘れる品質とモデルの有用性の両方に関して自動的にスコアリングされます。このコンテストがマシンアンラーニングの最先端の技術の発展に貢献し、効率的で効果的かつ倫理的なアンラーニングアルゴリズムの開発を促進することを願っています。
マシンアンラーニングの応用
マシンアンラーニングは、ユーザーのプライバシー保護以外にも応用があります。例えば、トレーニングされたモデルから不正確な情報や古い情報を消去するためにアンラーニングを使用することができます(例えば、ラベリングのエラーや環境の変化によるもの)。また、有害な、操作された、または外れ値のデータを削除することもできます。
機械アンラーニングの分野は、ディファレンシャルプライバシーやライフロングラーニング、フェアネスなどの機械学習の他の分野と関連しています。ディファレンシャルプライバシーは、特定のトレーニング例がトレーニングされたモデルに与える影響が大きすぎないことを保証することを目指しています。これはアンラーニングの目標と比較して強い目標です。ライフロングラーニングの研究は、以前に習得したスキルを維持しながら連続的に学習できるモデルを設計することを目指しています。アンラーニングの研究が進展するにつれて、不公正なバイアスや異なるグループ(人口統計、年齢層など)のメンバーへの不公平な扱いを修正することによって、モデルのフェアネスを向上させる追加の方法も開かれるかもしれません。
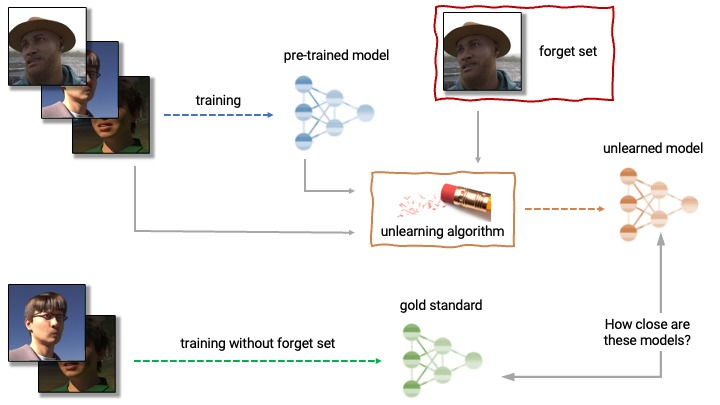 |
| アンラーニングの解剖学。アンラーニングアルゴリズムは、事前にトレーニングされたモデルとトレーニングセットから1つ以上のサンプル(「忘れるセット」)を入力として受け取ります。アンラーニングアルゴリズムは、モデル、忘れるセット、保持セットから更新されたモデルを生成します。理想的なアンラーニングアルゴリズムは、忘れるセットなしでトレーニングされたモデルと区別できないモデルを生成します。 |
機械のアンラーニングの課題
アンラーニングの問題は複雑で多面的であり、いくつかの相反する目標を含んでいます。要求されたデータを忘れること、モデルの有用性(保持および保留データの正確さ)を維持すること、効率性を維持することなどです。そのため、既存のアンラーニングのアルゴリズムは異なるトレードオフを行います。たとえば、完全な再学習はモデルの有用性を損なうことなく忘却を達成しますが、効率は低くなります。一方、重みにノイズを追加することで、有用性を犠牲にして忘却を達成します。
さらに、文献での忘却アルゴリズムの評価はこれまでに非常に一貫性がありませんでした。一部の研究では、忘れるサンプルの分類精度を報告しているものもありますが、他の研究では完全再学習モデルへの距離やメンバーシップ推論攻撃のエラーレートなど、忘却の品質を評価するための指標が異なります [4, 5, 6]。
私たちは、評価指標の一貫性の欠如と標準化されたプロトコルの欠如が、この分野の進歩に深刻な障害であると考えています。文献中の異なるアンラーニング手法を直接比較することができません。これにより、異なるアプローチの相対的な利点と欠点、および改良されたアルゴリズムの開発のためのオープンな課題と機会に対する狭い視野に取り残されます。このような評価の一貫性の問題に対処し、機械のアンラーニングの最先端を推進するために、私たちは広範な学術および産業の研究者グループと協力して、最初のアンラーニングチャレンジを開催することにしました。
最初のマシンアンラーニングチャレンジの発表
NeurIPS 2023 コンペティショントラックの一環として、最初のマシンアンラーニングチャレンジを開催することをお知らせいたします。このコンペティションの目標は2つあります。まず、アンラーニングの評価指標を統一し標準化することにより、異なるアルゴリズムの強みと弱点をアップル対アップルの比較によって特定することです。次に、このコンペティションを誰にでも開放することで、新しい解決策を育成し、オープンな課題と機会に光を当てることを目指しています。
コンペティションはKaggleで開催され、2023年7月中旬から2023年9月中旬まで実施されます。コンペティションの一環として、本日、スターターキットの提供を発表します。このスターターキットは、参加者がおもちゃのデータセット上で自分のアンラーニングモデルを構築してテストするための基盤を提供します。
コンペティションでは、顔画像を使って年齢予測器を訓練し、訓練後に一部の訓練画像を忘れて個人のプライバシーまたは権利を保護するという現実的なシナリオを考慮しています。そのため、スターターキットの一部として、合成顔データセット(以下のサンプルを参照)といくつかの実際の顔データセットを提供します。参加者は、訓練済み予測器、忘れるセットと保持するセットを入力として受け取り、指定された忘れるセットをアンラーニングした予測器の重みを出力するコードを提出するように求められます。私たちは、忘却アルゴリズムの強さとモデルの有用性の両方に基づいて提出物を評価します。また、再学習にかかる時間の一部よりも遅いアンラーニングアルゴリズムは拒否する厳しいカットオフを設けます。このコンペティションの貴重な成果は、異なるアンラーニングアルゴリズムのトレードオフを特徴付けることです。
 |
| 顔合成データセットからの抜粋と年齢の注釈。このコンペティションでは、上記のような顔画像に対して年齢予測器が訓練され、訓練後に特定の訓練画像の一部を忘れる必要があります。 |
忘却の評価には、LiRAなどのMIAsに触発されたツールを使用します。MIAsは、プライバシーとセキュリティの文献で最初に開発され、その目標は訓練セットの一部であった例を推測することです。直感的に言えば、アンラーニングが成功すると、アンラーニングされたモデルには忘れた例の痕跡がなくなり、MIAsが失敗するため、攻撃者は忘れるセットが実際に元の訓練セットの一部であったことを推測することができません。さらに、特定の提出されたアンラーニングアルゴリズムによって生成されたアンラーニングモデルの分布が、ゼロから再学習されたモデルの分布とどれだけ異なるかを統計的にテストすることも行います。理想的なアンラーニングアルゴリズムの場合、これらの2つは区別できません。
結論
機械のアンラーニングは、機械学習のいくつかの未解決の問題に取り組むための強力なツールです。この分野の研究が進むにつれて、より効率的で効果的かつ責任ある新しい手法が登場することを期待しています。このコンペティションを通じて、この分野への興味を喚起する機会を得て大変嬉しく思っており、私たちの洞察と発見をコミュニティと共有することを楽しみにしています。
謝辞
この投稿の著者は現在Google DeepMindの一員です。私たちはUnlearning Competitionの組織チームを代表してこのブログ投稿を執筆しています:Eleni Triantafillou*、Fabian Pedregosa*(*同等の貢献)、Meghdad Kurmanji、Kairan Zhao、Gintare Karolina Dziugaite、Peter Triantafillou、Ioannis Mitliagkas、Vincent Dumoulin、Lisheng Sun Hosoya、Peter Kairouz、Julio C. S. Jacques Junior、Jun Wan、Sergio Escalera、Isabelle Guyon。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






