小さなメモリに大きな言語モデルを適合させる方法:量子化
方法:量子化
大規模言語モデルは、テキスト生成、翻訳、質問応答などに使用することができます。しかし、LLM(Large Language Models)は非常に大きく(明らかに、大規模な言語モデルです)、多くのメモリを必要とします。そのため、携帯電話やタブレットなどの小型デバイスでは課題となる場合があります。
パラメータを選択した精度サイズで乗算すると、モデルのサイズ(バイト単位)が決まります。例えば、選択した精度がfloat16(16ビット = 2バイト)であるとします。BLOOM-176Bモデルを使用したいとします。1760億のパラメータ * 2バイト = モデルをロードするために352GBが必要です!
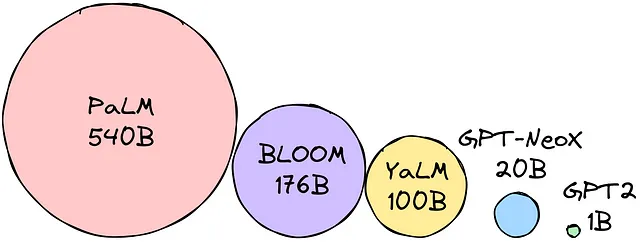
つまり、すべてのパラメータの重みをロードするためには、12(!) 32GBのマシンが必要です!これは、LLMを携帯可能にするためにはあまりにも多すぎます。LLMのメモリフットプリントを削減するための技術が開発され、このような問題を克服することができました。最も人気のある技術は次のとおりです。
- 量子化は、LLMの重みを低精度の形式に変換し、それらを格納するために必要なメモリを削減することです。
- 知識蒸留は、より小さなLLMを訓練して、より大きなLLMの振る舞いを模倣することです。これは、大きなLLMから小さなLLMに知識を転送することによって行うことができます。
これらの技術により、LLMを小さいメモリに収めることが可能となりました。これにより、さまざまなデバイスでLLMを使用する新たな可能性が広がりました。今日は、量子化について話します(知識蒸留については後ほどお楽しみに)。
量子化
簡単な例から始めましょう。2023を2進数に変換する必要があります。
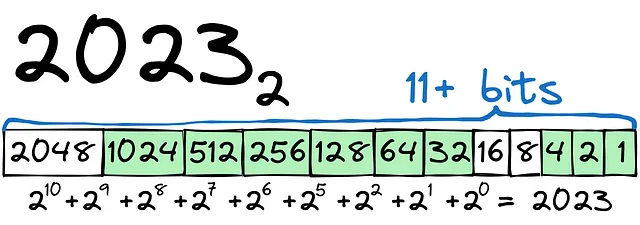
見ての通り、プロセスは比較的簡単です。数値2023を格納するには、12ビット以上のビット数が必要です(+または-の符号に1ビット)。数値にはint16型を使用するかもしれません。
整数をバイナリとして格納する方法と、浮動小数点数をそのまま格納する方法には大きな違いがあります。20.23をバイナリに変換してみましょう。
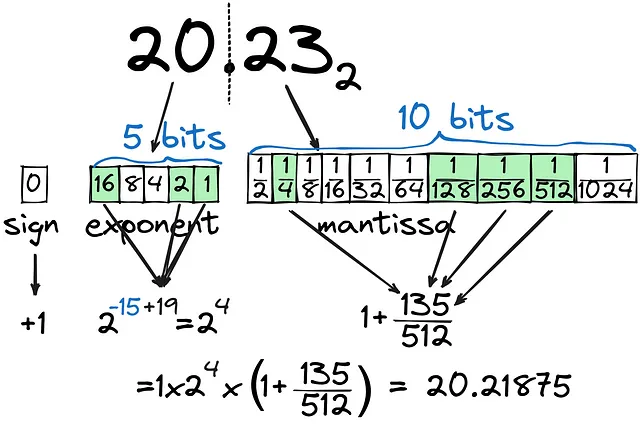
見ての通り、浮動小数点数(仮数部)は1/2^nの組み合わせとして計算され、10ビットを仮数部に割り当てても非常に正確に計算することはできません。整数部(指数部)は5ビットに設定され、32までのすべての数値をカバーしています。合計して、20.23にできるだけ近づけるために16ビット(FP16)を使用していますが、浮動小数点数を保持するために最も効果的な方法でしょうか?もし整数部の数値がはるかに大きい場合、例えば202.3の場合はどうなるでしょうか?
標準の浮動小数点数型を見ると、202.3を格納するにはFP32を使用する必要がありますが、計算の観点からは合理的ではありません。代わりに、範囲(指数部)に8ビットを、精度(仮数部)に7ビットを使用するbfloat16を使用することができます。これにより、ほとんど精度を失うことなく、可能な小数の範囲を広げることができます。
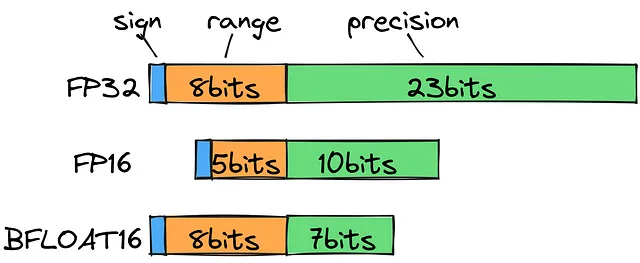
はっきり言って、トレーニング中はできるだけ精度を確保する必要があります。しかし、推論の際には速度とサイズを優先することは理にかなっています。
bfloat16からint8へのメモリ使用量を減らすことはできるでしょうか?
ゼロポイントと絶対最大量子化
実際には、そのような量子化は可能であり、いくつかのアプローチがあります:
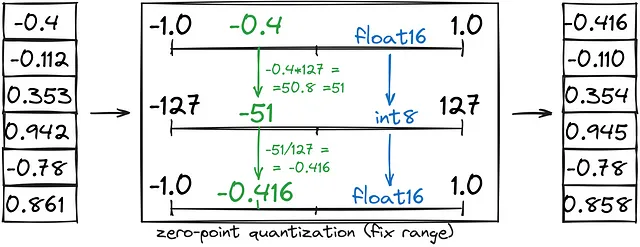
- ゼロポイント量子化は、固定範囲(-1、1)をint8(-127、127)に変換し、その後int8をbfloat16に変換することで、メモリを半分節約します。
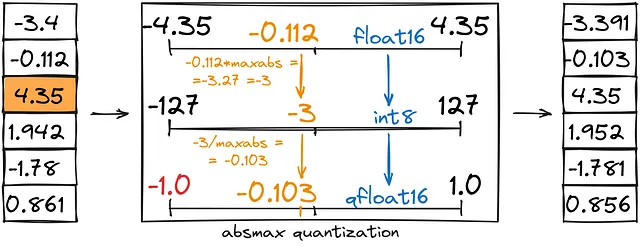
- 絶対最大値量子化はゼロポイントに似ていますが、カスタム範囲(-1、1)ではなく、(-abs(最大値)、abs(最大値))として設定します。
これらの手法が行列の乗算の例でどのように使用されるか見てみましょう:
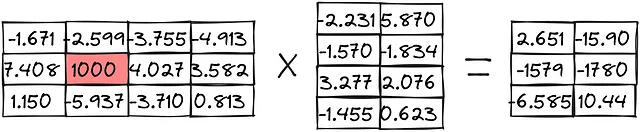
ゼロポイント量子化:

絶対最大値量子化:
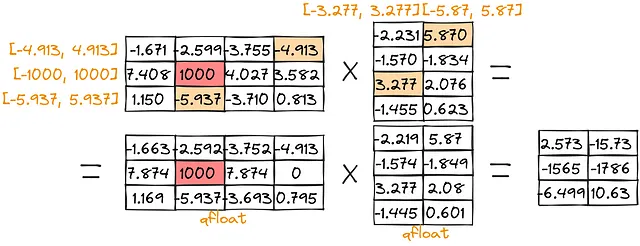
大きな値のスコア[-1579、-1780]はかなり低いことに気づくでしょう(ゼロポイントの場合は[-1579、-1752]、絶対最大値の場合は[-1565、-1786])。そのような問題を克服するために、私たちは外れ値の乗算を分離することができます:

ご覧の通り、結果は真の値により近くなります。
しかし、品質をあまり損なうことなくより少ないスペースを使用する方法はあるでしょうか?
非常に驚いたことに、そのような方法があります!各数値を独立して低い型に変換する代わりに、誤差を考慮して調整に使用することはできませんか?この技術はGPTQと呼ばれます。
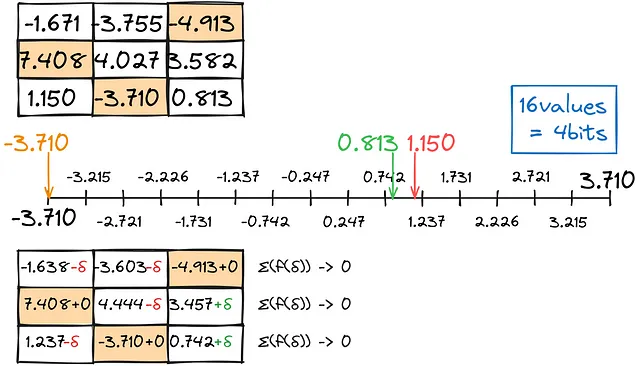
前の量子化と同様に、できるだけ合計変換エラーをゼロに近く保ちつつ、小数点以下の最も近い一致を見つけます。
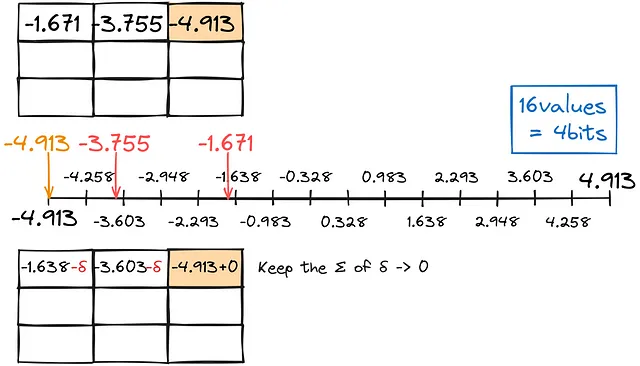
このように行列を行ごとに埋めます。
結果は、異常な計算と組み合わせることで、かなり良好な結果を提供します:
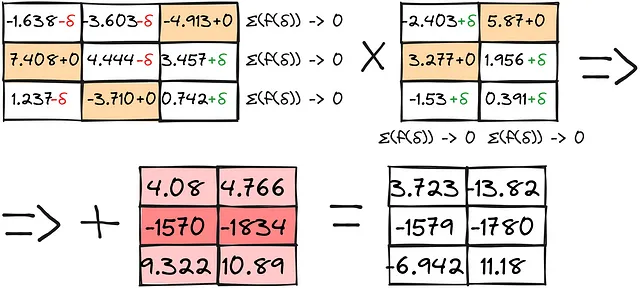
今、すべての方法を比較できます:

LLM.int8()メソッドは非常に良いパフォーマンスを発揮します!GPTQアプローチは品質を失いますが、int8メソッドよりも2倍のGPUメモリを使用することができます。
コードでは、次のようなものを見つけることができるかもしれません:
from transformers import BitsAndBytesConfig# 4ビットの量子化を行うBitsAndBytesConfigの設定bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16,)# 事前設定された構成でモデルをロードpretrained_model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config=bnb_config,)load_in_4bitフラグは、モデルを4ビットの精度でロードすることを指定します。bnb_4bit_use_double_quantフラグは、ダブル量子化を使用することを指定します。bnb_4bit_quant_typeフラグは、量子化のタイプを指定します。bnb_4bit_compute_dtypeフラグは、計算に使用するdtypeを指定します。
まとめると、メモリに10進数がどのように保存されるか、精度を失うことでメモリのフットプリントを削減する方法、選択したモデルを4ビットの量子化で実行する方法について学びました。

この記事は私のLinkedInページで公開されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






