カカオブレインからの新しいViTとALIGNモデル
新しいViTとALIGNモデルがカカオブレインからリリースされました
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。
Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。
このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです:
- 史上初のオープンソースのALIGNモデル!
- オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル
- Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します
- ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます!
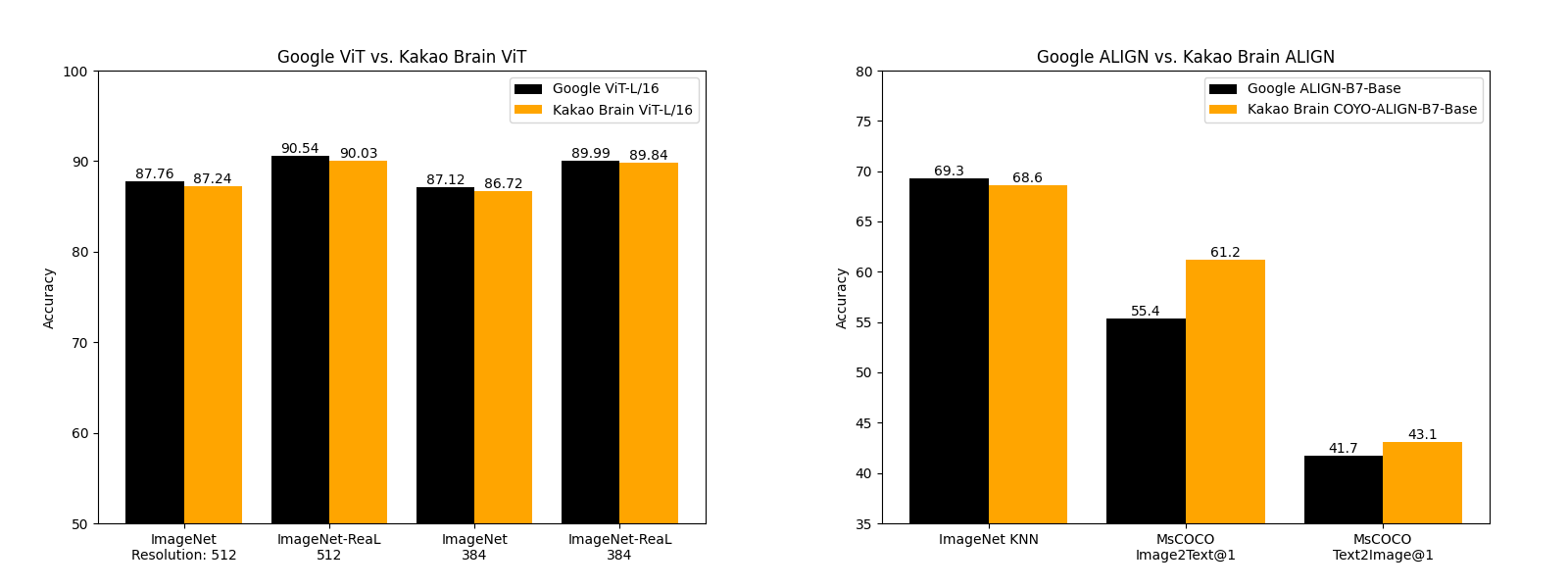
パフォーマンスの比較
Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します!
COYOデータセット

これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。 LAION 2Bは20億の英語ペアからなる大規模なデータセットであり、 COYOの700億のペアと比較して、COYOのペアにはより柔軟性と細かい制御を提供するメタデータが付属しています。以下の表には、その違いが示されています:COYOにはすべてのペアの美学的なスコア、より堅牢な透かしなどのデータが備わっています。
ViTとALIGNの動作原理
では、これらのモデルはどのように機能するのでしょうか?ViTとALIGNモデルの動作原理について簡単に説明します。
ViT(Vision Transformer)は、Googleが2020年に提案したビジョンモデルであり、テキストTransformerアーキテクチャに似ています。これは、2012年のAlexNet以来、ビジョンタスクを主導してきた畳み込みニューラルネットワーク(CNN)とは異なるビジョンの新しいアプローチです。それは、同等のパフォーマンスを発揮するCNNに比べて最大4倍計算効率が高く、ドメインに依存しません。ViTは、画像を画像パッチのシーケンスに分割して入力とし、テキストTransformerがテキストのシーケンスを入力としているのと同じように、各パッチに位置埋め込みを与えて画像の構造を学習します。ViTのパフォーマンスは、特に優れたパフォーマンスと計算トレードオフがあります。Googleの一部のViTモデルはオープンソースですが、それらがトレーニングされたJFT-300億の画像ラベルペアデータセットは公開されていません。一方、Kakao BrainのトレーニングされたCOYO-Labeled-300Mは公開されており、リリースされたViTモデルはさまざまなタスクで同様のパフォーマンスを発揮しますが、そのコード、モデル、およびトレーニングデータ(COYO-Labeled-300M)は完全に公開され、再現性とオープンサイエンスのために提供されています。
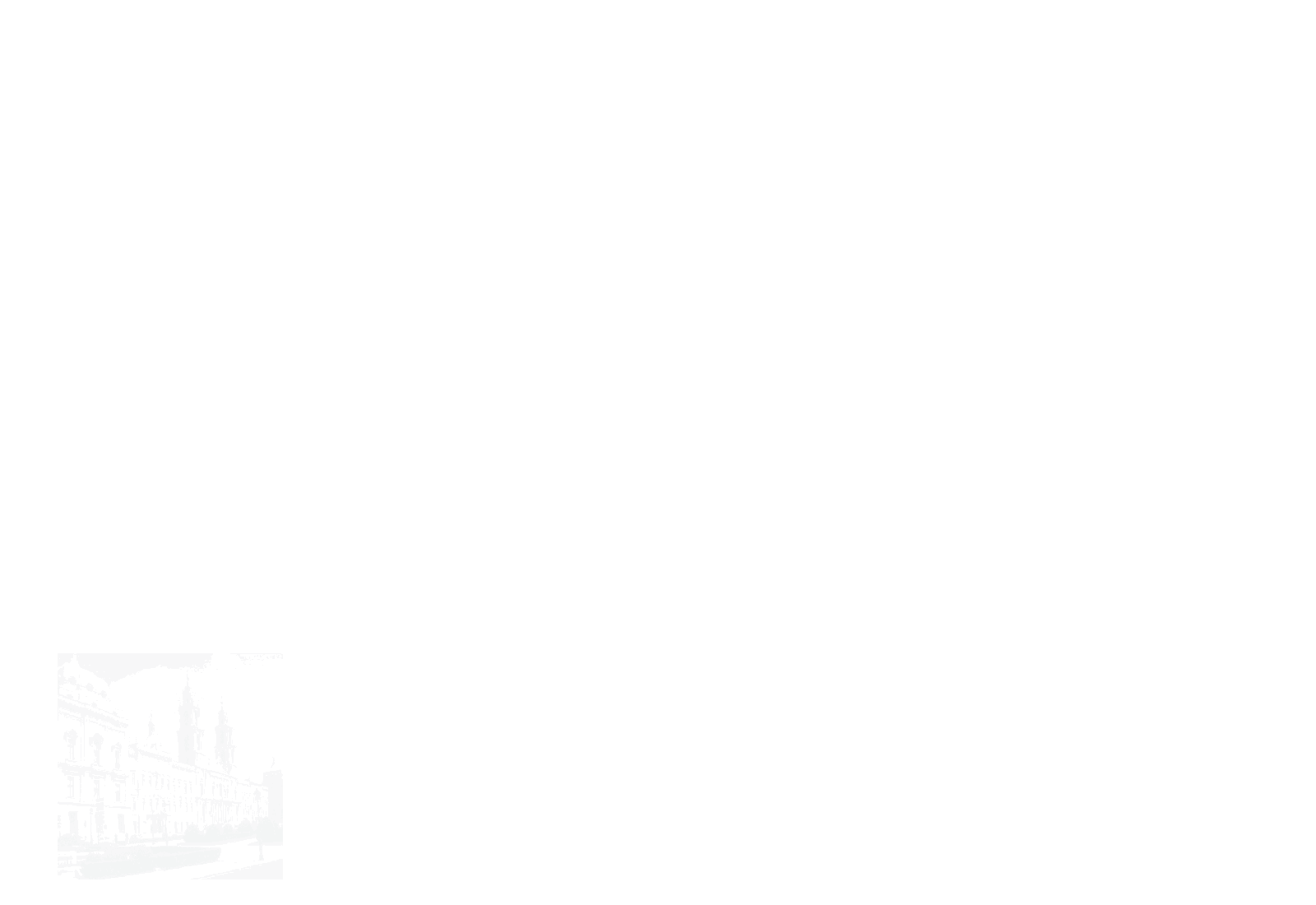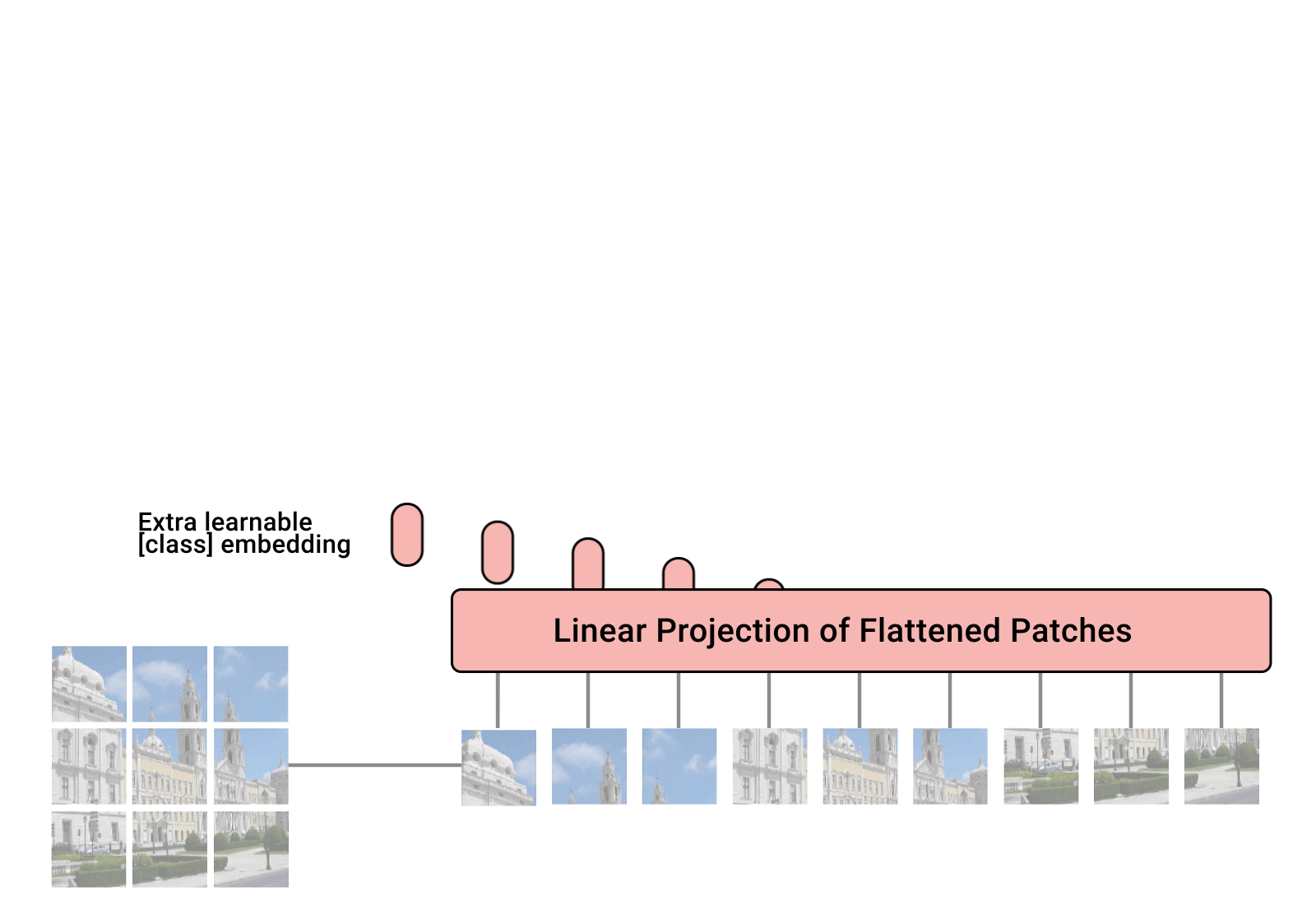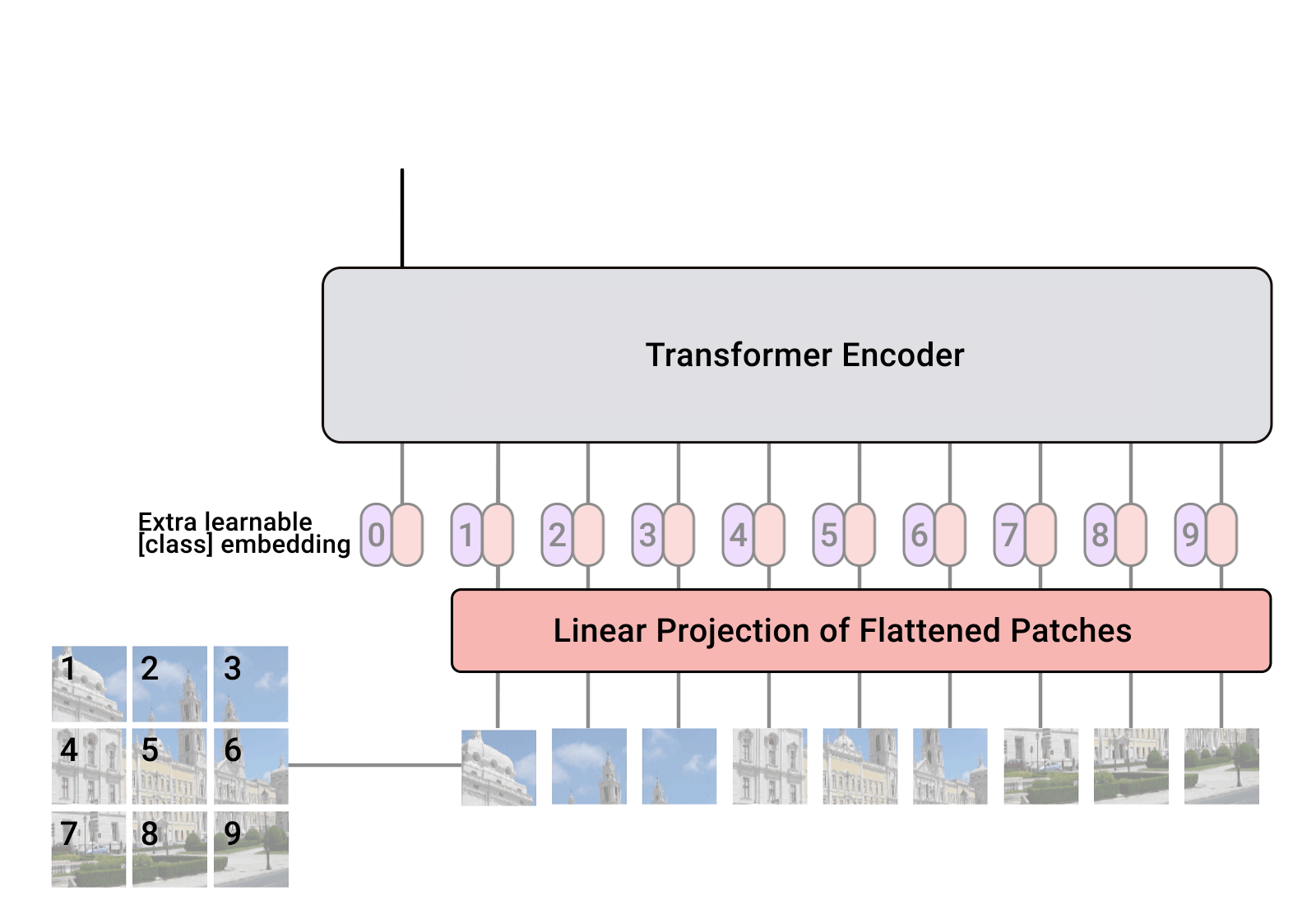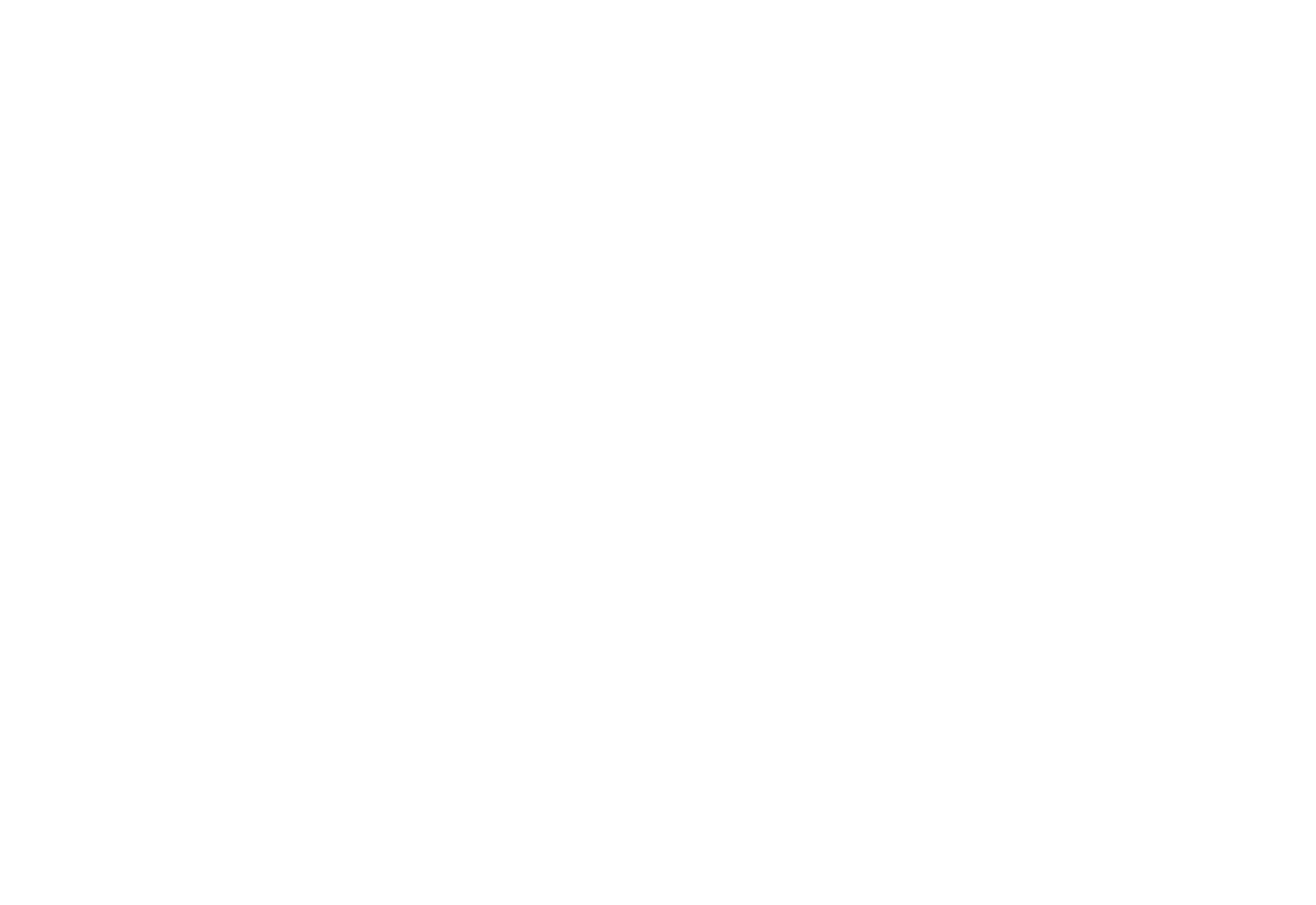
GoogleブログからのViTの動作の可視化
その後、Googleは2021年にALIGNを導入しました。ALIGNは、「ノイズのある」テキストイメージデータに対して訓練された大規模な画像およびテキストの埋め込みモデルで、テキストイメージの検索などのビジョンおよびクロスモーダルタスクのためのモデルです。ALIGNは、コントラスティブ損失関数を用いて学習された単純なデュアルエンコーダーアーキテクチャを持っています。ALIGNの「ノイズのある」トレーニングコーパスは、スケールとロバスト性をバランスさせることが特筆されます。以前には、視覚言語表現学習は、大規模なデータセットで手動のラベル付けが必要であったため、煩雑な前処理が必要でした。ALIGNのコーパスは、画像が読み込まれない場合に表示されるテキストである画像の代替テキストデータをキャプションとして使用しています。これにより、避けられないノイズを含むがはるかに大きな(18億ペア)データセットが生成され、ALIGNはさまざまなタスクでSoTAレベルのパフォーマンスを発揮することが可能になります。Kakao BrainのALIGNは、COYOデータセットでトレーニングされたこのモデルの最初のオープンソースバージョンであり、Googleの報告結果よりも優れた性能を発揮します。

GoogleブログのALIGNモデル
COYOデータセットの使用方法
🤗 Datasetsライブラリを使用して、COYOデータセットを簡単にダウンロードできます。データセットのページや元のGitリポジトリでデータキュレーションプロセスやメタ属性についての詳細を確認するには、ハブ上のデータセットページにアクセスしてください。始める前に、🤗 Datasetsライブラリをインストールしましょう:pip install datasets そして、ダウンロードします。
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m')
>>> datasetCOYOデータセットはLAIONデータセットよりはるかに小さいですが、747Mの画像テキストペアが含まれており、すべてのデータセットをローカルにダウンロードすることは実用的ではないかもしれません。データセットの一部のみをダウンロードするためには、load_dataset()メソッドにstreaming=True引数を渡すだけで、イテラブルなデータセットを作成し、データインスタンスを逐次的にダウンロードすることができます。
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
>>> print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Tuscany herbsで漬け込んだオリーブオイル', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}ハブからViTとALIGNを使用する方法
新しいViTとALIGNモデルを実験してみましょう。ALIGNは🤗 Transformersに新しく追加されたため、最新バージョンのライブラリをインストールします:pip install -q git+https://github.com/huggingface/transformers.git そして、使用するモジュールとライブラリをインポートして画像分類のためのViTで始めましょう。なお、新たに追加されたALIGNモデルは、次のライブラリのリリースに含まれる予定です。
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassification次に、COCOデータセットからランダムな2匹の猫とリモコンがソファにある画像をダウンロードし、モデルが期待する入力形式に変換するために画像を前処理します。これには、対応する前処理クラス(ViTProcessor)を便利に使用できます。モデルと前処理器を初期化するために、hubのKakao Brain ViTリポジトリのいずれかを使用します。前処理器をリポジトリから初期化することで、前処理済みの画像が特定の事前学習済みモデルが必要とする期待される形式であることが保証されます。
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')残りは簡単です。画像を前処理し、モデルの入力として使用してクラスのロジットを取得します。Kakao Brain ViT画像分類モデルはImageNetのラベルでトレーニングされており、出力は形状が(batch_size、1000)のロジットです。
# 画像または画像のリストを前処理
inputs = processor(images=image, return_tensors="pt")
# 推論
with torch.no_grad():
outputs = model(**inputs)
# ロジットにSoftMaxを適用して各クラスの確率を計算する
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# 上位5つのクラスの予測と確率を表示する
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
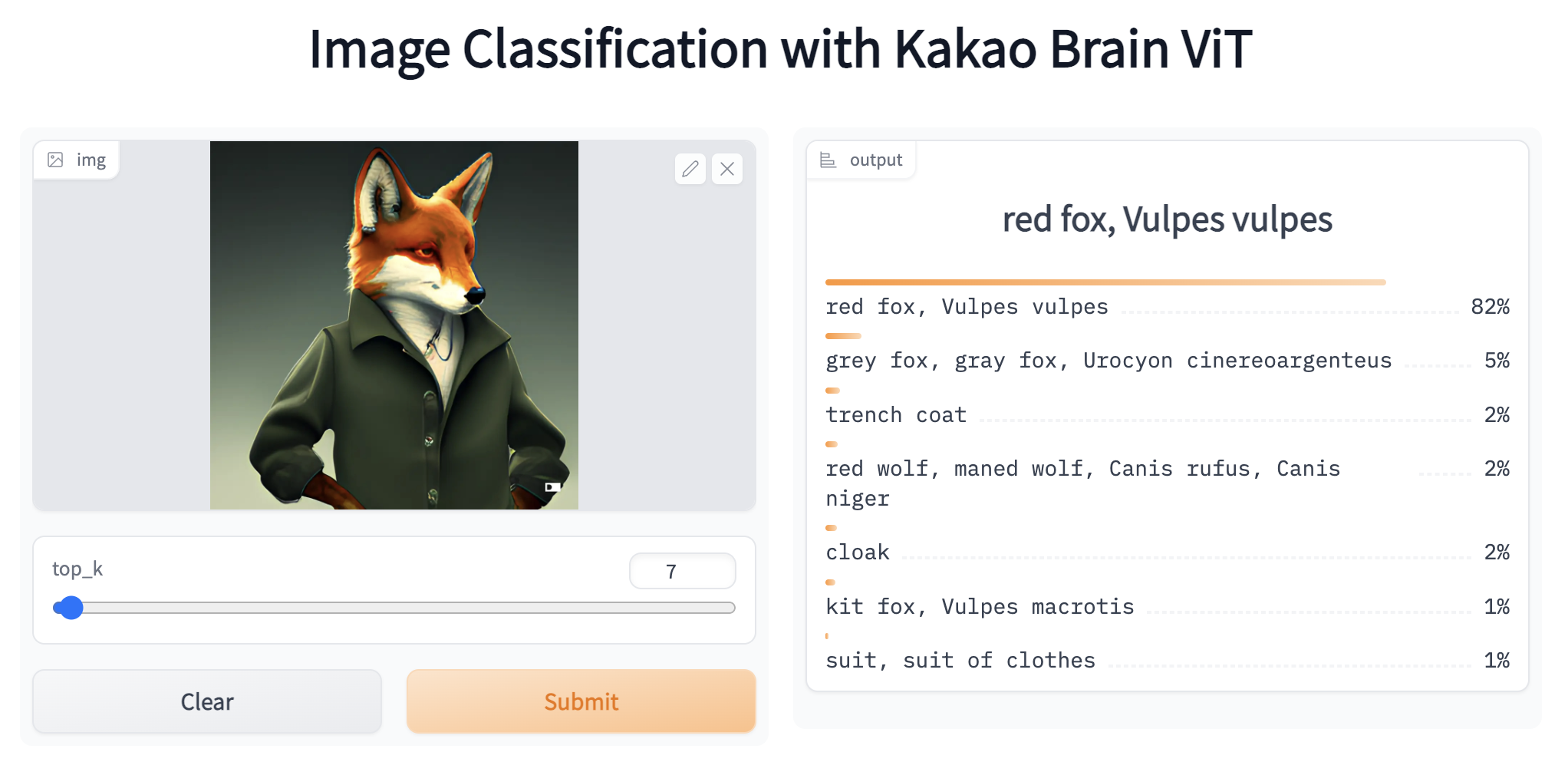
print(f"{model.config.id2label[c.item()]}の確率は{round(preds[0, c.item()].item(), 4)}")以上です!さらに簡単で短くするために、便利な画像分類パイプラインを使用し、ターゲットモデルとしてKakao Brain ViTリポジトリ名を渡すこともできます。次に、URLまたはローカルパス、またはPillow画像を渡し、オプションでtop_k引数を使用して上位k個の予測を返すことができます。猫とリモコンの画像に対して上位5つの予測を取得しましょう。
>>> from transformers import pipeline
>>> classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
>>> classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
[{'score': 0.8223727941513062, 'label': 'remote control, remote'}, {'score': 0.06580372154712677, 'label': 'tabby, tabby cat'}, {'score': 0.0655883178114891, 'label': 'tiger cat'}, {'score': 0.0388941615819931, 'label': 'Egyptian cat'}, {'score': 0.0011215205304324627, 'label': 'lynx, catamount'}]Kakao Brain ViTモデルでさらに実験を行いたい場合は、🤗 HubのそのSpaceに移動してください。
次に、テキストや画像の多モーダルな埋め込みを取得したり、ゼロショット画像分類を行ったりするために使用できるALIGNで実験を行いましょう。ALIGNのtransformersの実装と使用法はCLIPと似ています。始めるために、事前学習済みモデルとそのプロセッサをダウンロードし、画像とテキストの両方を前処理して、ALIGNのビジョンエンコーダとテキストエンコーダに入力するための期待される形式にすることができます。再び、使用するモジュールをインポートし、前処理器とモデルを初期化しましょう。
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')まず、ゼロショット画像分類から始めましょう。これには、候補のラベル(自由形式のテキスト)を提供し、AlignModelを使用して画像に最も適切な説明を見つけることが必要です。まず、画像とテキストの両方の入力を前処理し、前処理された入力をAlignModelに供給します。
candidate_labels = ['猫の画像', '犬の画像']
inputs = processor(images=image, text=candidate_labels, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# これは画像とテキストの類似度スコアです
logits_per_image = outputs.logits_per_image
# ソフトマックスを取ることでラベルの確率を取得できます
probs = logits_per_image.softmax(dim=1)
print(probs)完了です、簡単ですね。ゼロショット画像分類のKakao Brain ALIGNモデルでさらに実験するには、🤗 Hubのデモにアクセスしてください。なお、AlignModelの出力にはtext_embedsとimage_embeds(ALIGNのドキュメントを参照)が含まれます。ゼロショット分類のための画像ごとのログットとテキストごとのログットを計算する必要がない場合、AlignModelクラスの便利なget_image_features()メソッドとget_text_features()メソッドを使用してビジョンとテキストの埋め込みを取得できます。
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)また、ALIGNのスタンドアロンのビジョンとテキストエンコーダを使用して、マルチモーダルな埋め込みを取得することもできます。これらの埋め込みは、物体検出、画像セグメンテーション、画像キャプションなど、さまざまな下流タスクのモデルトレーニングに使用することができます。AlignTextModelとAlignVisionModelを使用して、これらの埋め込みを取得する方法を見てみましょう。テキストと画像を別々に前処理するためにAlignProcessorクラスを使用することもできます。
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# 2つのテキストクエリの埋め込みを取得します
inputs = processor(['猫の画像', '犬の画像'], return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# 最後の隠れ状態と最終的なプーリングされた出力を取得します
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output推論中にoutput_hidden_statesとoutput_attentions引数をTrueに設定することで、すべての隠れ状態とアテンション値を返すこともできます。
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# 返される情報を出力します
for key, value in outputs.items():
print(key)同様に、AlignVisionModelを使用して画像のマルチモーダルな埋め込みを取得することもできます。
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# 最後の隠れ状態と最終的なプーリングされた出力を出力します
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_outputViTと同様に、ゼロショット画像分類パイプラインを使用することで、作業がさらに簡単になります。自由形式のテキスト候補ラベルを使用して、野生の状態で画像分類を実行する方法を見てみましょう。
>>> from transformers import pipeline
>>> classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['動物', '人間', '風景'],
... )
[{'score': 0.9263709783554077, 'label': '動物'}, {'score': 0.07163811475038528, 'label': '人間'}, {'score': 0.0019908479880541563, 'label': '風景'}]
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['白黒', '写真のような', '絵画'],
... )
[{'score': 0.9735308885574341, 'label': '白黒'}, {'score': 0.025493400171399117, 'label': '写真のような'}, {'score': 0.0009757201769389212, 'label': '絵画'}]結論
近年、マルチモーダルモデルにおいて驚くべき進歩がありました。CLIPやALIGNなどのモデルにより、画像キャプション、ゼロショット画像分類、オープンボキャブラリーオブジェクト検出など、さまざまな下流タスクが可能になりました。このブログでは、カカオブレインによって提供された最新のオープンソースViTとALIGNモデル、そして新しいCOYOテキスト-画像データセットについて説明しました。さらに、これらのモデルを使っていくつかのコード行でさまざまなタスクを実行する方法や、🤗 Transformersパイプラインの一部として使用する方法も紹介しました。
<p以上です!私たちは引き続き最も影響力のあるコンピュータビジョンとマルチモーダルモデルを統合しており、皆様からのご意見をお待ちしております。コンピュータビジョンとマルチモーダルの最新の研究ニュースに関しては、Twitterで私たちをフォローしていただけます:@adirik、@a_e_roberts、@NielsRogge、@RisingSayak、@huggingface。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






