新しいAIの研究は、事前学習済みおよび指示微調整モデルのゼロショットタスクの一般化性能を改善するために、コンテキスト内の指導学習(ICIL)がどのように機能するかを説明しています
新しいAIの研究では、事前学習済みおよび指示微調整モデルの一般化性能を向上させるために、コンテキスト内の指導学習(ICIL)の機能について説明しています


Large Language Models (LLMs)は、few-shot demonstrations、またはin-context learningとしても知られるプロセスによって、推論中にターゲットタスクに適応できることが示されています。この能力は、モデルのサイズが拡大するにつれて、LLMsが新たな特徴を表示することでますます明らかになっています。その中でも、指示に従って未知のタスクに一般化する能力は注目されています。そのためには、Instruction tuning、またはRLHFと呼ばれる教示学習アプローチが、この能力を高めるために提案されています。しかしながら、これまでの研究は主にfine-tuningに基づく教示学習技術に焦点を当ててきました。モデルは、多くのタスクと指示に基づいてマルチタスクでfine-tuningされており、多くのバックプロパゲーション手順が必要です。
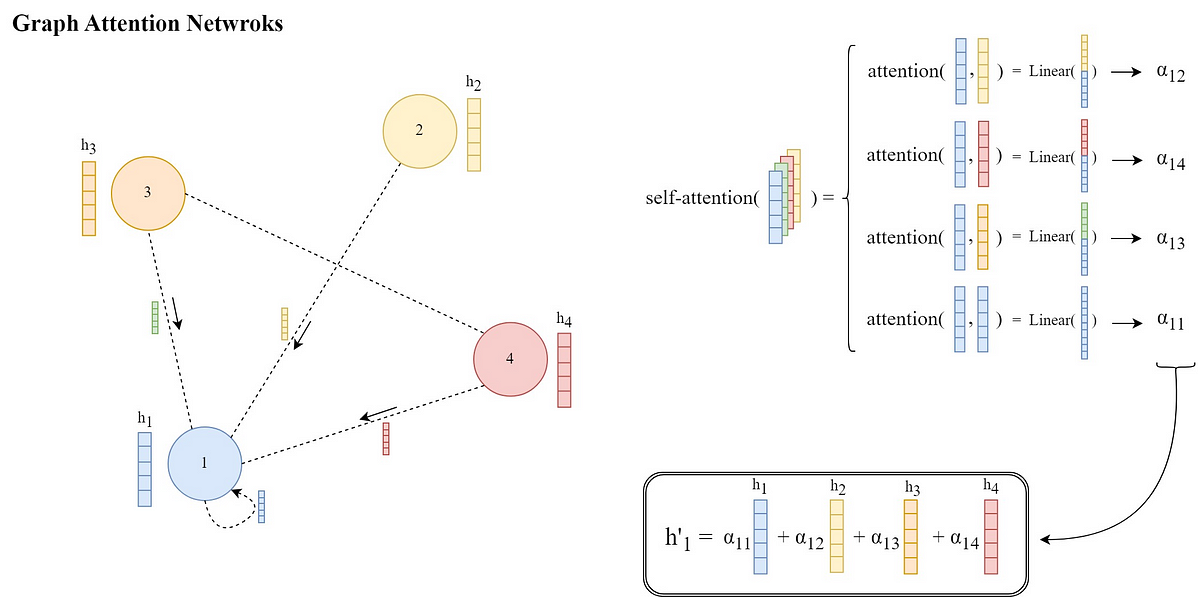
KAISTとLG Researchの研究者グループは、in-context learningを通じて推論中に指示に従う学習(ICIL)が、既存の事前学習モデルや特定の指示に従うように特別に調整されたモデルの両方にとって有利であることを示しています(図1参照)。ICILで使用されるプロンプトには、タスクの教育、入力、出力の各インスタンスである多くのクロスタスクの例が含まれています。デモンストレーションに使用される機能を評価セットから完全に除外し、すべての評価タスクに対して同じ一連のプロンプトを使用するため、ICILはゼロショット学習アプローチです(図2参照)。

彼らは、さまざまなダウンストリームタスクやモデルサイズに適したシンプルなヒューリスティックベースのサンプリング方法を使用して、固定された例セットを作成します。すべてのジョブに対して同じ固定されたデモンストレーションセットを先頭に追加することで、新しいターゲットタスクやモデルのベースラインのゼロショットパフォーマンスを評価および複製することができます。図1は、指示に従うようにfine-tuningされていないさまざまな事前学習済みLLMsのゼロショットチャレンジでの一般化性能を大幅に向上させることを示しています。
- 「スタンフォード大学の新しいAI研究は、言語モデルにおける過信と不確実性の表現の役割を説明します」
- アリババAI研究所が提案する「Composer」は、数十億の(テキスト、画像)ペアで訓練された、巨大な(50億パラメータ)コントロール可能な拡散モデルです
- UCサンディエゴとMeta AIの研究者がMonoNeRFを紹介:カメラエンコーダとデプスエンコーダを通じて、ビデオをカメラ動作とデプスマップに分解するオートエンコーダアーキテクチャ
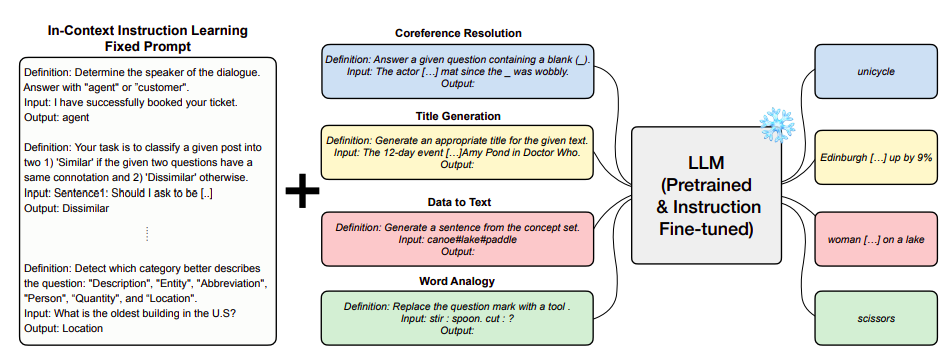
彼らのデータは、指示に明確な応答オプションを備えた分類タスクの選択が、ICILの成功の鍵であることを示しています。重要なことは、ICILを使用した小さいLLMsでも、ICILを使用しない大きな言語モデルよりも優れたパフォーマンスを発揮することです。たとえば、6BサイズのICIL GPT-Jは、175Bサイズの標準的なゼロショットGPT-3 Davinciよりも30以上優れています。さらに、ICILを教示に基づいたfine-tuningされたLLMsに追加することで、特に100B以上の要素を持つモデルに対するゼロショットの指示に従う能力が向上することを示しています。これは、ICILの影響が指示の修正の影響と加算的であることを示唆しています。
これは、以前の研究がfew-shot in-context learningにはターゲットタスクと類似した例を取得する必要があると示唆していたのとは対照的に、生成ターゲットタスクにも当てはまります。さらに驚くべきことに、各例の入力インスタンス分布にランダムなフレーズを代わりに使用しても、パフォーマンスに顕著な影響はありません。このアプローチに基づいて、LLMsは指示中で提供される応答オプションと各デモンストレーションの生成との対応関係を推論中に学ぶため、指示、入力、出力の複雑な関係に依存するのではなく、ICILがLLMsを目標指示に集中させ、目標タスクの応答分布の信号を見つけるのを支援することが目的です。
以下のPaperとGithubをご覧ください。この研究に関するすべてのクレジットは、このプロジェクトの研究者に帰属します。また、最新のAI研究ニュース、クールなAIプロジェクトなどを共有している15k+ ML SubReddit、Discordチャンネル、およびEmailニュースレターにもぜひご参加ください。
この記事は、コンテキスト内の指示学習(ICIL)が、事前学習済みモデルと指示微調整モデルの両方において、ゼロショットタスクの一般化性能を向上させる方法について説明しています。この記事はMarkTechPostに最初に掲載されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「UCバークレーの研究者たちは、Chain of Hindsight(CoH)という新しい技術を提案しましたこれにより、LLMsがあらゆる形式のフィードバックから学び、モデルのパフォーマンスを向上させることが可能となります」
- UC BerkeleyとDeepmindの研究者は、SuccessVQAという成功検出の再構成を提案しましたこれは、Flamingoなどの事前学習済みVLMに適したものです
- スタンフォード大学の研究者が「局所的に条件付けられた拡散(Locally Conditioned Diffusion):拡散モデルを使用した構成的なテキストから画像への生成手法」を紹介しました
- ChatGPTの振る舞いは時間の経過と共に変化していますか?研究者がGPT-3.5とGPT-4の2023年3月版と2023年6月版を4つの異なるタスクについて評価します
- 研究チームがニューロモーフィックコンピューティングを一歩先に進める
- フランス国立科学研究センター(CNRS)におけるAI研究は、ノイズ適応型のインテリジェントプログラマブルメタイメージャーを提案しています:タスク固有のノイズ適応型センシングへの適切なアプローチです
- メリーランド大学の新しいAI研究は、1日で単一のGPU上で言語モデルのトレーニングをするためのクラミングの課題を調査しています