データセットシフトのフレームワークを整理する
整理する
モデル劣化の原因について一歩引いて考える
画像の作成者としてマルコ・ダラ・ヴェッキアとの共同作業
私たちはモデルを訓練し、一連の入力に対して特定の結果を予測するために使用します。それが機械学習のゲームだと私たちは皆知っています。私たちはそれらを訓練することについてかなり詳しく知っています。それはAIという形で進化し、これまでに存在した最高のインテリジェンスになりました。しかし、それらを使用するときにはまだ十分進んでおらず、モデルがデプロイされた後に重要なすべての側面を探求し理解し続けています。
今日は、モデルのパフォーマンスの変化(モデルドリフト)について議論します。モデルのパフォーマンスドリフト(またはモデルの劣化)とは、私たちの機械学習モデルが提供する予測の品質の問題のことです。それがクラスであろうと値であろうと、私たちはその予測と実際のクラスまたは値との間の差を気にします。モデルのパフォーマンスドリフトとは、予測の品質がモデルをデプロイした時点に比べて低下するときに起こります。文献ではこのトピックに関連する他の用語を見つけるかもしれませんが、少なくとも現在の会話の目的のために、モデルのパフォーマンスドリフトまたは単にモデルドリフトに焦点を当ててください。
私たちが知っていること
多くのブログ、書籍、そして多くの論文がモデルドリフトの核心概念を探求し説明していますので、まずはこの現在の状況について入り込みましょう。主に共変量シフト、事前シフト、および条件シフトの概念にアイデアを整理しています。後者は一般的にコンセプトドリフトとも呼ばれます。これらのシフトはモデルドリフトの主な原因であることが知られています(予測の品質の低下を思い出してください)。要約した定義は次のようになります:
- 共変量シフト:P(X)の分布が変化するが、P(Y|X)に変化がないこと。つまり、入力特徴の分布が変化し、そのシフトのいくつかはモデルのドリフトを引き起こす可能性があります。
- 事前シフト:P(Y)の分布が変化すること。ここでは、ラベルまたは数値の出力変数の分布が変化します。出力変数の確率分布が変化する場合、現在のモデルは与えられた予測に対して大きな不確実性を持つため、簡単にドリフトする可能性が高いです。
- 条件シフト(またはコンセプトドリフト):条件付き分布P(Y|X)が変化すること。つまり、特定の入力に対して、出力変数の確率が変化したことを意味します。現時点で私たちが知っている限り、このシフトは通常、予測の品質を維持するための非常に少ない余地を残します。それは本当にそうなのでしょうか?
これらのデータセットのシフトの発生例をリストアップした多くの情報源が存在します。新しいラベルの必要性なしにこれらのシフトを検出するための研究の中核的な機会の1つです[1, 2, 3]。最近、監視のための興味深いメトリックが無監督の方法でモデルの予測パフォーマンスを監視するためにリリースされました[2, 3]。それらは確かにデータの実際の確率分布の変化を非常に正確に反映しており、データセットシフトの異なる概念に基づいています。したがって、これらのシフトの理論について詳しく調べてみましょう。なぜなら、これらの定義についていくつかの秩序を整理できるかもしれないからです。整理することで、もっと簡単に前進したり、このフレームワーク全体をより明確に理解することができるかもしれません。
そのためには、最初に始まりに戻り、物語をゆっくりと導出しましょう。コーヒーを取り、ゆっくり読んで、一緒にいてください。または、ただドリフトしないでください!
実際のモデルと推定モデル
私たちが訓練する機械学習モデルは、ある入力Xを出力Yにマッピングする実際の未知の関係または関数に近づけようとします。私たちは自然に、実際の未知のモデルと推定されるモデルを区別します。ただし、推定モデルは実際の未知のモデルの振る舞いに依存しています。つまり、実際のモデルが変化し、推定モデルがこの変化に対して頑健でない場合、推定モデルの予測はより正確ではなくなります。
私たちが監視できるパフォーマンスは推定関数に関連していますが、モデルドリフトの原因は実際のモデルの変化にあります。
- 実際のモデルとは何ですか? 実際のモデルは、いわゆる条件付き分布P(Y|X)に基づいています。これは、入力が与えられた場合の出力の確率分布です。
- 推定モデルとは何ですか? これは、特定の入力Xに対してP(Y|X=x)の期待値を推定する関数ê(x)です。この関数は私たちの機械学習モデルに接続されています。
以下はこれらの要素の視覚的な表現です:
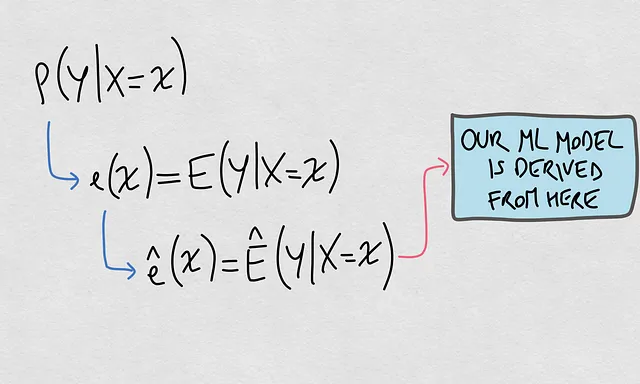
さて、これらの2つの要素を明確にしたので、いわゆるデータセットのシフトの背後にあるアイデアを整理し、それらの概念がどのように関連しているかを説明する準備ができました。
新しい配置
モデルのドリフトのグローバルな原因
私たちの主な目的は、推定モデルのモデルのドリフトの原因を理解することです。すでに推定モデルと条件付き確率分布の関連性を理解しているので、ここで私たちが以前から知っていたことを述べることができます:推定モデルのモデルのドリフトのグローバルな原因は、P(Y|X)の変化です。
基本的で明らかに簡単ですが、私たちが考えている以上に基本的な要素です。推定モデルが実際のモデルをよく反映していると仮定しています。実際のモデルはP(Y|X)によって制御されます。したがって、P(Y|X)が変化すると、推定モデルはおそらくドリフトするでしょう。私たちは、上記の図で示した推論の進み方に注意を払う必要があります。
これは以前から知っていましたので、それについて新しいことは何ですか?新しいことは、私たちがここでP(Y|X)の変化をグローバルな原因として名付けることです。これにより、他の原因との階層関係が形成されます。この階層関係によって、他の原因に関する概念をうまく位置付けることができます。
特定の原因:グローバルな原因の要素
グローバルな原因がP(Y|X)の変化にあることを知っているので、この後のモデルのドリフトの原因について話を続けるために、この後者の確率を構成する要素を探求することは自然なことです。これらの要素を特定したら、モデルのドリフトの原因について話し続けます。では、それらの要素は何ですか?
私たちは常にそれを知っていました。条件付き確率は理論的にP(Y|X) = P(Y, X) / P(X)と定義されます。つまり、周辺確率P(X)で除算された結合確率です。しかし、結合確率をもう一度展開することができ、数世紀前から知っている魔法の式を得ることができます:
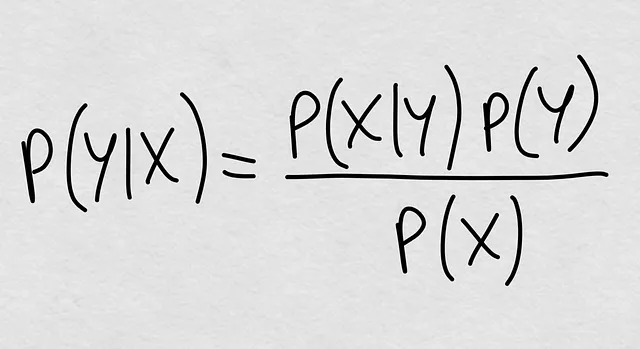
すでに何を見ていますか?条件付き確率は、次の3つの要素によって完全に定義されるものです:
- P(X|Y):逆条件付き確率
- P(Y):事前確率
- P(X):共変量の周辺確率
これらが条件付き確率P(Y|X)を定義する3つの要素であるため、次の文を述べる準備ができました:P(Y|X)が変化する場合、その変化は、P(X|Y)、P(Y)、またはP(X)のいずれかの変化によって定義されます。
それが言われたので、私たちは現在の知識から他の要素を単なるモデルのドリフトの特定の原因ではなく、P(Y|X)と並列の原因として位置付けました。
この投稿の最初に戻ると、共変量シフトと事前シフトを挙げました。したがって、もう1つの特定の原因があることに気づきます:逆条件付き分布P(X|Y)の変化です。一般的には、P(Y)の変化を考える際に、YからXへの逆の関係を考慮しているかのように、この分布についての言及を見つけることがよくあります[1,4]。
新しい概念の階層
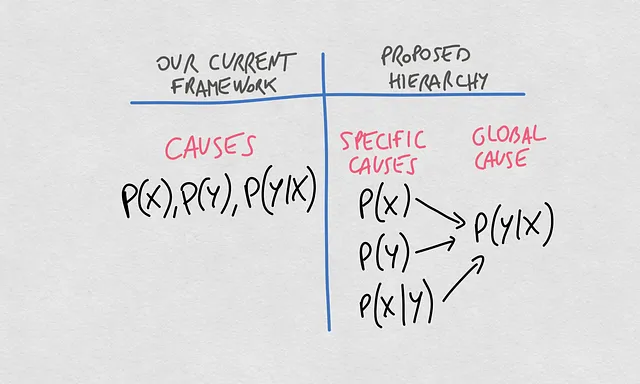
これで、これらの概念に関する現在の考え方と提案された階層との明確な比較ができます。これまでは、異なる確率分布を特定してモデルのドリフトの原因について話してきました。P(X)、P(Y)、P(Y|X)という3つの主要な分布は、私たちの機械学習モデルによって返される予測の品質のドリフトの主な原因とされています。
ここで提案する転換では、概念に階層を与えます。それにより、X -> Yの関係を推定するモデルのドリフトのグローバルな原因は、条件付き確率P(Y|X)の変化です。このP(Y|X)の変化は、P(X)、P(Y)、またはP(X|Y)の変化から生じる可能性があります。
この階層のいくつかの含意をリストアップしましょう:
- P(X)が変化する場合でも、P(Y)およびP(X|Y)がそれに応じて変化する場合、P(Y|X)は変わらない可能性があります。
- P(X)が変化する場合でも、P(Y)またはP(X|Y)がそれに応じて変化しない場合、P(Y|X)は変わる可能性があります。このトピックについて考えたことがある場合、Xが変化し、その変化がY|Xと完全に独立していないように見える場合があることに気付いたかもしれません。したがって、最終的にはY|Xも変化します。ここでは、P(X)がP(Y|X)の変化の具体的な原因であり、それがモデルのドリフトのグローバルな原因です。
- 前述の2つの文は、P(Y)にも当てはまります。
具体的な原因が独立に変化する場合と変化しない場合があるため、P(Y|X)の変化はこれらの具体的な要素の変化によって説明できます。P(X)がここで少し動いて、P(Y)があちらで少し動いたため、これら2つもP(X|Y)を変化させ、最終的にはP(Y|X)を変化させるのです。
P(X)とP(Y|X)は独立に考えるべきではありません。P(X)はP(Y|X)の原因です。
この中で推定されたMLモデルはどこにありますか?
よし、これで、いわゆる共変量シフトと事前シフトは条件付きシフトの原因であることがわかりました。条件付きシフトには、推定モデルの予測性能の低下の具体的な原因のセットが含まれます。しかし、推定モデルは実際には決定境界または関数であり、実際にはプレイしている確率の直接的な推定ではありません。では、原因は実際の決定境界や関数に対して何を意味するのでしょうか?
すべての要素をまとめて、すべての要素をつなげた完全なパスを描いてみましょう:

注意してください、私たちのMLモデルは解析的または数値的に生じる可能性があります。さらに、パラメトリックまたは非パラメトリックな表現として現れることもあります。したがって、最終的には、MLモデルは期待される条件付き値から導くことができる決定境界または回帰関数の推定です。
この事実は、私たちが議論してきた原因に重要な意味を持ちます。P(X)、P(Y)、およびP(X|Y)で起こる変化のほとんどは、P(Y|X)およびE(Y|X)の変化を意味しますが、すべてが実際の決定境界や関数の変化を意味するわけではありません。その場合、推定された決定境界や関数が元々正確な推定であった場合、推定された決定境界や関数は有効なままです。以下はこの例です:
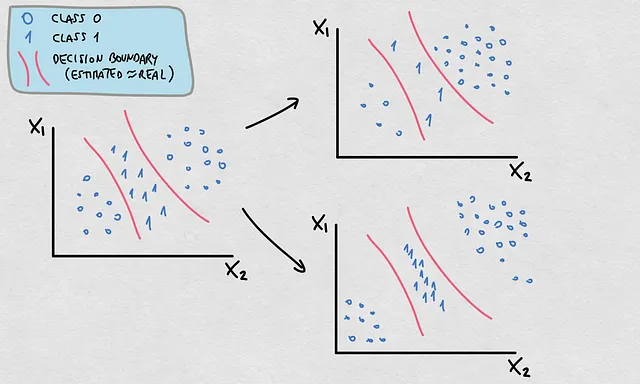
- P(Y)およびP(X)が変化しました。ポイントの密度と位置が異なる確率分布を説明します。
- これらの変化がP(Y|X)を変化させます。
- ただし、決定境界は有効なままです。
ここで重要なポイントがあります。実際のラベルに関する情報なしにP(X)の変化を見ているとしましょう。予測の良さを知りたいです。P(X)が推定された決定境界が不確実性が高い領域にシフトする場合、予測はおそらく不正確です。したがって、決定境界の不確実な領域に共変量シフトが起こっている場合、おそらく条件付きシフトも発生しています。ただし、決定境界が変化しているかどうかはわかりません。その場合、P(X)での変化を量子化することができ、それはP(Y|X)の変化を示す可能性がありますが、決定境界または回帰関数に何が起こっているかはわかりません。以下はこの問題の表現です:

ここまで言ったので、もう一つ述べます。私たちはP(Y|X)の変化を指して条件付きシフトと言います。私たちがコンセプトドリフトと呼んでいるものは、具体的には実際の決定境界または回帰関数の変化を指す可能性があります。下記は、決定境界の変化がある条件付きシフトの典型的な例ですが、共変量や事前シフトはありません。実際、変化は逆の条件付き確率P(X|Y)の変化から来ました。
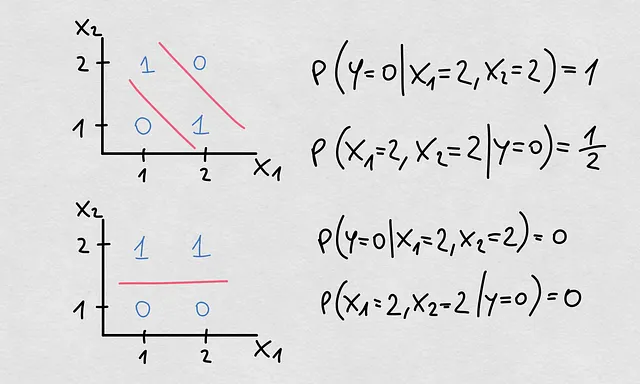
現在のモニタリング方法への影響
これらの原因を理解することで、可能な限り正確にMLモデルのパフォーマンスを監視するための方法を開発することが重要です。提案されたアイデアのいずれも、利用可能な実用的なソリューションにとって悪いニュースではありません。むしろ、この新しい概念の階層により、モデルパフォーマンスの劣化の原因を検出する試みをさらに進めることができるかもしれません。私たちは、モデルの予測パフォーマンスを監視するために提案された方法と指標を持っていますが、ここでリストアップした異なる概念に基づいて主に提案されました。ただし、メトリックの前提条件で概念を混同している可能性があります[2]。例えば、私たちは「条件付きシフトがない」という前提条件を「決定境界の変化がない」と具体的に指しているかもしれません。このことについて考え続ける必要があります。
予測パフォーマンスの劣化についてもっと詳しく
ズームインとズームアウト。私たちは、予測パフォーマンスの劣化の原因について考えるためのフレームワークに潜入しました。しかし、このトピックについて議論するためにはもう一つの次元があります。それは、予測パフォーマンスのシフトのタイプに関するものです。私たちのモデルは、リストアップした原因によって苦しんでおり、それらの原因は異なる形状の予測の不一致として現れます。主に4つのタイプがあります:バイアス、スロープ、バリアンス、非線形シフト。このコインのもう一方について詳しく知りたい場合は、この投稿をチェックしてください。
まとめ
この投稿では、モデルパフォーマンスの劣化の原因を研究し、既知の概念の理論的なつながりに基づいたフレームワークを提案しました。以下は主なポイントです:
- 確率P(Y|X)は実際の決定境界または関数を制御します。
- 推定された決定境界または関数は、実際のものに最も近い近似であると仮定されています。
- 推定された決定境界または関数がMLモデルです。
- MLモデルは予測パフォーマンスの劣化を経験する可能性があります。
- その劣化は、P(Y|X)の変化によるものです。
- P(Y|X)の変化は、少なくとも次の要素のいずれかの変化によるものです:P(X)、P(Y)、またはP(X|Y)。
- 決定境界や回帰関数の変化がなくても、P(X)とP(Y)の変化がある場合があります。
一般的な表現は、「MLモデルがドリフトしている場合、P(Y|X)が変化しています。逆は必ずしも真ではありません。
この概念のフレームワークは、ML予測パフォーマンスの劣化という重要なトピックの種に過ぎないことを願っています。理論的な議論は単なる喜びですが、この関連性が、必要なリソース(サンプルとラベル)の最適化と並行して、実践でこれらの変化を測定するための目標をさらに推進するのに役立つことを信じています。あなたの知識への他の貢献がある場合は、議論に参加してください。
予測パフォーマンスのドリフトの原因は何ですか?
考えるのを楽しんでください!
参考文献
[1] https://huyenchip.com/2022/02/07/data-distribution-shifts-and-monitoring.html
[2] https://www.sciencedirect.com/science/article/pii/S016974392300134X
[3]https://nannyml.readthedocs.io/en/stable/how_it_works/performance_estimation.html#performance-estimation-deep-dive
[4] https://medium.com/towards-data-science/understanding-dataset-shift-f2a5a262a766
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
