数学の効率を高める:Numpy配列操作のナビゲーション
数学の効率を高める:Numpy配列操作のナビゲーション

この記事では、データ分析のための有名で役立つPythonライブラリであるNumPyのパワフルさを紹介します。NumPyでは、要素を格納し、操作を行うための主要なデータ構造は多次元配列です。このダイナミックなライブラリが複雑な数学的なタスクを効率的に処理し、空間および時間の複雑さに関して効率的に処理する方法を見ていきます。また、操作が容易なデータ操作と変換がどのように行われるかも確認します。
NumPyとは何ですか?
NumPy、Scipy、およびMatplotlibは、データサイエンスプロジェクトで使用されるPythonのライブラリで、MATLABのような機能を提供します。

主に、NumPyには以下の特徴があります:
- 型付きの多次元配列(行列)
- 高速な数値計算(行列演算)
- 高レベルの数学関数
NumPyは、高性能な計算とデータ分析に必要な基本的なパッケージであり、Pythonで数値計算を行うために必要です。大きなデータ配列に対して効率的に設計されているため、Pythonでの数値計算にはNumPyが必要です。
NumPy配列を作成するさまざまな方法
NumPy配列で操作を行う前に、最初の目標は、問題の要件に基づいてNumPy配列を効率的に作成することです。
NumPy配列を作成するための複数の方法があります。いくつかの標準的で実用的な方法を以下に示します:
Case-1: np.onesメソッドを使用して1の配列を作成する場合:
「1」の配列を作成する必要がある場合は、このメソッドを利用できます。
np.ones((3,5), dtype=np.float32)
# 出力
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
Case-2: np.zerosメソッドを使用して0の配列を作成する場合:
「0」の配列を作成する必要がある場合は、このメソッドを利用できます。
np.zeros((6,2), dtype=np.int8)
# 出力
[[0 0]
[0 0]
[0 0]
[0 0]
[0 0]
[0 0]]
Case-3: np.arangeメソッドを使用する場合:
シーケンスに従って要素の配列を作成する必要がある場合は、このメソッドを利用できます。
np.arange(1334,1338)
# 出力
[1334 1335 1336 1337]
Case-4: np.concatenateメソッドを使用する場合:
必要な配列が1つ以上の配列を組み合わせる場合に適しています。
A = np.ones((2,3))
B = np.zeros((4,3))
C = np.concatenate([A, B])
# 出力
[[1. 1. 1.]
[1. 1. 1.]
[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
Case-5: np.random.randomメソッドを使用する場合:
ランダムな値で配列を作成する場合に便利です。
np.random.random((2,3))
# 出力
[[0.30512345 0.10055724 0.89505387]
[0.36219316 0.593805 0.7643694 ]]
NumPy配列の操作
例を使用してNumPy配列の基本的な特性について説明しましょう:
コード:
a = numpy.array([[1,2,3],[4,5,6]],dtype=numpy.float32)
# 配列の次元、形状、およびデータ型
print (a.ndim, a.shape, a.dtype)
出力:
2 (2, 3) float32
上記のコードに基づいて、以下のポイントを結論として覚えておく必要があります:
- 配列は、スカラー値に対応するゼロを含む、正の整数として任意の次元を持つことができます。
- 配列は型付けされており、np.uint8、np.int64、np.float32、np.float64などのデータ型を持つことができます。
- 配列は密です。配列の各要素は存在し、同じ型を持ちます。
コード:
# 配列の再形成
a = numpy.array([1,2,3,4,5,6])
a = a.reshape(3,2)
#出力:
[[1 2]
[3 4]
[5 6]]
a = a.reshape(2,-1)
#出力:
[[1 2 3]
[4 5 6]]
a = a.ravel()
#出力:
[1 2 3 4 5 6]
覚えておく重要なポイント:
- 再形成操作後、配列の要素の総数は変更できません。
- 軸の形状を推測するには、-1を使用します。
- デフォルトでは、要素は行優先の形式で格納されますが、MATLABでは列優先です。
Numpy配列のブロードキャスト
ブロードキャストは、互換性がある限り、異なる形状の配列に対して操作を実行できるようにします。配列の小さい次元は、仮想的に大きい配列の次元に合わせるために拡張されます。
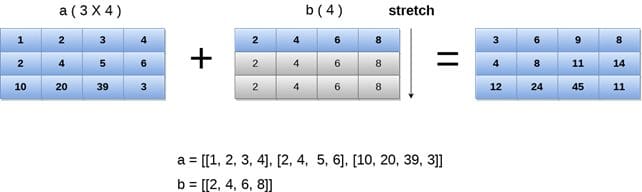
コード:
# 配列のブロードキャスト
a = numpy.array([[1, 2], [3, 4], [5, 6]])
b = numpy.array([10, 20])
c = a + b # 'b'配列を'a'の次元に合わせてブロードキャスト
この例では、2次元のNumPy配列’a’の次元(3, 2)と、形状(2)の1次元配列’b’が関与しています。ブロードキャストにより、操作’a + b’は、’b’を2番目の次元で’a’と仮想的に拡張し、’a’と拡張された’b’との要素ごとの加算を行います。
配列のインデックスとスライシング
- スライスはビューです。スライスへの書き込みは元の配列を上書きします。
- リストまたはブール配列もインデックスに使用できます。
- Pythonのインデックスの構文:
start_index : stop_index: step_size
コード:
a = list(range(10))
# 最初の3つの要素
a[:3] # インデックス0、1、2
# 最後の3つの要素
a[-3:] # インデックス7、8、9
# インデックス3、5、7
a[3:8:2]
# インデックス4、3、2(これはトリッキーです)
a[4:1:-1]
画像は多次元配列としても視覚化できることをご存知かと思います。そのため、スライシングは画像上でいくつかの数学的な操作を実行するのにも役立ちます。重要な高度な例をいくつか紹介しますので、理解を深めるために参考にしてください:
# 境界以外のすべてを選択
pixel_matrix[1:-1,1:-1]
# チャネルの順序を交換
pixel_matrix = pixel_matrix[:,:,::-1]
# ダークピクセルを黒に設定する
pixel_matrix[pixel_matrix<10] = 0
# 2行目と4行目を選択
pixel_matrix[[1,3], :]
配列の集約と縮小
さて、numpy配列に対する集約操作から始めましょう。一般的に実行できる操作は次のとおりです:
- 配列のすべての要素の合計と積を求める。
- 配列中の最大および最小要素を求める
- 配列中の特定の要素の数を見つける
- 行列式、トレース、固有値および固有ベクトルなどを含む線形代数モジュールを使用して、他のパラメータも見つけることができます。
各機能について例を挙げて議論を始めましょう:
Case-1: 配列内のすべての要素の代数的合計
array_1 = numpy.array([[1,2,3], [4,5,6]])
print(array_1.sum())
#出力:
21
Case-2: 配列内の最大要素
array_1 = numpy.array([[1,2,3], [4,5,6]])
print(array_1.max())
#出力:
6
Case-3: 配列内の最小要素
array_1 = numpy.array([[1,2,3], [4,5,6]])
print(array_1.min())
#出力:
1
Case-4: 配列内の最大要素が存在する場所の位置/インデックス
array_1 = numpy.array([[1,2,3], [4,5,6]])
print(array_1.argmax())
#出力:
5
Case-5: 配列内の最小要素が存在する場所の位置/インデックス
array_1 = numpy.array([[1,2,3], [4,5,6]])
print(array_1.argmin())
#出力:
0
位置を見つける際に、多次元配列を1次元配列として考慮し、それから計算することがわかります。
Case-6: 配列内のすべての要素の平均値
array_1 = numpy.array([[1,2,3], [4,5,6]])
print(array_1.mean())
#出力:
3.5
Case-7: 2つの多次元配列の内積/スカラー積
array_1 = numpy.array([[1,2], [4,5]])
array_2 = numpy.array([[1,-1,2], [3,7,-2]])
t = array_1.dot(array_2)
print(t)
#出力:
[[ 7 13 -2]
[19 31 -2]]
NumPy配列のベクトル化
ベクトル化は、個々の要素をループ処理する代わりに、配列全体に対して操作を実行することを可能にします。最適化された低レベルのルーチンを利用して、より高速で簡潔なコードを実現します。
コード:
a = numpy.array([1, 2, 3, 4, 5])
b = numpy.array([10, 20, 30, 40, 50])
c = a + b # 明示的なループなしで要素ごとの加算
上記の例に基づいて、’a’と’b’という2つのNumPy配列が作成されていることがわかります。ベクトル化の概念を使用して配列間で要素ごとの加算を行っている ‘a + b’ の操作を実行する際に、新しい配列 ‘c’ が作成され、’a’ と ‘b’ の対応する要素の合計が含まれています。そのため、要素ごとの操作により、明示的なループを実行せず、効率的な計算のために最適化されたルーチンを利用しています。
配列の連結
Case-1: 連結関数を使用して2つ以上の配列を連結する場合、配列のタプルを結合する必要があります。
コード:
# 行方向に2つ以上の配列を連結する
numpy_array_1 = numpy.array([1,2,3])
numpy_array_2 = numpy.array([4,5,6])
numpy_array_3 = numpy.array([7,8,9])
array_concatenate = numpy.concatenate((numpy_array_1, numpy_array_2, numpy_array_3))
print(array_concatenate)
#出力:
[1 2 3 4 5 6 7 8 9]
Case 2: 1つ以上の次元を持つ配列を連結する場合は、連結する軸を指定する必要があります。そうしない場合、最初の次元に沿って連結が行われます。
コード:
# concatenate関数を使用して2つ以上の配列を列方向に連結する
array_1 = numpy.array([[1,2,3], [4,5,6]])
array_2 = numpy.array([[7,8,9], [10, 11, 12]])
array_concatenate = numpy.concatenate((array_1, array_2), axis=1)
print(array_concatenate)
#出力:
[[ 1 2 3 7 8 9]
[ 4 5 6 10 11 12]]
数学関数とユニバーサル関数
これらのユニバーサル関数は、ufuncsとも呼ばれます。これらの関数では要素ごとの操作が行われます。例えば:
- np.exp
- np.sqrt
- np.sin
- np.cos
- np.isnan
コード:
A = np.array([1,4,9,16,25])
B = np.sqrt(A)
#出力
[1. 2. 3. 4. 5.]
パフォーマンス比較
数値計算を行う際、Pythonは大きな計算を行う場合には時間がかかります。例えば、1000 x 1000の行列の掛け算を行う場合、PythonとNumPyの所要時間は以下の通りです:
- Pythonのトリプルループは10分以上かかる
- NumPyは約0.03秒かかる
したがって、上記の例からわかるように、NumPyは標準のPythonよりもはるかに少ない時間を要するため、データサイエンスに関連する実生活のプロジェクトでは、大量のデータを処理する際のレイテンシが低下します。
まとめ
この記事では、NumPy配列について説明しました。セッションをまとめると、NumPyの利点は以下の通りです:
- NumPyは配列指向の計算を持っています。
- NumPyは効率的に実装された多次元配列を持っています。
- NumPyは主に科学計算のために設計されています。
- NumPyにはループなしで配列の高速な計算を行うための標準的な数学関数が含まれています。
- NumPyには組み込みの線形代数および乱数生成モジュールがあり、フーリエ変換の機能もあります。
- NumPyには、配列の読み書きやメモリマップされたファイルの操作に使用するツールも含まれています。
Aryan Gargさんは、B.Tech.の電気工学の学生で、現在は学部の最終年に在籍しています。彼の興味はWeb開発と機械学習の分野にあります。彼はこの興味を追求し、これらの方向でさらに活動することを熱望しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






