教師なしの深層学習により、単一の下側頭顔パッチニューロンにおいて意味的な分離が特定される
'教師なしの深層学習により、下側頭顔パッチニューロンで意味的な分離が特定される'
私たちの脳は視覚情報を処理する驚くべき能力を持っています。複雑なシーンを一目見ただけで、数ミリ秒以内にオブジェクトとその属性(色やサイズなど)に分割し、この情報を使ってシーンを簡単な言語で説明することができます。この見かけ上の容易さの背後には、視覚皮質によって行われる複雑な計算があります。この計算では、視網膜から送られてくる数百万の神経パルスを取り込み、より意味のある形に変換して、簡単な言語の説明にマッピングする必要があります。脳の中でこのプロセスがどのように機能するのかを完全に理解するためには、視覚処理の階層の終わりでニューロンの発火を介して意味のある情報がどのように表現されるか、およびそのような表現が主に教えられていない経験から学習される可能性があるかを解明する必要があります。
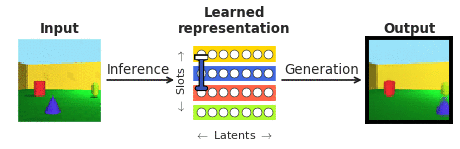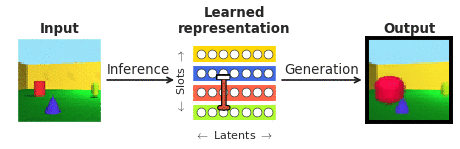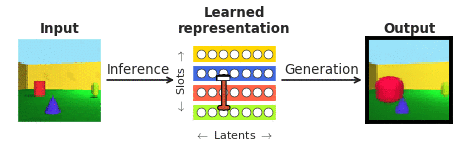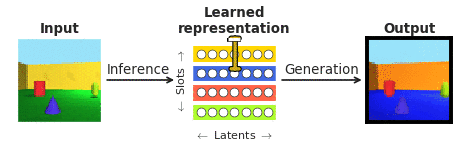
顔の知覚の文脈でこれらの問いに答えるために、私たちはカリフォルニア工科大学(ドリス・ツァオ)と中国科学院(レチャン)の共同研究者と協力しました。顔は神経科学のコミュニティでよく研究されており、「物体認識の縮図」とも言われています。特に、私たちは、視覚処理の階層の終わりにある顔パッチの単一の皮質ニューロンの応答と、通常の「ブラックボックス」システムとは異なり、人間に解釈可能であることを明示的に目指した最近登場した「disentangling」ディープニューラルネットワークとの応答を比較したかったのです。「disentangling」ニューラルネットワークは、複雑な画像を内部ニューロン(潜在ユニットと呼ばれる)の少数にマッピングすることを学習します。各潜在ユニットは、オブジェクトの色やサイズなど、シーンの1つの意味のある属性を表現することを学習します(図1参照)。バイオロジカルに非現実的な量の外部監視を通じて視覚オブジェクトを認識するために訓練された「ブラックボックス」ディープクラシファイアとは異なり、このようなdisentanglingモデルは外部の教示信号なしで訓練され、入力画像(図1の生成)を学習した潜在表現(図1の推論を通じて取得)から再構築するという自己教示目標を持っています。
disentanglingは、ほぼ10年前から機械学習コミュニティで重要な要素として考えられており、よりデータ効率の良い、転移可能な、公正な、想像力のある人工知能システムの構築に不可欠です。しかし、長年にわたり、実際にdisentangleできるモデルを構築することはこの分野では難しいと考えられてきました。β-VAEと呼ばれる最初のモデルは、この問題を成功裏にかつ堅牢に解決できるようになりました。β-VAEは神経科学からのインスピレーションを受けて開発されました。β-VAEは自分自身の入力を予測することで学習します。成功した学習には、赤ちゃんが遭遇するような同様の視覚的な経験が必要です。また、学習された潜在表現は、視覚脳の既知の特性と類似しています。
私たちの新しい論文では、顔の画像データセットでトレーニングされたβ-VAEによって発見されたdisentangledユニットが、同じ顔を見ている霊長類の実際の単一ニューロンの応答とどの程度似ているかを測定しました。神経データは、カリフォルニア工科大学の動物ケアおよび使用委員会の厳格な監視のもとで共同研究者によって収集されました。比較を行った結果、β-VAEによって発見されたわずか数のdisentangledユニットは、実際のニューロンの同等のサイズのサブセットと同等の振る舞いをしているようでした。さらに詳しく調べると、実際のニューロンと人工ニューロンの間に強力な1対1のマッピングが存在することがわかりました(図2参照)。このマッピングは、視覚処理の最先端の計算モデルとされる深層クラシファイアや、神経科学コミュニティの「ゴールドスタンダード」と見なされる手作りの顔認識モデルを含む他のモデルに比べてもはるかに強力でした。さらに、β-VAEユニットは年齢、性別、目のサイズ、微笑みの存在など、意味のある情報をエンコードしており、脳の単一のニューロンが顔を表現するためにどの属性を使用しているかを理解することができました。
.jpg)
もしβ-VAEが実際に顔の画像に対して反応する点で、実際のニューロンと同等の人工的な潜在単位を自動的に発見できたのであれば、実際のニューロンの活動を対応する人工的なニューロンに変換し、訓練されたβ-VAEの生成器(図1を参照)を使用して実際のニューロンが表現している顔を可視化することが可能であるはずです。これをテストするために、モデルがまだ経験していない新しい顔の画像を霊長類に提示し、β-VAEの生成器(図3を参照)を使用して再現できるかどうかを確認しました。これが実際に可能であることがわかりました。わずか12個のニューロンの活動を使用して、他の深層生成モデルよりもオリジナルの再構築や視覚的な品質の面でより正確な顔の画像を生成することができました。これは、代替モデルが一般的にβ-VAEよりも優れた画像生成器であるという事実にもかかわらずです。
.jpg)
新しい論文でまとめられた私たちの研究結果は、視覚脳が処理階層の最後でさえも単一のニューロンのレベルで理解できることを示唆しています。これは、多くのニューロン間で意味のある情報が多重化され、個々のニューロンは大部分が解釈不可能であるという一般的な信念とは異なります。これは、ディープクラシファイアの全層を介して情報がエンコードされるのと似ています。さらに、私たちの研究結果は、脳が解離表現学習の最適化を通じて視覚知覚を行うための能力をサポートするために学習する可能性があることを示唆しています。β-VAEは元々高度な神経科学の原則に触発されて開発されましたが、解離表現の有用性はこれまでに主に機械学習コミュニティで示されてきました。神経科学と機械学習の相互に有益な相互作用の豊かな歴史に沿って、最新の機械学習の知見が神経科学コミュニティにフィードバックされ、解離表現が生物学的システムの知能をサポートするための根拠として、抽象的な推論や汎用的かつ効率的なタスク学習の基盤としての価値を調査することを望んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






