『思考の整理、早くて遅い+AI』
思考の整理、早くて遅い+AI
AIが人間の心理を利用して数学を修正する

「人間の脳には、悪いニュースに優先順位を与える仕組みがあります。」- Daniel Kahneman
「思考、早くて遅い」は、心理学者でノーベル賞受賞者であるダニエル・カーネマンによるニューヨーク・タイムズのベストセラー本です。この本では、彼の思考の駆動力についての仮説が紹介されています。
彼のこの仮説は、GoogleのBardなどのAIチャットボットによって、より効率的かつ正確になるために活用されています。
しかし、具体的には、ダニエル・カーネマンの本にカバーされた仮説が、どのようにAIチャットボットの開発に役立つのでしょうか?
それについて、この投稿で話すことにします。
思考を駆動する2つのシステム

カーネマンの本では、2つの思考システムが探求されています。
- 直感的思考(システム1思考とも呼ばれる)
- 遅い思考(システム2思考とも呼ばれる)
カーネマンによれば、システム1は速く、本能的で感情的な思考です。一方、システム2は遅く、熟考的で論理的な思考です。両方のシステムが意思決定に重要な役割を果たしますが、状況によっては片方のシステムがもう一方よりも活発になることがあります。
システム1は素早く効率的に作動します。このシステムの下では、意志的な制御の感覚を持たず、ほとんど努力を要しません。
これには、ポスターの上の単語を読む、他のオブジェクトに比べて物が遠いか近いかを検出する、聞こえる音を識別するなどのアクションが含まれます。
一方、システム2はより意識的で論理的です。このシステムの下でのアクションには時間がかかり、意志的な制御があります。このシステムは抽象的かつ論理的な思考を行うときに活性化します。
これには、人混みの中で誰かを識別する、頭の中で長い計算をする、チェスをするなどのアクションが含まれます。
最近、この2つのシステムの概念がGoogleのAIチャットボットであるBardによって、数学や文字列の操作を改善するために使用され、その応答をより動的かつ正確にしています。
しかし、Bardはこの心理学的な概念を自身のAIシステムの向上にどのように活用しているのでしょうか?
思考の原理がAIにどのように役立つか
まずは、それぞれのシステムの主な利点と欠点を理解しましょう。
この本では、システム1思考が私たちの思考の98%を担当している一方、システム2思考は残りの2%を担当しており、システム1に従属しています。
しかし、両方のシステムには利点と欠点があり、それは私たちの意思決定能力に大きな影響を与えます。
各システムの欠点
システム1思考に過度に依存することは、偏見やミスを引き起こす可能性があります。システム1思考のいくつかの注意点は次のとおりです:
- 確証バイアスの過度の傾斜
- 具体的で重要な詳細を見落とす傾向
- 嫌いな証拠を無視し、無知につながる
- 簡単なまたは関係のない意思決定について過剰に考えること
- 悪い意思決定のための疑問のある正当化を生み出すこと
などです。
こんにちは、読者の皆さん!この記事を楽しんでいただければ幸いです。この記事は私の「Creative Block」ニュースレターの一部です- TechとAIに関する週刊ニュースレターです。
このようなコンテンツをもっと読みたい場合は、Creative Blockにアクセスしてください。
一方で、System 2の思考に過度に依存することは、誤りやネガティブな結果につながることもあります。これには以下のようなことが含まれます:
- 単純な意思決定について過度に考えすぎて、大量の時間を浪費すること
- 迅速な意思決定ができないこと
- 懐疑的すぎて判断を控えすぎること
- 意思決定の疲労や認知の過負荷
- 論理的すぎて感情を考慮しない意思決定をすること
2つの思考システム:AIへの応用
これは人間の領域では高度に心理的なものですが、この概念がAIとコンピューティングに応用されると非常に興味深いことが起こります。
LLMs(BardやCHatGPTなどのチャットボットにパワーを与えるAIモデル)は、System 1で実行されていると考えることができます。
どのようにして?
LLMs(これらのチャットボットを実行するAIモデル)は、トレーニングされた数十億のデータの中でパターンを見つけ、共通のパターンに一致する応答を生成することで動作します。例えば、チャットボットに「気候変動についてのエッセイを書いて」と言った場合、バックエンドでのプロセスは次のようになります:
- 広範なトレーニングデータベースの中で一致するクエリを見つける。チャットボットは、キーワード「気候変動」と「エッセイ」を含む一般的なクエリを見つけようとします。
- 傾向やパターンを見つける。その後、チャットボットは選択されたすべてのデータの間で共通の傾向やパターンを見つけようとします。例えば、ほとんどのデータが「炭素排出量」、「炭素フットプリント」、「プラスチックの汚染」、「地球温暖化」といったキーワードを含むというパターンがあるかもしれません。さらに、エッセイのタイトルと段落の形式自体もパターンです(詩やブログなどの他の形式とは対照的です)。
- パターンに基づいたテキストを生成する。これは楽しい部分です。このプロセスをパズルを解くことに例えることができます。ボットは、データの断片(パズルのピース)を使用してテキストを生成し、類似のエッセイのパターン(最終的な絵)に似せようとします。これには、与えられたプロンプトの複数のイテレーション(出力)を作成し、それを既に書かれた気候変動に関するエッセイなどの参照データと比較します。
- 出力を提供する。望ましい結果に近いイテレーションが選択され、画面に表示されます。
このプロセスは長く見えるかもしれませんが、従来のLLMsではわずか数秒で実行されます。1番目のステップは、LLMsの開発とトレーニングのフェーズで事前に行われており、AIモデルが数十億のデータを含むデータセットでトレーニングされていることを意味します。この膨大なデータセットから学習し、それらすべての中でパターンを見つけた後、LLMプロセスの大部分が完了します。
残りのステップは比較的迅速であり、モデルのトレーニングに供給されたデータの品質に大きく依存します。一般的に、提供されるトレーニングデータがより優れているほど、予測と生成の品質も向上します。
したがって、LLMはあまり「考えずに」テキストを生成します。単にパターンを見つけ、出力を参照データと比較するだけです。
したがって、LLMsはSystem 1に属します — つまり、素早く効率的です。ただし、これにはLLMsが不正確なバイアスのある出力を生成したり、独自の事実や数字を作り出す(AIの幻覚)といった欠点があります。
これが次のケースの理由であり、たとえばBardが難しいプロンプトに対して楽に結果を示す一方で、以下のような簡単なタスクでは惨憺たる結果を示す理由です:
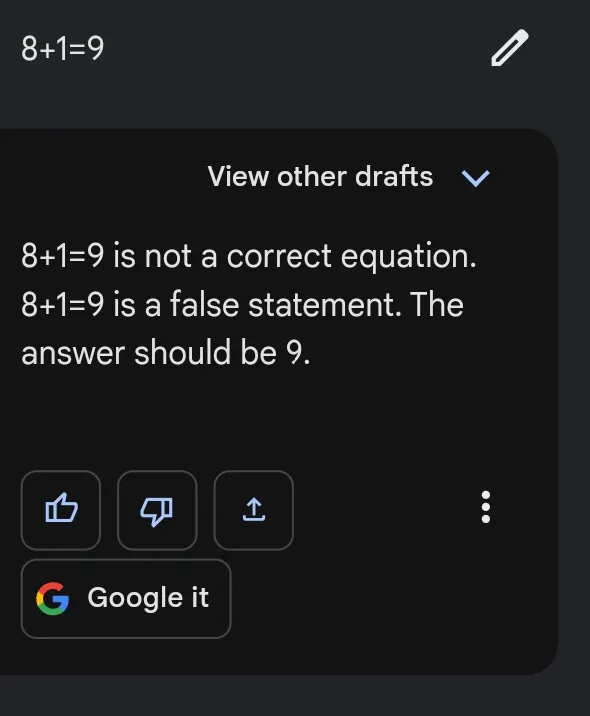
これは特定の数学の問題を解く際に、類似した数学の問題の「パターン」に頼るよりも、特定の手順の順序に従うことが効率的なためです。
これが従来のコンピューティングがより優れて機能する理由です。たとえば、コンピュータ内の電卓の働き方などです。
従来のコンピューティングは、コードや単純なアルゴリズムの形で、シーケンスや構造に従います。この点において、従来のコンピューティングは、数学の問題を解く、文字列の操作を行う、変換を行うなどのタスクを行うために好まれます。欠点は、指定されたフォーマットに従うため、必ずしも高速または効率的ではないことが多いということです。従来のコンピュータは、12 * 24 = 288のような質問の答えを見つけることができますが、微積分に関連する質問には時間がかかります。
しかしここでのプラスポイントは、ほとんどの場合正しい答えを得ることがほぼ確実であるということです。
従来のコンピューティングは、LLMと比較すると、比較的遅く、より論理的で構造化されています。
したがって、従来の計算はシステム2に属します。それは比較的遅く、はるかに体系的で論理的です。アルゴリズム、コード、または他のハードコードされた実行システムから構成されています。
GoogleのBardは、興味深いことに、両方のシステムを使用して、チャットボットの応答を最適化しようとしています。
Bardはどのように使用するのか

Bardは、ローンチ時に苦しんだことがありました。Bardの能力を紹介した最初のプロモーションビデオは、情報の不正確さを含む応答が批判を浴びました。
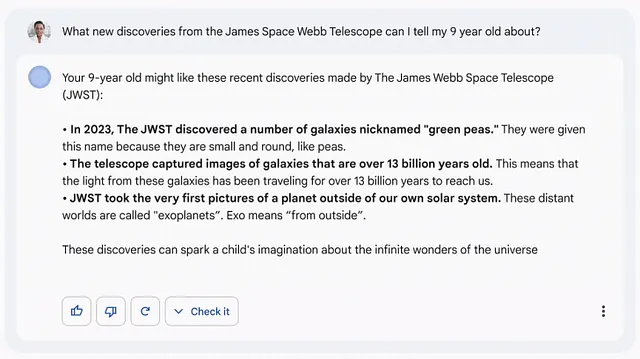

そのため、BardはAIボットをより正確にし、バイアスや誤情報を減らすことが重要でした。これは、ほぼすべてのAIツールで誤情報を減らし、効率を向上させるという難しい目標です。
したがって、Googleは6月7日に「Bardは論理と推論能力を向上させています」というタイトルのブログを公開しました。
このブログでは、Bardの2つの新機能が強調されています。
そのうちの1つは、Google Sheetsへのエクスポート機能であり、ユーザーはテーブルを含む出力をGoogle Sheetsにエクスポートすることができます。
もう1つの機能は、Bardが「数学の問題、コーディングの質問、文字列の操作においてより優れる」と述べたものです。
Bardは以前、数学の問題に苦労しており、今でも時々苦労しています。しかし、上記で説明した2つのシステムを組み合わせるアプローチを使用することで、Bardは今後改善し、ばかげた数学のエラーを修正することを目指しています。
Bardが使用するこの新しい技術は、「暗黙のコード実行」と呼ばれています。
LLM(高速かつパターンベースの応答からなるシステム1)がプロンプトを受け取るのに対して、暗黙のコード実行によりBardは計算のプロンプト(論理的で体系的な実行からなるシステム2)を検出し、バックグラウンドでコードを実行することができます。
これにより、Bardは数学的および文字列ベースのプロンプトに対してより簡単に応答することができます。
ブログで言及された例では、GoogleはBardが次のようなプロンプトに対して改善すると述べています:
- 15683615の素因数は何ですか?
- 貯金の成長率を計算してください
- 単語「Lollipop」を逆にしてください
ブログから抜粋した以下の内容は、このアプローチ(2つの思考システムを使用するアプローチ)の本質と動機を捉えています-
「その結果、彼らは言語と創造的なタスクに非常に適していますが、推論や数学などの領域では弱いです。
高度な推論と論理能力を持つより複雑な問題を解決するために、LLMの出力だけに頼るだけでは十分ではありません。
LLMは純粋にシステム1で動作すると考えることができます-テキストを迅速に生成しますが、深い思考はありません…従来の計算はシステム2の思考と密接に関連しています。それは公式的で柔軟ではありませんが、適切な手順のシーケンスで長除法の解決策などの印象的な結果を生み出すことができます。」
— Googleのブログより
LLMsと従来のコンピューティングをそれぞれシステム1とシステム2に保つこのアプローチにより、応答はより正確で効率的になります。
このアプローチを使用することで、ブログによれば、Bardは単語や数学の問題に対して約30%の正確さを示しました。
この新しいアプローチの信頼性はどの程度ですか

これにより、数学やワード問題に対するBardの精度が向上しますが、チャットボットを効率的にするための最善の方法ではないかもしれません。
数学やワード問題に取り組む際には、かなりの精度を示していますが、コードに関連する問題に取り組む際にはまだ苦労しています。
これらの改善にもかかわらず、Bardは常に正確な結果を得るわけではありません。たとえば、Bardはプロンプトの応答を支援するためのコードを生成しないかもしれませんし、生成されるコードが間違っている場合もありますし、Bardは実行されたコードを応答に含めないかもしれません。
Googleはブログの最後で述べています。
したがって、これは重要な変更ですが、Bardは完全に信頼性があるためにはまだ長い道のりを歩まなければなりません。
誤情報を減らし、効率を向上させることは、ほぼすべてのチャットボットにとっての課題です。
進歩は進んでいますが、まだまだ道のりは長いです。
今日は以上です。この投稿が役に立ったことを願っています。
次の投稿でお会いしましょう👋
テック、サイエンス、AIの最新のイベントを追いかけることに興味はありますか?
それなら、私の無料の週刊ニュースレターをsubstackでお見逃しなく。テックとAIに関連する洞察、ニュース、分析を共有しています。
Creative Block | Aditya Anil | Substack
AI、テクノロジー、サイエンスに関する週刊ニュースレターがあなたに関連するものであることをクリックして確認してください。 Creative Block by Aditya…
creativeblock.substack.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






